5 Steps to a 5: AP Biology 2017 (2016)
STEP 4
Review the Knowledge You Need to Score High
CHAPTER 11
Molecular Genetics
IN THIS CHAPTER
Summary: This chapter describes the various processes in cells that take DNA from gene to protein: replication, transcription, posttranscriptional modification, and translation. It also discusses the regulation of these processes before concluding with a discussion about viruses, bacteria, and genetic engineering.

Key Ideas
![]() DNA: adenine-thymine, cytosine-guanine—arranged in a double helix.
DNA: adenine-thymine, cytosine-guanine—arranged in a double helix.
![]() RNA: adenine-uracil, cytosine-guanine—single stranded.
RNA: adenine-uracil, cytosine-guanine—single stranded.
![]() DNA replication occurs during the S-phase in a semi-conservative fashion and in a 5’ to 3’ direction.
DNA replication occurs during the S-phase in a semi-conservative fashion and in a 5’ to 3’ direction.
![]() Types of DNA replication mutations: frameshift, missense, nonsense.
Types of DNA replication mutations: frameshift, missense, nonsense.
![]() Transcription: mRNA is formed from a DNA template.
Transcription: mRNA is formed from a DNA template.
![]() Translation: process by which mRNA specified sequence of amino acids is lined up on a ribosome for protein synthesis.
Translation: process by which mRNA specified sequence of amino acids is lined up on a ribosome for protein synthesis.
![]() Operons act as on-off switches for transcription—allow for production of genes only when needed.
Operons act as on-off switches for transcription—allow for production of genes only when needed.
![]() Types of genetic recombination: transformation, transduction, and conjugation.
Types of genetic recombination: transformation, transduction, and conjugation.
Introduction
Genetics has implications for all of biology. We begin our study of this subject with an introduction to DNA and RNA, followed by a description of the various processes in cells that take DNA from gene to protein: replication, transcription, posttranscriptional modification, translation, and the regulation of all these processes. The genetics of viruses and bacteria follows, and the chapter concludes with a discussion of genetic engineering.
DNA Structure and Function
BIG IDEA 3.A.1
DNA (and sometimes RNA) is the primary source of heritable information .
Deoxyribonucleic acid, known to her peers as DNA, is composed of four nitrogenous bases: adenine, guanine, cytosine, and thymine. Adenine and guanine are a type of nitrogenous base called a purine, and contain a double-ring structure. Thymine and cytosine are a type of nitrogenous base called a pyrimidine, and contain a single-ring structure. Two scientists, James D. Watson and Francis H.C. Crick, spent a good amount of time devoted to determining the structure of DNA. Their efforts paid off, and they were the ones given credit for realizing that DNA was arranged in what they termed a double helix composed of two strands of nucleotides held together by hydrogen bonds. They noted that adenine always pairs with thymine (A=T) held together by two hydrogen bonds and that guanine always pairs with cytosine (C≡G) held together by three hydrogen bonds. Each strand of DNA consists of a sugar-phosphate backbone that keeps the nucleotides connected with the strand. The sugar is deoxyribose. (See Figure 11.1 for a rough sketch of what purine–pyrimidine bonds look like.)
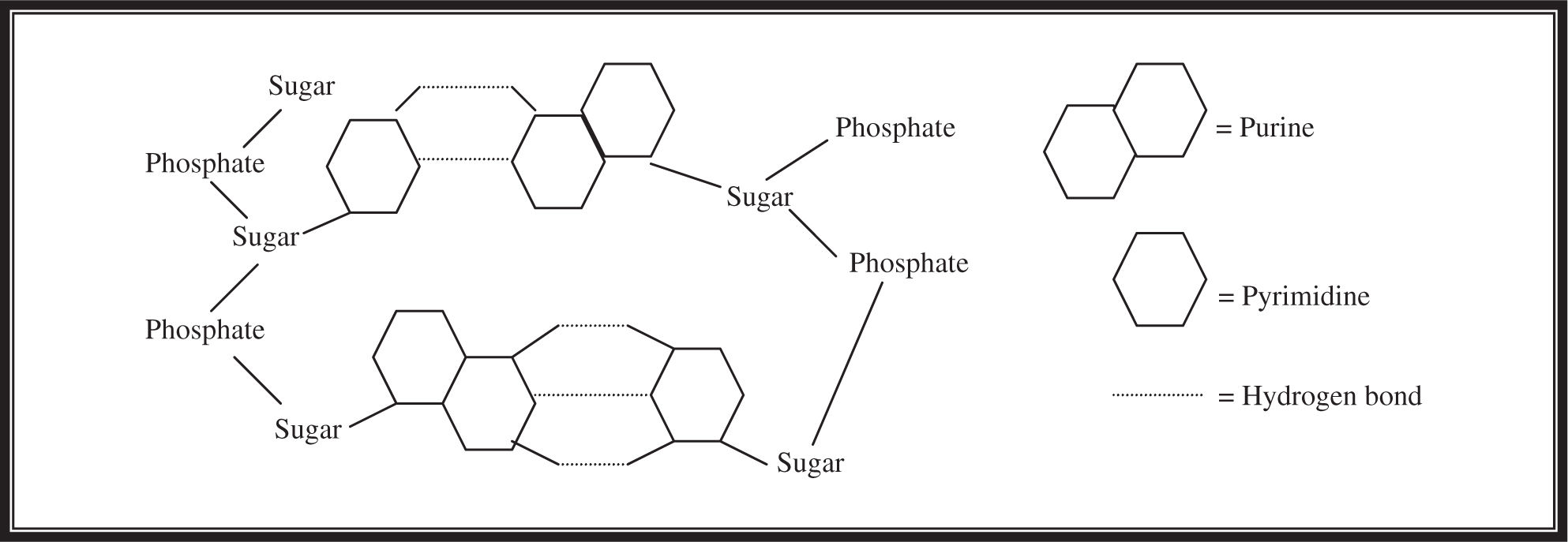
Figure 11.1 Purine–pyrimidine bonds.
One last structural note about DNA that can be confusing is that DNA has something called a 5′ end and a 3′ end (Figure 11.2 ). The two strands of a DNA molecule run antiparallel to each other; the 5′ end of one molecule is paired with the 3′ end of the other molecule, and vice versa.
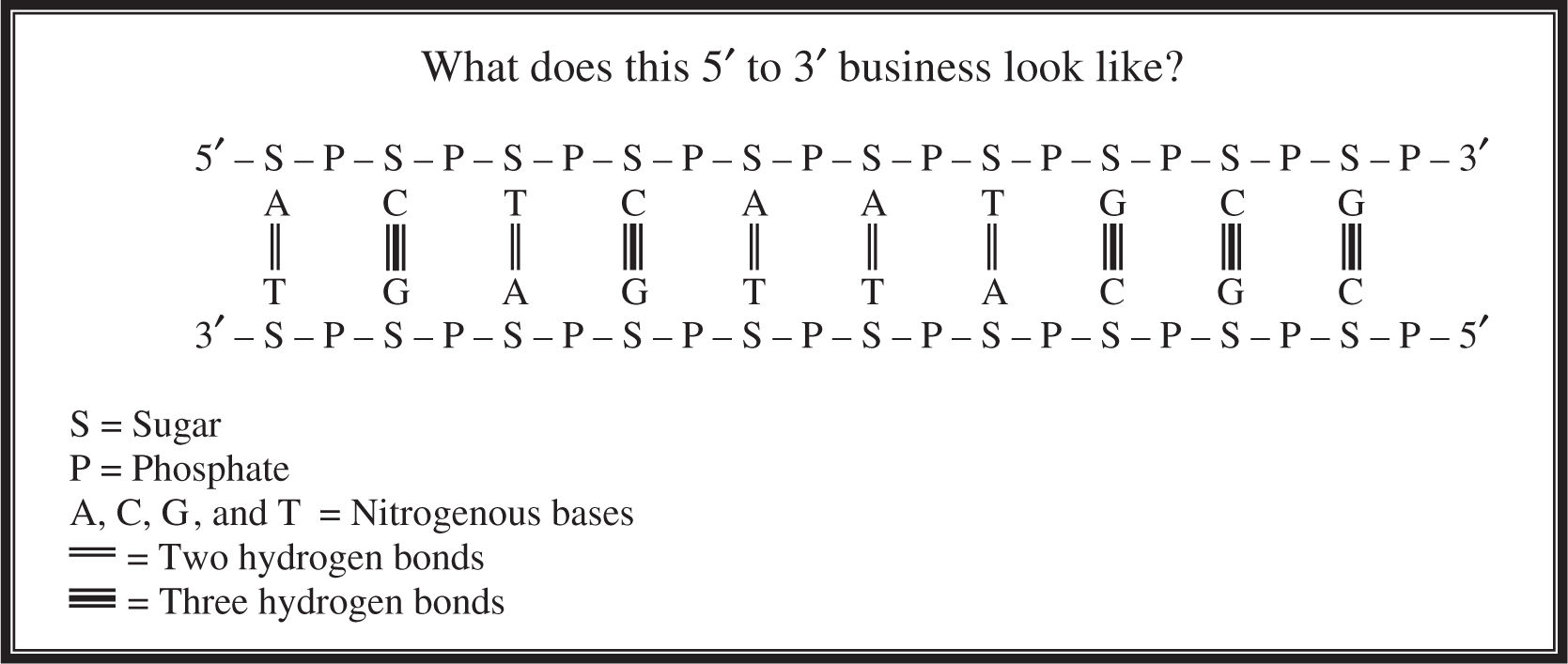
Figure 11.2 The 5′ and 3′ ends in DNA structure.
