THE LIVING WORLD
Unit Three. The Continuity of Life
13.2. The Human Genome
On June 26, 2000, geneticists announced that the entire human genome had been sequenced. This effort presented no small challenge, as the human genome is huge—more than 3 billion base pairs, which is the largest genome sequenced to date. To get an idea of the magnitude of the task, consider that if all 3.2 billion base pairs were written down on the pages of this book, the book would be 500,000 pages long, and it would take you about 60 years, working eight hours a day, every day, at five bases a second, to read it all.
Reading the human genome for the first time, geneticists encountered four big surprises.
1. The Number of Genes Is Quite Low
The human genome sequence contains only 20,000 to 25,000 protein-encoding genes, only 1% of the genome. As you can see in figure 13.2, this is scarcely more genes than in a nematode worm (21,000 genes), not quite double the number in a fruit fly (13,000 genes). Researchers had confidently anticipated at least four times as many genes because over 100,000 unique messenger RNA (mRNA) molecules can be found in human cells—surely, they argued, it would take as many genes to make them.
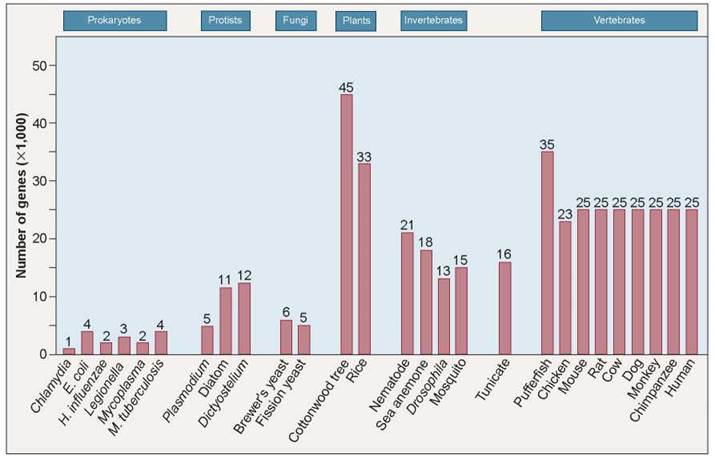
Figure 13.2. Comparing genome size.
All mammals have the same size genome, 20,000 to 25,000 protein-encoding nuclear genes. The unexpectedly larger sizes of the plant and pufferfish genomes are thought to reflect whole-genome duplications rather than increased complexity.
How can human cells contain more mRNAs than genes? Recall from chapter 12 that in a typical human gene, the sequence of DNA nucleotides that specifies a protein is broken into many bits called exons, scattered among much longer segments of nontranslated DNA called introns. Imagine this paragraph was a human gene; all the occurrences of the letter “e” could be considered exons, while the rest would be noncoding introns, which make up 24% of the human genome.
When a cell uses a human gene to make a protein, it first manufactures mRNA copies of the gene, then splices the exons together, getting rid of the intron sequences in the process. Now here’s the turn of events researchers had not anticipated: The exon portions of human gene transcripts are often spliced together in different ways, called alternative splicing. As we discussed in chapter 12, each exon is actually a module; one exon may code for one part of a protein, another for a different part of a protein. When the exon transcripts are mixed in different ways, very different protein shapes can be built.
With alternative mRNA splicing, it is easy to see how 25,000 genes can encode four times as many proteins. The added complexity of human proteins occurs because the gene parts are put together in new ways. Great music is made from simple tunes in much the same way.
2. Some Chromosomes Have Few Genes
In addition to the fragmenting of genes by the scattering of exons throughout the genome, there is another interesting “organizational” aspect of the genome. Genes are not distributed evenly over the genome. The small chromosome number 19 is packed densely with genes, transcription factors, and other functional elements. The much larger chromosome numbers 4 and 8, by contrast, have few genes, scattered like isolated hamlets in a desert. On most chromosomes, vast stretches of seemingly barren DNA fill the chromosomes between clusters rich in genes.
3. Genes Exist in Many Copy Numbers
Four different classes of protein-encoding genes are found in the human genome, differing largely in gene copy number.
Single-copy genes. Many eukaryotic genes exist as single copies at a particular location on a chromosome. Mutations in these genes produce recessive Mendelian inheritance of those traits. Silent copies inactivated by mutation, called pseudogenes, are as common as protein-encoding genes.
Segmental duplications. Human chromosomes contain many segmental duplications, whole blocks of genes that have been copied over from one chromosome to another. Blocks of similar genes in the same order are found throughout the genome. Chromosome 19 seems to have been the biggest borrower, with blocks of genes shared with 16 other chromosomes.
Multigene families. Many genes exist as parts of multigene families, groups of related but distinctly different genes that often occur together in a cluster. Multigene families contain from three to several dozen genes. Although they differ from each other, the genes of a multigene family are clearly related in their sequences, making it likely that they arose from a single ancestral sequence.
