Botany: An Introduction to Plant Biology - Mauseth, James D. 2017
Plant Physiology and Development
Genes and the Genetic Basis of Metabolism and Development
Chapter Opener Image: Each cell in this leaf of corn (Zea mays) contains the same genes as every other cell here, and that is true of the genes in the nuclei, mitochondria, and plastids. Despite having the same genes, various cells develop particular characters and metabolisms because they activate certain genes and repress others. For example, cells in the epidermis express the genes that guide the formation of cutin and wax, but other cells repress these genes. Cells in the xylem activate lignin genes but other cells do not.
OUTLINE
✵ Concepts
✵ Storing Genetic Information
- Protecting the Genes
- The Genetic Code
- The Structure of Genes
- Transcription of Genes
✵ Protein Synthesis
- Ribosomes
- tRNA
- mRNA Translation
✵ Control of Protein Levels
✵ Analysis of Genes and Recombinant DNA Techniques
- Nucleic Acid Hybridization
- Restriction Endonucleases
- Identifying DNA Fragments
- DNA Cloning
- DNA Sequencing
- Sequencing Entire Genomes
✵ Genetic Engineering of Plants
✵ Viruses
- Virus Structure
- Virus Metabolism
- Formation of New Virus Particles
- Origin of Viruses
- Plant Diseases Caused by Viruses
Box 15-1 Plants and People: Genetic Engineering and Evolution
LEARNING OBJECTIVES
After reading this chapter, students will be able to:
✵ Explain the differential activation of genes.
✵ Recall the three ways DNA is safely and accurately stored.
✵ Summarize plant gene structure and the transcription process.
✵ Discuss the function of ribosomes and tRNA.
✵ Summarize mRNA translation from initiation through termination.
✵ Restate the process through which transcription factors control gene activity.
✵ Describe the different methods of gene analysis.
✵ List one use for DNA cloning.
✵ Recall two methods of DNA sequencing.
✵ State one difficulty in plant genetic engineering.
✵ Discuss the process of using viruses as vectors in plant genetic engineering.
 Did You Know?
Did You Know?
✵ Our genes control our development partly by directing the synthesis of enzymes such that needed metabolic pathways are functional.
✵ Other genes direct the production of structural proteins that alter cell shape.
✵ Very few genes code for only one character such as brown eyes versus blue eyes.
✵ Most genes affect parts of one or several metabolic pathways, so when they mutate, they affect multiple pathways and characters.
![]() Concepts
Concepts
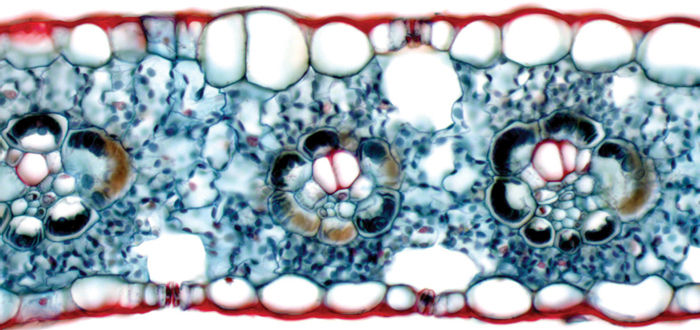
Plants are composed of numerous types of cells. Each cell type is unique because it has a distinct metabolism, based largely on proteins such as enzymes, microtubules, and membrane proteins. Although all cells carry out a fundamental metabolism involving respiration, amino acid synthesis, and so on, some of the reactions in each cell type differ from those in other cell types. Each may have one or more characteristic types of enzymes or other proteins. For example, enzymes involved in synthesis of flower color pigments are present in petal cells but not in cells of roots, wood, and bark (FIGURE 15-1A). Also, sclerenchyma cells contain all enzymes necessary for producing and lignifying secondary walls, but these enzymes and metabolic pathways are not present in parenchyma cells (FIGURES 15-1B—D).
Cells also differ in shape, again largely owing to differences in their proteins. All tracheids and vessel elements probably have the same enzymes and metabolism for secondary wall deposition, but the pattern of wall deposition varies, guided by a pattern of protein microtubules in the protoplasm (FIGURE 15-1E). Similarly, cell divisions occur in precise patterns, and as a result, there must be an underlying pattern in the cell that causes the mitotic spindle to have the proper alignment.
The information needed to construct each type of protein is stored in genes, but because an organism grows by mitosis—duplication division—all of its cells have identical sets of genes. As each cell differentiates and develops a unique suite of proteins, the underlying developmental process is the differential activation of genes. In the maturing epidermis, genes that code for cutin-synthesizing enzymes are turned on, whereas in other cells they remain turned off (FIGURE 15-2). On the other hand, genes for P-protein remain quiescent in all except phloem cells. Studies of development and morphogenesis examine the mechanisms by which some genes are activated and others are repressed.