RNA Structure and Function
Ribonucleic acid is known to the world as RNA. There are some similarities between DNA and RNA. They both have a sugar-phosphate backbone. They both have four different nucleotides that make up the structure of the molecule. They both have three letters in their nickname—don’t worry if you don’t see that last similarity right away, . . . remember that we have been studying these things for years. These two molecules also have their share of differences. RNA’s nitrogenous bases are adenine, guanine, cytosine, and uracil. There is no thymine in RNA; uracil beat out thymine for the job (probably had a better interview during the hiring process). Another difference between DNA and RNA is that the sugar for RNA is ribose instead of deoxyribose. While DNA exists as a double strand, RNA has a bit more of an independent personality and tends to roam the cells as a single-stranded entity.
There are three main types of RNA that you should know about, all of which are formed from DNA templates in the nucleus of eukaryotic cells: (1) messenger RNA (mRNA), (2) transfer RNA (tRNA), and (3) ribosomal RNA (rRNA).
Replication of DNA
Human cells do not have copy machines to do the dirty work for them. Instead, they use a system called DNA replication to copy DNA molecules from cell to cell. As we discussed in Chapter 9 , this process occurs during the S-phase of the cell cycle to ensure that every cell produced during mitosis or meiosis receives the proper amount of DNA.
The mechanism for DNA replication was the source of much debate in the mid-1900s. Some argued that it occurred in what was called a “conservative” (conservative DNA replication ) fashion. In this model, the original double helix of DNA does not change at all; it is as if the DNA is placed on a copy machine and an exact duplicate is made. DNA from the parent appears in only one of the two daughter cells. A different model called the semiconservative DNA replication model agrees that the original DNA molecule serves as the template but proposes that before it is copied, the DNA unzips, with each single strand serving as a template for the creation of a new double strand. One strand of DNA from the parent goes to one daughter cell, and the second parent strand to the second daughter cell. A third model, the dispersive DNA replication model, suggested that every daughter strand contains some parental DNA, but it is dispersed among pieces of DNA not of parental origin. Figure 11.3 is a simplistic sketch showing these three main theories. Watson and Crick would not be pleased to see that we did not draw the DNA as a double helix . . . but as long as you realize this is not how the DNA truly looks, the figure serves its purpose.
An experiment performed in the 1950s by Meselson and Stahl helped select a winner in the debate about replication mechanisms. The experimenters grew bacteria in a medium containing 15 N (a heavier-than-normal form of nitrogen) to create DNA that was denser than normal. The DNA was denser because the bacteria picked up the 15 N and incorporated it into their DNA. The bacteria were then transferred to a medium containing normal 14 N nitrogen. The DNA was allowed to replicate and produced DNA that was half 15 N and half 14 N. When the first generation of offspring replicated to form the second generation of offspring, the new DNA produced was of two types—one type that had half 15 N and half 14 N, and another type that was completely 14 N DNA. This gave a hands-down victory to the semi-conservative theory of DNA replication. Let’s take a look at the mechanism of semi-conservative DNA replication.
During the S-phase of the cell cycle, the double-stranded DNA unzips and prepares to replicate. An enzyme called helicase unzips the DNA just like a jacket, breaking the hydrogen bonds between the nucleotides and producing the replication fork. Each strand then functions as a template for production of a new double-stranded DNA molecule. Specific regions along each DNA strand serve as primer sites that signal where replication should originate. Primase binds to the primer, and DNA polymerase, the superstar enzyme of this process, attaches to the primer region and adds nucleotides to the growing DNA chain in a 5′-to-3′ direction. DNA polymerase is restricted in that it can only add nucleotides to the 3′ end of a parent strand. This creates a problem because, as you can see in Figure 11.4 , this means that only one of the strands can be produced in a continuous fashion. This continuous strand is known as the leading strand. The other strand is affectionately known as the lagging strand. You will notice that in the third step of the process in Figure 11.4 , the lagging strand consists of tiny pieces called Okazaki fragments,which are later connected by an enzyme called DNA ligase to produce the completed double-stranded daughter DNA molecule. This is the semi-conservative model of DNA replication.
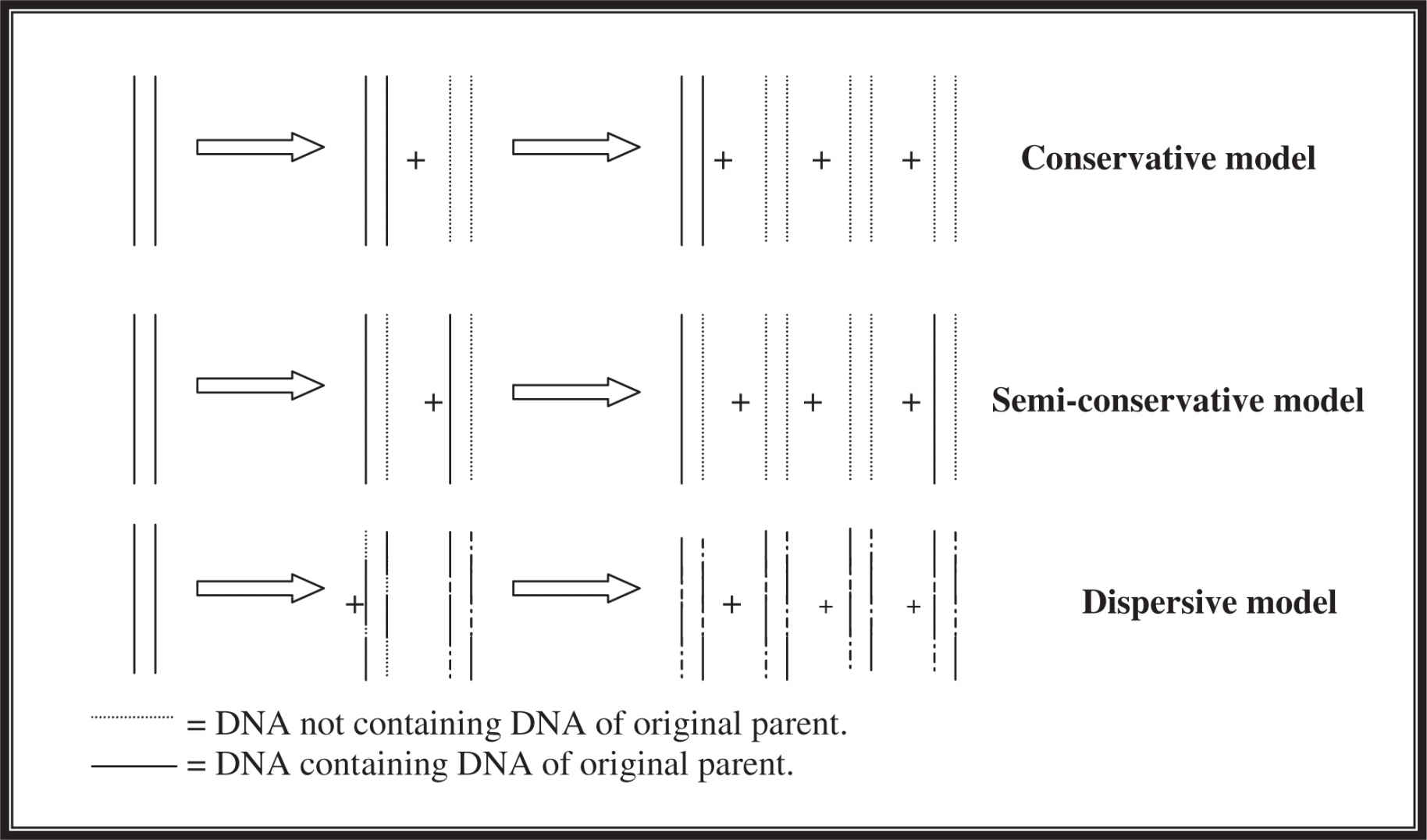
Figure 11.3 Three DNA replication models.