Tandem clusters. These groups of repeated genes consist of DNA sequences that are repeated many thousands of times, one copy following another in tandem array. By transcribing all of the copies in these tandem clusters simultaneously, a cell can rapidly obtain large amounts of the product they encode. For example, the genes encoding rRNA are present in clusters of several hundred copies.
4. Most Genome DNA Is Noncoding
The fourth notable characteristic of the human genome is the startling amount of noncoding DNA it possesses. Only 1% to 1.5% of the human genome is coding DNA, devoted to genes encoding proteins. Each of your cells has about 6 feet of DNA stuffed into it, but of that, less than 1 inch is devoted to genes! Nearly 99% of the DNA in your cells seems to have little or nothing to do with the instructions that make you who you are (figure 13.3).
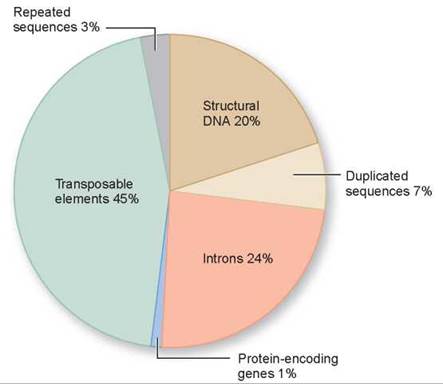
Figure 13.3. The human genome.
Very little of the human genome is devoted to protein-encoding genes, indicated by the light blue section in this pie chart.
There are four major types of noncoding human DNA:
Noncoding DNA within genes. As discussed earlier, a human gene is made up of numerous fragments of protein-encoding information (exons) embedded within a much larger matrix of noncoding DNA (introns). Introns make up 24% of the human genome—exons only 1%!
Structural DNA. Some regions of the chromosomes remain highly condensed, tightly coiled, and untranscribed throughout the cell cycle. These portions—about 20% of the DNA—tend to be localized around the centromere, or located near the telomeres, or ends, of the chromosome.
Repeated sequences. Scattered about chromosomes are simple sequence repeats of two or three nucleotides like CA or CGG, repeated like a broken record thousands and thousands of times. These make up about 3% of the human genome. An additional 7% is devoted to other sorts of duplicated sequences. Repetitive sequences with excess C and G tend to be found in the neighborhood of genes, while A- and T-rich repeats dominate the nongene deserts. The light bands on chromosome karyotypes now have an explanation—they are regions rich in GC and genes. Dark bands signal neighborhoods rich in A and T, which are thin on genes. Chromosome 8, for example, contains many nongene areas that are indicated by dark bands, while chromosome 19 is dense with genes and so it has few dark bands.
Transposable elements. Fully 45% of the human genome consists of mobile parasitic bits of DNA called transposable elements. Discovered by Barbara McClintock in 1950 (she won the Nobel Prize in Physiology or Medicine for her discovery in 1983), transposable elements are bits of DNA that are able to jump from one location on a chromosome to another— tiny molecular versions of Mexican jumping beans. Because they leave a copy of themselves behind when they jump, their numbers in the genome increase as generations pass. Nested within the human genome are over half a million copies of an ancient transposable element called Alu, composing fully 10% of the entire human genome. Often jumping right into genes, Alu transpositions cause many harmful mutations.
Key Learning Outcome 13.2. The entire 3.2-billion-base pair human genome has been sequenced. Only about 1% to 1.5% of the human genome is devoted to protein-encoding genes. Much of the rest is composed of transposable elements.
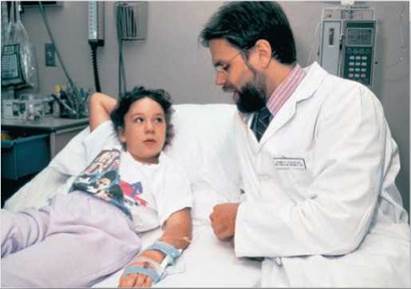
Curing disease. One of two young girls who were the first humans "cured" of a hereditary disorder by transferring into their bodies healthy versions of a defective gene. The transfer was successfully carried out in 1990, and twenty years later the girls remain healthy.

Increasing yields. The genetically engineered salmon on the right have shortened production cycles and are heavier than the nontransgenic salmon of the same age on the left.

Pest-proofing plants. The genetically engineered cotton plants on the right have a gene that inhibits feeding by weevils; the cotton plants on the left lack this gene, and produce far fewer cotton bolls.
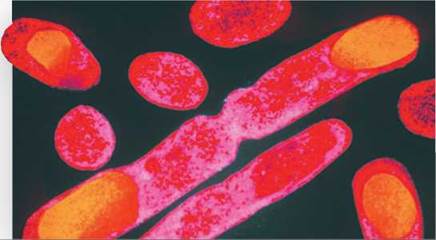
Producing insulin. The common bacteria Escherichia coli (E. coli) can be genetically engineered to contain the gene that codes for the protein insulin. The bacteria are turned into insulin-producing factories and can produce large quantities of insulin for diabetic patients. In the image above, insulin-producing sites inside genetically-altered E. coli cells are orange.
Figure 13.4. Examples of genetic engineering.