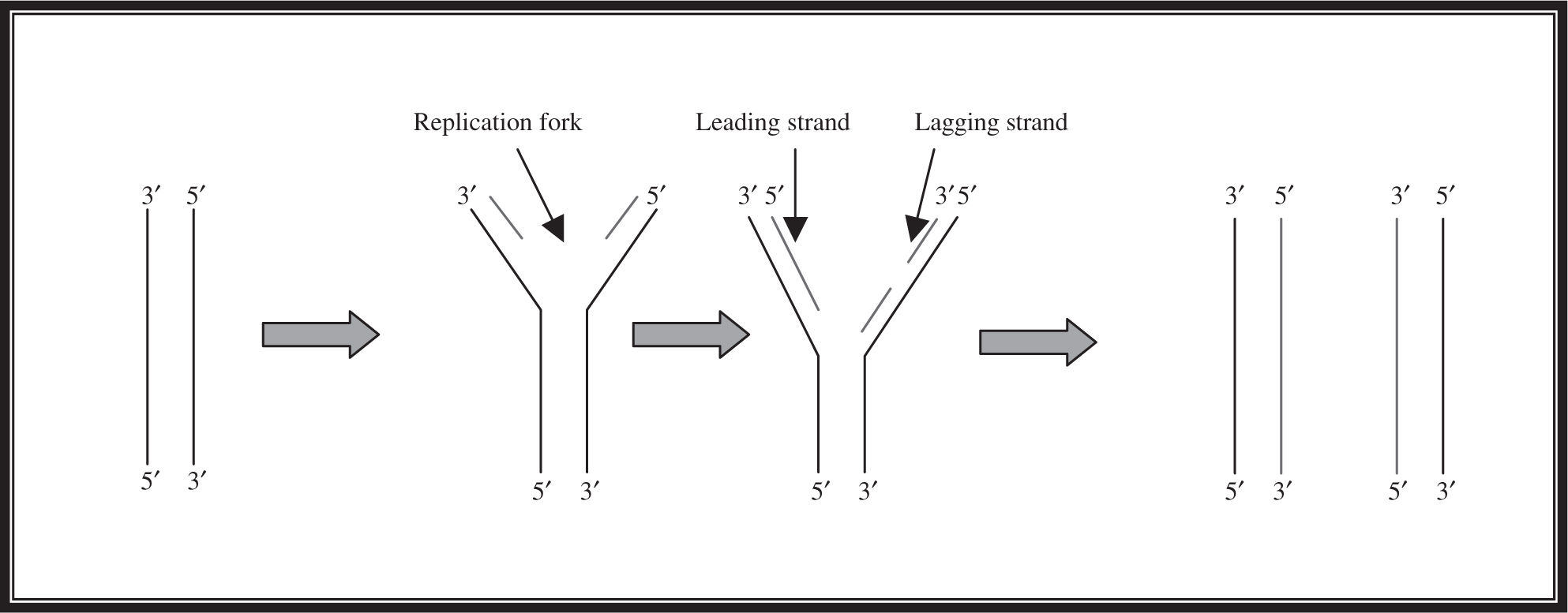
Figure 11.4 Semi-conservative DNA replication.
Unlike our work, DNA replication is not a perfect process—mistakes are made. A series of proofreading enzymes function to make sure that the DNA is properly replicated each time. During the first run-through, it is estimated that a nucleotide mismatch is made during replication in one out of every 10,000 basepairs. The proofreaders must do a pretty good job since a mismatch error in replication occurs in only one out of every billion nucleotides replicated. DNA polymerase proofreads the newly added base right after it is added on to make sure that it is the correct match. Repair is easy—the polymerase simply removes the incorrect nucleotide, and adds the proper one in its place. This process is known as mismatch repair. Another repair mechanism is excision repair, in which a section of DNA containing an error is cut out and the gap is filled in by DNA polymerase. There are other proteins that assist in the repair process, but their identities are not of major importance. Just be aware that DNA repair exists and is a very efficient process.
Here is a short list of mutation types that you should know:
1. Frameshift mutations . Deletion or addition of DNA nucleotides that does not add or remove a multiple of three nucleotides. mRNA is produced on a DNA template and is read in bunches of three called codons, which tell the protein synthesis machinery which amino acid to add to the growing protein chain. If the mRNA reads: THE FAT CAT ATE HER HAT, and the F is removed because of an error somewhere, the frame has now shifted to read THE ATC ATA THE ERH AT . . . (gibberish). This kind of mutation usually produces a nonfunctional protein unless it occurs late in protein production.
2. Missense mutation . Substitution of the wrong nucleotides into the DNA sequence. These substitutions still result in the addition of amino acids to the growing protein chain during translation, but they can sometimes lead to the addition of incorrect amino acids to the chain. It could cause no problem at all, or it could cause a big problem as in sickle cell anemia, in which a single amino acid error caused by a substitution mutation leads to a disease that wreaks havoc on the body as a whole.
3. Nonsense mutation . Substitution of the wrong nucleotides into the DNA sequence. These substitutions lead to premature stoppage of protein synthesis by the early placement of a stop codon, which tells the protein synthesis machinery to grind to a halt. The stop codons are UAA, UAG, and UGA. This type of mutation usually leads to a nonfunctional protein.
4. Thymine dimers . Result of too much exposure to UV (ultraviolet) light. Thymine nucleotides located adjacent to one another on the DNA strand bind together when this exposure occurs. This can negatively affect replication of DNA and help cause further mutations.
Transcription of DNA
NY teacher: “Know the basic principles. They’ll ask you about this process.”
Up until this point, we have just been discussing DNA replication, which is simply the production of more DNA. In the rest of the chapter, we discuss transcription, translation, and other processes involving DNA. While DNA is the hereditary material responsible for the passage of traits from generation to generation, DNA does not directly produce the proteins that it encodes. DNA must first be transcribed into an intermediary: mRNA. This process is called transcription (Figure 11.5 ) because both DNA and RNA are built from nucleotides—they speak a similar language. DNA acts as a template for mRNA, which then conveys to the ribosomes the blueprints for producing the protein of interest. Transcription occurs in the nucleus.

Figure 11.5 Transcription.
BIG IDEA 3.B.1
Gene regulation results in differential gene expression, leading to cell specialization .
Transcription consists of three steps: initiation, elongation, and termination. The process begins when RNA polymerase attaches to the promoter region of a DNA strand (initiation). A promoter region is simply a recognition site that shows the polymerase where transcription should begin. The promoter region contains a group of nucleotides known as the TATA box, which is important to the binding of RNA polymerase. As in DNA replication, the polymerase of transcription needs the assistance of helper proteins to find and attach to the promoter region. These helpers are called transcription factors. Once bound, the RNA polymerase works its magic by adding the appropriate RNA nucleotide to the 3′ end of the growing strand (elongation). Like DNA polymerase of replication, RNA polymerase adds nucleotides 5′ to 3′. The growing mRNA strand separates from the DNA as it grows longer. A region called the termination site tells the polymerase when transcription should conclude (termination). After reaching this site, the mRNA is released and set free.
RNA Processing
In bacteria, mRNA is ready to rock immediately after it is released from the DNA. In eukaryotes, this is not the case. The mRNA produced after transcription must be modified before it can leave the nucleus and lead the formation of proteins on the ribosomes. The 5′ and the 3′ ends of the newly produced mRNA molecule are touched up. The 5′ end is given a guanine cap, which serves to protect the RNA and also helps in attachment to the ribosome later on. The 3′ end is given something called a polyadenine tail, which may help ease the movement from the nucleus to the cytoplasm. Along with these changes, the introns (noncoding regions produced during transcription) are cut out of the mRNA, and the remaining exons (coding regions) are glued back together to produce the mRNA that is translated into a protein. This is called RNA splicing. We admit that it does seem strange and inefficient that the DNA would contain so many regions that are not used in the production of the gene, but perhaps there is method to the madness. It is hypothesized that introns exist to provide flexibility to the genome. They could allow an organism to make different proteins from the same gene; the only difference is which introns get spliced out from one to the other. It is also possible that this whole splicing process plays a role in allowing the movement of mRNA from the nucleus to the cytoplasm.
Translation of RNA
Now that the mRNA has escaped from the nucleus, it is ready to help direct the construction of proteins. This process occurs in the cytoplasm, and the site of protein synthesis is the ribosome. As mentioned in Chapter 5 , proteins are made of amino acids. Each protein has a distinct and particular amino acid order. Therefore, there must be some system used by the cell to convert the sequences of nucleotides that make up an mRNA molecule into the sequence of amino acids that make up a particular protein. The cell carries out this conversion from nucleotides to amino acids through the use of the genetic code. An mRNA molecule is divided into a series of codons that make up the code. Each codon is a triplet of nucleotides that codes for a particular amino acid. There are 20 different amino acids, and 64 different combinations of codons. This means that some amino acids are coded for by more than one codon. For example, the codons GCU, GCC, GCA, and GCG all call for the addition of the amino acid alanine during protein creation. Of these 64 possibilities, one is a start codon, AUG, which establishes the reading frame for protein formation. Also among these 64 codons are three stop codons: UGA, UAA, and UAG. When the protein formation machinery hits these codons, the production of a protein stops.
Before we go through the steps of protein synthesis, we would like to introduce to you the other players involved in the process. We have already spoken about mRNA, but we should meet the host of the entire shindig, the ribosomes, which are made up of a large and a small subunit. A huge percentage of a ribosome is built out of the second type of RNA mentioned earlier, rRNA. Two other important parts of a ribosome that we will discuss in more detail later are the A site and the P site, which are tRNA attachment sites. The job of tRNA is to carry amino acids to the ribosomes. The mRNA molecule that is involved in the formation of a protein consists of a series of codons. Each tRNA has, at its attachment site, a region called the anticodon, which is a three-nucleotide sequence that is perfectly complementary to a particular codon. For example, a codon that is AUU has an anticodon that reads UAA in the same direction. Each tRNA molecule carries an amino acid that is coded for by the codon that its anticodon matches up with. Once the tRNA’s amino acid has been incorporated into the growing protein, the tRNA leaves the site to pick up another amino acid just in case its services are needed again at the ribosome. An enzyme known as aminoacyl tRNA synthetase makes sure that each tRNA molecule picks up the appropriate amino acid for its anticodon.
Uh-oh . . . there is a potential problem here. There are fewer than 50 different types of tRNA molecules. But there are more codons than that. Oh, dear . . . but wait! This is not a problem because some tRNA are able to match with more than one codon. How can this be? This works thanks to a phenomenon known as wobble, where a uracil in the third position of an anticodon can pair with A or G instead of just A. There are some tRNA molecules that have an altered form of adenine, called inosine (I), in the third position of the anticodon. This nitrogenous base is able to bind with U, C, or A. Wobble allows the 45 tRNA molecules to service all the different types of codons seen in mRNA molecules.
We have met all the important players in the translation process (see also Figure 11.6 ), which begins when an mRNA attaches to a small ribosomal subunit. The first codon for this process is always AUG. This attracts a tRNA molecule carrying methionine to attach to the AUG codon. When this occurs, the large subunit of the ribosome, containing the A site and the P site, binds to the complex. The elongation of the protein is ready to begin. The P site is the host for the tRNA carrying the growing protein, while the A site is where the tRNA carrying the next amino acid sits. Think of the A site as the on-deck circle of a baseball field, and P site as the batter’s box. So, AUG is the first codon bound, and in the P site is the tRNA carrying the methionine. The next codon in the sequence determines which tRNA binds next, and that tRNA molecule sits in the A site of the ribosome. An enzyme helps a peptide bond form between the amino acid on the A site tRNA and the amino acid on the P site tRNA. After this happens, the amino acid from the P site moves to the A site, setting the stage for the tRNA in the P site to leave the ribosome. Now a step called translocation occurs. During this step, the ribosome moves along the mRNA in such a way that the A site becomes the P site and the next tRNA comes into the new A site carrying the next amino acid. This process continues until the stop codon is reached, causing the completed protein to leave the ribosome.
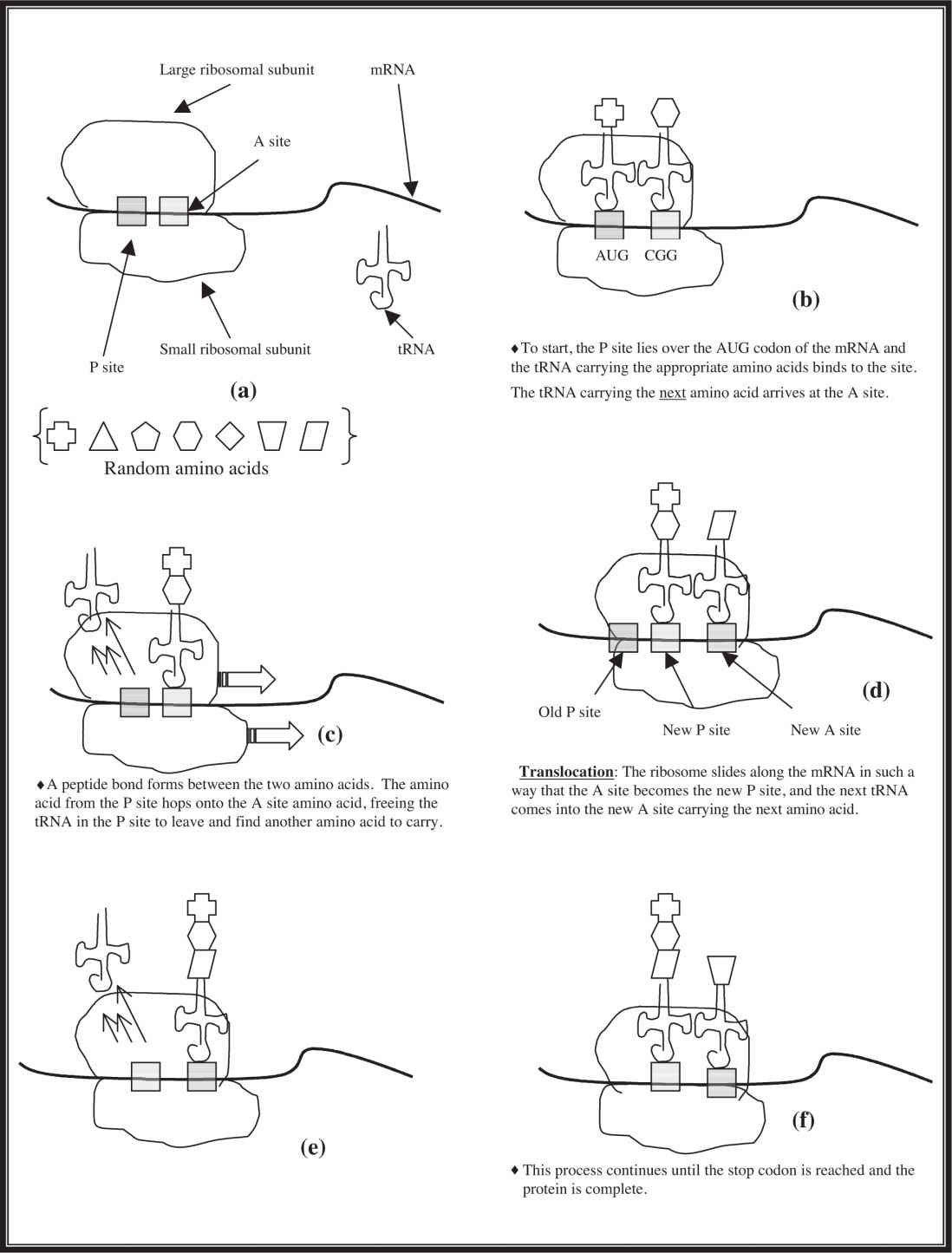
Figure 11.6 A pictorial representation of translation.
Gene Expression
Let’s cover some vocabulary before diving into this section:
Promoter region: a base sequence that signals the start site for gene transcription; this is where RNA polymerase binds to begin the process.
Operator: a short sequence near the promoter that assists in transcription by interacting with regulatory proteins (transcription factors).
Operon: a promoter/operator pair that services multiple genes; the lac operon is a well-known example (Figure 11.7 ).
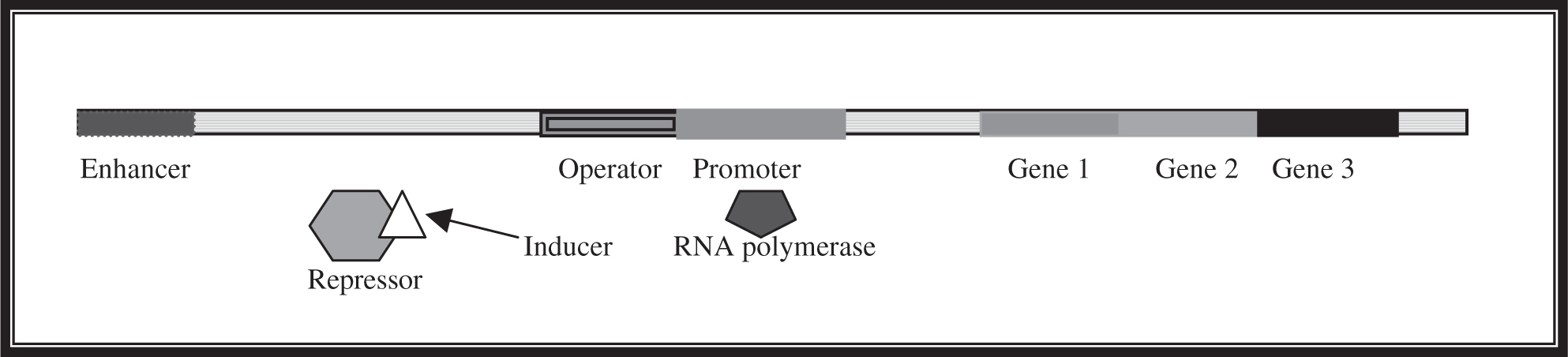
Figure 11.7 General layout of an operon.
CT teacher: “Be able to write about operons.”
Repressor: protein that prevents the binding of RNA polymerase to the promoter site.
Enhancer: DNA region, also known as a “regulator,” that is located thousands of bases away from the promoter; it influences transcription by interacting with specific transcription factors.
Inducer: a molecule that binds to and inactivates a repressor (e.g., lactose for the lac operon).
BIG IDEA 4.C.2
Environmental factors (e.g., lactose in a bacterial culture) can influence gene expression .
The control of gene expression is vital to the proper and efficient functioning of an organism. In bacteria, operons are a major method of gene expression control. The lactose operon services a series of three genes involved in the process of lactose metabolism. This contains the genes that help the bacteria digest lactose. It makes sense for bacteria to produce these genes only if lactose is present. Otherwise, why waste the energy on unneeded enzymes? This is where operons come into play—in the absence of lactose, a repressor binds to the promoter region and prevents transcription from occurring. When lactose is present, there is a binding site on the repressor where lactose attaches, causing the repressor to let go of the promoter region. RNA polymerase is then free to bind to that site and initiate transcription of the genes. When the lactose is gone, the repressor again becomes free to bind to the promoter, halting the process.
Because gene expression in eukaryotes involves more steps, there are more places where gene control can occur. Here are a few examples of eukaryotic gene expression control:
Transcription: controlled by the presence or absence of particular transcription factors, which bind to the DNA and affect the rate of transcription.
Translation: controlled by factors that tend to prevent protein synthesis from starting. This can occur if proteins bind to mRNA and prevent the ribosomes from attaching, or if the initiation factors vital to protein synthesis are inactivated.
DNA methylation: addition of CH3 groups to the bases of DNA. Methylation renders DNA inactive. Barr bodies, discussed in Chapter 10 , are highly methylated.
These are only a few of the examples of gene expression control that occur in eukaryotes. Do not get lost in the specifics.
The Genetics of Viruses
A virus is a parasitic infectious agent that is unable to survive outside of a host organism. Viruses do not contain enzymes for metabolism, and they do not contain ribosomes for protein synthesis. They are completely dependent on their host. Once a virus infects a cell, it takes over the cell’s machinery and uses it to produce whatever it needs to survive and reproduce. How a virus acts after it enters a cell depends on what type of virus it is. Classification of viruses is based on many factors:
BIG IDEA 3.A.1
DNA (and sometimes RNA) is the primary source of heritable information .
Genetic material: DNA, RNA, protein, etc.?
Capsid: type of capsid?
Viral envelope: present or absent?
Host range: what type of cells does it affect?
All viruses have a genome (DNA or RNA) and a protein coat (capsid). A capsid is a protein shell that surrounds the genetic material. Some viruses are surrounded by a structure called a viral envelope, which not only protects the virus but also helps the virus attach to the cells that it prefers to infect. The viral envelope is produced in the endoplasmic reticulum (ER) of the infected cell and contains some elements from the host cell and some from the virus. Each virus has a host range, which is the range of cells that the virus is able to infect. For example, the HIV virus infects the T cells of our body, and bacteriophages infect only bacteria.
A special type of virus that merits discussion is one called a retrovirus. This is an RNA virus that carries an enzyme called reverse transcriptase. Once in the cytoplasm of the cell, the RNA virus uses this enzyme and “reverse transcribes” its genetic information from RNA into DNA, which then enters the nucleus of the cell. In the nucleus, the newly transcribed DNA incorporates into the host DNA and is transcribed into RNA when the host cell undergoes normal transcription. The mRNA produced from this process gives rise to new retrovirus offspring, which can then leave the cell in a lytic pathway. A well-known example of a retrovirus is the HIV virus of AIDS.
Once inside the cell, a DNA virus can take one of two pathways—a lytic or a lysogenic pathway. In a lytic cycle, the cell actually produces many viral offspring, which are released from the cell—killing the host cell in the process. In a lysogenic cycle, the virus falls dormant and incorporates its DNA into the host DNA as an entity called a provirus. The viral DNA is quietly reproduced by the cell every time the cell reproduces itself, and this allows the virus to stay alive from generation to generation without killing the host cell. Viruses in the lysogenic cycle can sometimes separate out from the host DNA and enter the lytic cycle (like a bear awaking from hibernation).
Viruses come in many shapes and sizes. Although many viruses are large, viroids are plant viruses that are only a few hundred nucleotides in length, showing that size is not the only factor in viral success. Another type of infectious agent you should be familiar with is a prion —an incorrectly folded form of a brain cell protein that works its magic by converting other normal host proteins into misshapen proteins. An example of a prion disease that has been getting plenty of press coverage is “mad cow” disease. Prion diseases are degenerative diseases that tend to cause brain dysfunction—dementia, muscular control problems, and loss of balance.
The Genetics of Bacteria
Bacteria are prokaryotic cells that consist of one double-stranded circular DNA molecule. Present in the cells of many bacteria are extra circles of DNA called plasmids, which contain just a few genes and have been useful in genetic engineering. Plasmids replicate independently of the main chromosome. Bacterial cells reproduce in an asexual fashion, undergoing binary fission. Quite simply, the cell replicates its DNA and then physically pinches in half, producing a daughter cell that is identical to the parent cell. From this description of binary fission, it seems unlikely that there could be variation among bacterial cells. This is not the case, thanks to mutation and genetic recombination. As in humans, DNA mutation in bacteria occurs very rarely, but some bacteria replicate so quickly that these mutations can have a pronounced effect on their variability.
BIG IDEA 3.C.1
Bacteria have multiple ways to increase genetic variation .
Transformation
An experiment performed by Griffith in 1928 provides a fantastic example of transformation —the uptake of foreign DNA from the surrounding environment. Transformation occurs through the use of proteins on the surface of cells that snag pieces of DNA from around the cell that are from closely related species. This particular experiment involved a bacteria known as Streptococcus pneumoniae, which existed as either a rough strain (R), which is nonvirulent, or as a smooth strain (S), which is virulent. A virulent strain is one that can lead to contraction of an illness. The experimenters exposed mice to different forms of the bacteria. Mice given live S bacteria died. Mice given live R bacteria survived. Mice given heat-killed S bacteria survived. Mice given heat-killed S bacteria combined with live R bacteria died. This was the kicker . . . all the other results to this point were expected. Those exposed to heat-killed S combined with live R bacteria contracted the disease because the live R bacteria underwent transformation. Some of the R bacteria picked up the portion of the heat-killed S bacteria’s DNA, which contained the instructions on how to make the vital component necessary for successful disease transmission. These R bacteria became virulent.
BIG IDEA 3.C.3
Viral infection can introduce genetic variation into the host .
Transduction
To understand transduction, you first need to be introduced to something called a phage (Figure 11.8 )—a virus that infects bacteria. The mechanism by which a phage (otherwise known as bacteriophage) infects a cell reminds me of a syringe. A phage contains within its capsid the DNA that it is attempting to deliver. A phage latches onto the surface of a cell and like a syringe, fires its DNA through the membrane and into the cell. Transduction is the movement of genes from one cell to another by phages. The two main forms of transduction you should be familiar with are generalized and specialized transduction.
Figure 11.8 A phage.
Generalized Transduction Imagine that a phage virus infects and takes over a bacterial cell that contains a functional gene for resistance to penicillin. Occasionally during the creation of new phage viruses, pieces of host DNA instead of viral DNA are accidentally put into a phage. When the cell lyses, expelling the newly formed viral particles, the phage containing the host DNA may latch onto another cell, injecting the host DNA from one cell into another bacterial cell. If the phage attaches to a cell that contains a nonfunctional gene for resistance to penicillin, the effects of this transduction process can be observed. After injecting the host DNA containing the functional penicillin resistance gene, crossover could occur between the comparable gene regions, switching the nonfunctional gene with the functional gene. This would create a new cell that is resistant to penicillin.
Specialized Transduction This type of transduction involves a virus that is in the lysogenic cycle, resting quietly along with the other DNA of the host cell. Occasionally when a lysogenic virus switches cycles and becomes lytic, it may bring with it a piece of the host DNA as it pulls out of the host chromosome. Imagine that the host DNA it brought with it contains a functional gene for resistance to penicillin. This virus, now in the lytic cycle, will produce numerous copies of new viral offspring that contain this resistance gene from the host cell. If the new phage offspring attaches to a cell that is not penicillin resistant and injects its DNA and crossover occurs, specialized transduction will have occurred.
Conjugation
This is the raciest of the genetic recombinations that we will cover . . . the bacterial version of sex. It is the transfer of DNA between two bacterial cells connected by appendages called sex pili. Movement of DNA between two cells occurs across a cytoplasmic connection between the two cells and requires the presence of an F-plasmid, which contains the genes necessary for the production of a sex pilus.
Genetic Engineering
DNA technology is advancing at a rapid rate, and you need to have a basic understanding of the most common laboratory techniques for the AP Biology exam.
Restriction enzymes are enzymes that cut DNA at specific nucleotide sequences. When added to a solution containing DNA, the enzymes cut the DNA wherever the enzyme’s particular sequence appears. This creates DNA fragments with single-stranded ends called “sticky-ends, ” which find and reconnect with other DNA fragments containing the same ends (with the assistance of DNA ligase). Sticky ends allow DNA pieces from different sources to be connected, creating recombinant DNA. Another concept important to genetic engineering is the vector, which moves DNA from one source to another. Plasmids can be removed from bacterial cells and used as vectors by cutting the DNA of interest and the DNA of the plasmid with the same restriction enzyme to create DNA with similar sticky ends. The DNA can be attached to the plasmid, creating a vector that can be used to transport DNA.
Steve (12th grade): “Know this cold. It was all over my exam!”
Gel Electrophoresis
This technique is used to separate and examine DNA fragments. The DNA is cut with our new friends, the restriction enzymes, and then separated by electrophoresis. The pieces of DNA are separated on the basis of size with the help of an electric charge. DNA is added to the wells at the negative end of the gel. When the electric current is turned on, the migration begins. Smaller pieces travel farther along the gel, and larger pieces do not travel as far. The bigger you are, the harder it is to move. This technique can be used to sequence DNA and determine the order in which the nucleotides appear. It can be used in a procedure known as Southern blotting (after Edwin M. Southern, a British biologist) to determine if a particular sequence of nucleotides is present in a sample of DNA. Electrophoresis is used in forensics to match DNA found at the crime scene with DNA of suspects. This requires the use of pieces of DNA called restriction fragment length polymorphisms (RFLPs). DNA is specific to each individual, and when it is mixed with restriction enzymes, different combinations of RFLPs will be obtained from person to person. Electrophoresis separates DNA samples from the suspect and whatever sample is found at the scene of the crime. The two are compared, and if the RFLPs match, there is a high degree of certainty that the DNA sample came from the suspect. In Figure 11.9 , if well A is the DNA from the crime scene, then well C is the DNA of the guilty party.

Figure 11.9 A sample gel electrophoresis.
Cloning
Sometimes it is desirable to obtain large quantities of a gene of interest, such as insulin for the treatment of diabetes. The process of cloning involves many of the steps we just mentioned. Plasmids used for cloning often contain two important genes—one that provides resistance to an antibiotic, and one that gives the bacteria the ability to metabolize some sugar. In this case, we will use a galactose hydrolyzing gene and a gene for ampicillin resistance. The plasmid and DNA of interest are both cut with the same restriction enzyme. The restriction site for this enzyme is right in the middle of the galactose gene of the plasmid. When the sticky ends are created, the DNA of interest and the plasmid molecules are mixed and join together. Not every combination made here is what the scientist is looking for. The recombinant plasmids produced are transformed into bacterial cells. This is where the two specific genes for the plasmid come into play. The transformed cells are allowed to reproduce and are placed on a medium containing ampicillin. Cells that have taken in the ampicillin resistance gene will survive, while those that have not will perish. The medium also contains a special sugar that is broken down by the galactose enzyme present in the vector to form a colored product. The cells containing the gene of interest will remain white since the galactose gene has been interrupted and rendered nonfunctional. This allows the experimenter to isolate cells that contain the desired product. Now, it is time for us to quit cloning around and move onto another genetic engineering technique.
Polymerase Chain Reaction
Think of this technique as a high-speed copy machine. It is used to produce large quantities of a particular sequence of DNA in a very short amount of time. If the cloning reaction is the 747 of copying DNA, then polymerase chain reaction (PCR) is the Concorde. This process begins with double-stranded DNA containing the gene of interest. DNA polymerase, the superstar enzyme of DNA replication, is added to the mixture along with a huge number of nucleotides and primers specific for the sequence of interest, which help initiate the synthesis of DNA. PCR begins by heating the DNA to split the strands, followed by the cooling of the strands to allow the primers to bind to the sequence of interest. DNA polymerase then steps up to the plate and produces the rest of the DNA molecule by adding the nucleotides to the growing DNA strand. Each cycle concludes having doubled the amount of DNA present at the beginning of the cycle. The cycle is repeated over and over, every few minutes, until a huge amount of DNA has been created. PCR is used in many ways, such as to detect the presence of viruses like HIV in cells, diagnose genetic disorders, and amplify trace amounts of DNA found at crime scenes.
![]() Review Questions
Review Questions
1 . Which of the following statements is incorrect ?
A. Messenger RNA must be processed before it can leave the nucleus of a eukaryotic cell.
B. A virus in the lysogenic cycle does not kill its host cell, whereas a virus in the lytic cycle destroys its host cell.
C. DNA polymerase is restricted in that it can add nucleotides only in a 5′-to-3′ direction.
D. During translation, the A site holds the tRNA carrying the growing protein, while the P site holds the tRNA carrying the next amino acid.
E. Viroids are plant viruses that are only a few hundred nucleotides in length.
2 . The process of transcription results in the formation of
A. DNA.
B. proteins.
C. lipids.
D. RNA.
E. carbohydrates.
3 . Which of the following codons signals the beginning of the translation process?
A. AGU
B. UGA
C. AUG
D. AGG
E. UAG
4 . Which of the following is an improper pairing of DNA or RNA nucleotides?
A. Thymine-adenine
B. Guanine-thymine
C. Uracil-adenine
D. Guanine-cytosine
E. Pyrimidine-purine
5 . Which of the following is responsible for the type of diseases that includes “mad cow” disease?
A. Viroids
B. Plasmids
C. Prions
D. Provirus
E. Retrovirus
6 . Which of the following is the correct sequence of events that must occur for translation to begin?
A. Transfer RNA binds to the small ribosomal subunit, which leads to the attachment of the large ribosomal subunit. This signals to the mRNA molecule that it should now bind, with its first codon in the correct site, to the protein synthesis machinery, and translation begins.
B. Messenger RNA attaches to the small ribosomal subunit, with its first codon in the correct site, thus attracting a tRNA molecule to attach to the codon. This signals to the large subunit that it should now bind to the protein synthesis machinery, and translation can begin.
C. Messenger RNA attaches to the large ribosomal subunit with its first codon in the correct site, attracting a tRNA molecule to attach to the codon. This signals to the small subunit that it should now bind to the protein synthesis machinery, and translation can begin.
D. Transfer RNA binds to the large ribosomal subunit, which leads to the attachment of the small ribosomal subunit. This signals to the mRNA molecule that it should now bind with its first codon in the correct site to the protein synthesis machinery, and translation begins.
E. Transfer RNA attaches to the large ribosomal subunit, which attracts the mRNA molecule to attach with its first codon in the correct site to the large ribosomal subunit. This signals to the small subunit that it should now bind to the protein synthesis machinery, and translation can begin.
7 . All the following are players involved in the control of gene expression except
A. episomes.
B. repressors.
C. operons.
D. methylation.
E. hormones.
8 . Which of the following does not occur during RNA processing in the nucleus of eukaryotes?
A. The removal of introns from the RNA molecule
B. The addition of a string of adenine nucleotides to the 3′ end of the RNA molecule
C. The addition of a guanine cap to the 5′ end of the RNA molecule
D. The ligation of exons of the RNA molecule
E. The addition of methyl groups to certain nucleotides of the RNA molecules
9 . Which of the following statements is not true of a tRNA molecule?
A. The job of transfer RNA is to carry amino acids to the ribosomes.
B. At the attachment site of each tRNA, there is a region called the anticodon , which is a three-nucleotide sequence that is perfectly complementary to a particular codon.
C. Each tRNA molecule has a short lifespan and is used only once during translation.
D. The enzyme responsible for ensuring that a tRNA molecule is carrying the appropriate amino acid is aminoacyl tRNA synthase.
E. Transfer RNA is transcribed from DNA templates within the nucleus of eukaryotic cells.
For questions 10 and 11, please use the following gel:
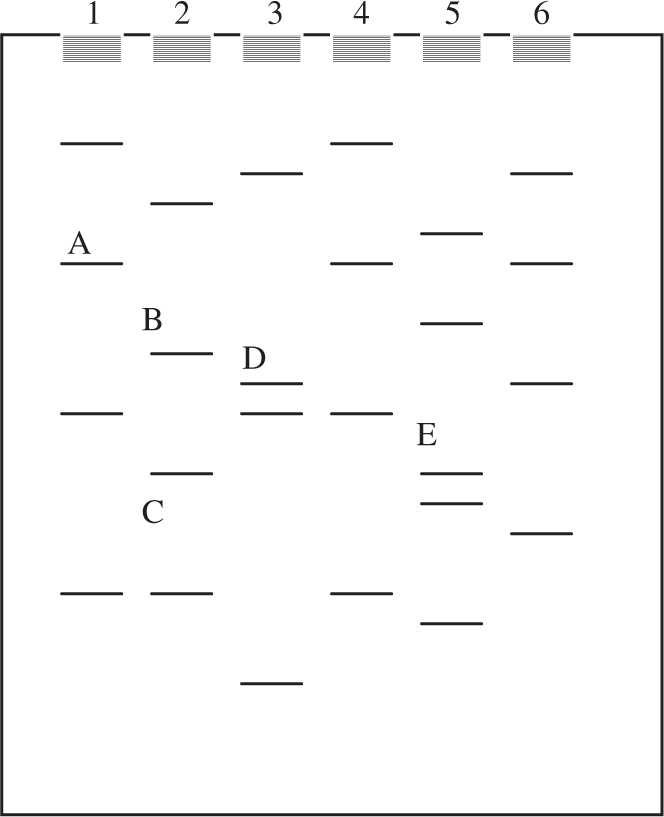
10 . Which of the DNA pieces in the gel is smallest in size?
A. A
B. B
C. C
D. D
E. E
11 . If well 1 is DNA from a crime scene, which individual should contact a lawyer?
A. Person 2
B. Person 3
C. Person 4
D. Person 5
E. Person 6
![]() Answers and Explanations
Answers and Explanations
1 . D —During translation, the P site holds the tRNA carrying the growing protein, while the A site holds the tRNA carrying the next amino acid. When translation begins, the first codon bound is the AUG codon, and in the P site is the tRNA with the methionine. The next codon in the sequence determines which tRNA binds next, and the appropriate tRNA molecule sits in the A site of the ribosome. A peptide bond forms between the amino acid on the A site tRNA and the amino acid on the P site tRNA. The amino acid from the P site then moves to the A site, allowing the tRNA in the P site to leave the ribosome. Next the ribosome moves along the mRNA in such a way that the A site is now the P site and the next tRNA comes into the A site carrying the next amino acid. Answer choices A, B, C, and E are all true.
2 . D —The process of transcription leads to the production of RNA. RNA is not immediately ready to leave the nucleus after it is produced. It must first be processed, during which a 3′ poly-A tail and a 5′ cap are added and the introns are spliced from the RNA molecule. After this process, the RNA is free to leave the nucleus and lead the production of proteins.
3 . C —AGG codes for the amino acid arginine. AGU codes for the amino acid serine. UGA and UAG are stop codons, which signal the end of the translation process. AUG is the start codon, which also codes for methionine.
4 . B —Guanine does not pair with thymine in DNA or RNA. Watson and Crick discovered that adenine pairs with thymine (A≠T) held together by two hydrogen bonds and guanine pairs with cytosine (C≡G) held together by three hydrogen bonds. One way that RNA differs from DNA is that it contains uracil instead of thymine. But in RNA, guanine still pairs with cytosine and adenine instead pairs with uracil. Watson and Crick also discovered that for the structure of DNA they discovered to be true, a purine must always be paired with a pyrimidine. Adenine and guanine are the purines, and thymine and cytosine are the pyrimidines.
5 . C —Prions are the culprit for mad cow disease. Viroids are tiny viruses that infect plants. Plasmids are small circles of DNA in bacteria that are separate from the main chromosome. They are self-replicating and are vital to the process of genetic engineering. A provirus is that which is formed during the lysogenic cycle of a virus when it falls dormant and incorporates its DNA into the host DNA. A retrovirus is an RNA virus that carries an enzyme called reverse transcriptase. A classic example of a retrovirus is HIV.
6 . B —Translation begins when the mRNA attaches to the small ribosomal subunit. The first codon for this process is always AUG. This attracts a tRNA molecule carrying methionine to attach to the AUG codon. When this occurs, the large subunit of the ribosome, containing the A site and the P site, binds to the complex. The elongation of the protein is ready to begin after the complex has been properly constructed. Answers A, C, D, and E are all in the incorrect order.
7 . A —Episomes are not involved in gene expression regulation. Episomes are plasmids that can be incorporated into a bacterial chromosome. Repressors are regulatory proteins involved in gene regulation. They work by preventing transcription by binding to the promoter region. Operons are a promoter-operator pair that controls a group of genes, such as the lac operon. Methylation is involved in gene regulation. Barr bodies, discussed in Chapter 10 , are found to contain a very high level of methylated DNA. Methyl groups have been associated with inactive DNA that does not undergo transcription. Hormones can affect transcription by acting directly on the transcription machinery in the nucleus of cells.
8 . E —The mRNA produced after transcription must be modified before it can leave the nucleus and lead the translation of proteins in the ribosomes. Introns are cut out of the mRNA, and the remaining exons are ligated back together to produce the mRNA ready to be translated into a protein. Also, the 5′ end is given a guanine cap, which serves to protect the RNA and also helps the mRNA attach to the ribosome. The 3′ end is given the poly-A tail, which may help ease the movement from the nucleus to the cytoplasm. Methylation does not occur during posttranscriptional modification—it is a means of gene expression control.
9 . C —tRNA does not have a short lifespan. Each tRNA molecule is released and recycled to bring more amino acids to the ribosomes to aid in translation. It is like a taxicab constantly picking up new passengers to deliver from place to place. Answer choices A, B, D, and E are all true.
10 . C —Gel electrophoresis separates DNA fragments on the basis of size—the smaller you are, the farther you go. Because C went the farthest in this gel, this must be the smallest of the five selected DNA pieces. Of the five labeled, piece A must be the largest because it moved the least.
11 . C —Person 4 should contact a lawyer. The DNA from the crime scene seems to match the DNA fingerprint from person 4. Electrophoresis is a very useful tool in forensics and can very accurately match DNA found at crime scenes with potential suspects.
![]() Rapid Review
Rapid Review
Briefly review the following terms:
DNA: contains A and G (purines), C and T (pyrimidines), arranged in a double helix of two strands held together by hydrogen bonds (A with T, and C with G).
RNA: contains A and G (purines), C and U (pyrimidines), single stranded. There are three types: mRNA (blueprints for proteins), tRNA (brings acids to ribosomes), and rRNA (make up ribosomes).
DNA replication: occurs during S-phase, semi-conservative, built in 5′ to 3′ direction. Helicase unzips the double strand, DNA polymerase comes in and adds on the nucleotides. Proofreading enzymes minimize errors of process.
Frameshift mutation: deletion or addition of nucleotides (not a multiple of 3); shifts reading frame.
Missense mutation: substitution of wrong nucleotide into DNA (e.g., sickle cell anemia); still produces a protein.
Nonsense mutation: substitution of wrong nucleotide into DNA that produces an early stop codon.
Transcription: process by which mRNA is synthesized on a DNA template.
RNA processing: introns (noncoding) are spliced out, exons (coding) glued together: 3′ poly-A tail, 5′ G cap.
Translation: process by which the mRNA specified sequence of amino acids is lined up on a ribosome for protein synthesis.
Codon: triplet of nucleotides that codes for a particular amino acid: start codon = AUG; stop codon = UGA, UAA, UAG. (For specifics on translation, please flip to text for a good description.)
Promoter: base sequence that signals start site for transcription.
Repressor: protein that prevents the binding of RNA polymerase to promoter site.
Inducer: molecule that binds to and inactivates a repressor.
Operator: short sequence near the promoter that assists in transcription by interacting with transcription factors.
Operon: on/off switch for transcription. Allows for production of genes only when needed. Remember the lac operon—lactose is the inducer, when present, transcription on; when absent, it is off.
Viruses: Parasitic infectious agent unable to survive outside the host; can contain DNA or RNA, or have a viral envelope (protective coat).
• Lytic cycle: one in which the virus is actively reproducing and kills the host cell.
• Lysogenic cycle: one in which the virus lies dormant within the DNA of the host cell.
Retrovirus: RNA virus that carries with it reverse transcriptase (HIV).
Prion: virus that converts host brain proteins into misshapen proteins (mad cow disease).
Viroids: tiny plant viruses.
Phage: virus that infects bacteria.
Bacteria: prokaryotic cells; consist of one double-stranded circular DNA molecule; reproduce by binary fission (e.g., plasmid —extra circle of DNA present in bacteria that replicate independently of main chromosome).
Genetic Recombination
Transformation: uptake of foreign DNA from the surrounding environment (smooth vs. rough pneumococcus).
Transduction: movement of genes from one cell to another by phages, which are incorporated by crossover.
• Generalized: lytic cycle accidently places host DNA into a phage, which is brought to another cell.
• Specialized: virus leaving lysogenic cycle brings host DNA with it into phage.
Conjugation: transfer of DNA between two bacterial cells connected by sex pili.
Genetic Engineering
Restriction enzymes: enzymes that cut DNA at particular sequences, creating sticky ends.
Vector: mover of DNA from one source to another (plasmids are good vectors).
Cloning: somewhat slow process by which a desired sequence of DNA is copied numerous times.
Gel electrophoresis: technique used to separate DNA according to size (small = faster). DNA moves from: − to +.
Polymerase chain reaction (PCR): produces large quantities of sequence in short amount of time.
CHAPTER 11
Molecular Genetics
1 . Translation of DNA to proteins is hosted by which of the following organelles?
(A) Chloroplasts
(B) Nucleus
(C) Ribosomes
(D) Mitochondria
2 . The process by which genes are moved from one cell to another via phages is known as
(A) transduction.
(B) transformation.
(C) translation.
(D) transcription.
3 . During gel electrophoresis, DNA pieces are separated on the basis of
(A) charge.
(B) size.
(C) pH.
(D) salinity.
4 . Conjugation is the process by which DNA is transferred between two bacterial cells connected by appendages known as sex pili. For conjugation to occur, which of the following must be present?
(A) Barr body
(B) Restriction enzyme
(C) Provirus
(D) F plasmid
![]() Answers and Explanations
Answers and Explanations
1 . C —Translation is related to protein synthesis, which is hosted by the ribosomes.
2 . A
3 . B —During gel electrophoresis, smaller pieces travel farther along the gel, whereas larger pieces do not travel as far. The bigger you are, the harder it is to move.
4 . D —An F plasmid is a plasmid that contains the genes necessary for the production of a sex pilus, the appendage needed to connect two bacterial cells during conjugation.