FIGURE 15-1 Cell differentiation is controlled by regulating particular genes in each type of cell. (A) These petals have enzymes necessary for synthesis of pigments. These enzymes are not produced in most other cells of the plant, although all cells contain the necessary genes. (B) These wood cells had many enzymes not found in the petal cells of the same plant. During differentiation, each cell type became unique as different genes were activated, different proteins were produced, and their metabolisms diverged into unique pathways (200). (C) Chlorenchyma cells differ from other types by having well-developed chloroplasts (×200). (D) These cells have differentiated such that starch storage and release are the dominant aspects of metabolism. They probably have no unique enzymes: All cells can metabolize starch. Degree of activity of a particular set of proteins is important in differentiation (×180). (E) These vessels and fibers have similar, if not identical, metabolisms for synthesis and lignification of walls; they differ primarily in cell shape and pattern of secondary wall deposition. Precise positioning of cellular elements is also critical during differentiation (×150).
TABLE 15-1 Nucleotides
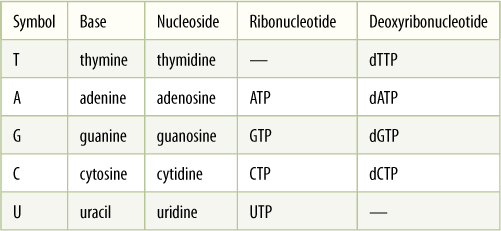
Nucleic acids contain five bases, abbreviated T, A, G, C, and U. One base plus a five-carbon sugar is a nucleoside, and with a phosphate attached, a nucleoside becomes a nucleotide:
base + sugar = nucleoside
base + sugar + phosphate = nucleotide
When DNA is synthesized, deoxyribonucleotides—those that contain the sugar deoxyribose—are used; when RNA is made, ribonucleotides—containing ribose—are used. Uracil does not occur in DNA, and thymine is absent from RNA.
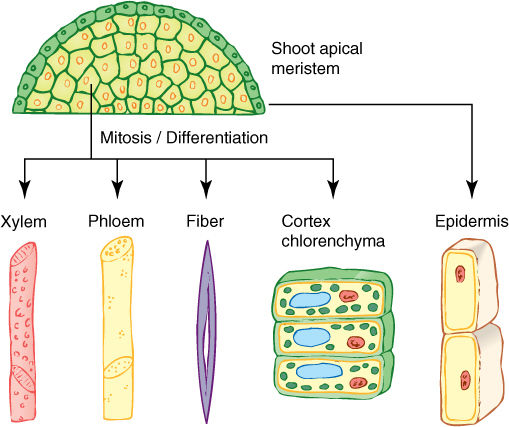
FIGURE 15-2 Because all body cells are produced by mitosis, they all have the same genes. Certain basic metabolism genes (“housekeeping genes”) are probably active in all cells, but specific pathways become active during differentiation, probably because the genes that code for the enzymes of those pathways become active. Once fully mature, the cells may go back to basal metabolism. Epidermal cells often produce cutin only when differentiating, not after maturity. Sieve elements lose their nuclei as part of maturation, and tracheary elements digest away all of their protoplasm; they have no metabolism at all when mature.
During protein synthesis, the correct amino acids must be incorporated in the proper sequence because this determines both the structure and all other properties of the protein. The cell must contain a source of information that holds the sequence information for all its proteins; this information archive is DNA, deoxyribonucleic acid. DNA is a linear, unbranched polymer composed of four types of deoxynucleotide monomers, usually abbreviated A, T, G, and C (TABLE 15-1). Once actually polymerized into DNA, the base portion of each nucleotide monomer protrudes as a side group. It is the sequence of nucleotide side groups that is the information needed to synthesize proteins correctly. A gene is each region of DNA that is responsible for coding the amino acid sequence in a particular protein. Each type of protein has its own gene.
Both environment and protoplasm also contain information vitally important for plant growth, morphogenesis, and survival. The environment provides informative cues about season, moisture availability, time for seed germination, time for flowering, and direction of gravity. These environmental and metabolic signals must be converted into chemical messengers that enter the nucleus and interact with genes. If the signals indicate that the cell is to differentiate into a vessel element, all genes that produce enzymes necessary for synthesis and lignification of a secondary wall must be located and activated. Genes that code for proteins that guide a particular pattern of wall deposition also must be turned on. Conversely, the cell must be inhibited from under going any further cell division; genes involved in mitosis and cytokinesis must be repressed.
Several techniques permit botanists to locate the genes for many proteins; the genes can then be isolated in vitro, duplicated and their nucleotide sequences revealed. Currently, our knowledge is still limited, but these techniques of DNA sequence analysis are so powerful that progress is extremely rapid. Similar techniques make it possible to alter the DNA sequence and then insert the gene back into a plant cell. As the cell grows, divides, and differentiates, the altered DNA either produces an altered protein if the coding region was changed or produces the protein at an unusual time or place if its control site was changed. These recombinant DNA techniques, sometimes called genetic engineering, are helping us understand the processes that occur between the perception of a stimulus and the plant’s response to that stimulus. In addition, recombinant DNA techniques permit us to change features of plants—for example, making them more resistant to insects or having seeds and fruits that are more nutritious for us.
![]() Storing Genetic Information
Storing Genetic Information
Protecting the Genes
It is critically important that the information in DNA be stored accurately for a long time; if storage is not safe, the information produced by the DNA will be inaccurate and probably useless or even harmful. There are several ways in which DNA is kept relatively inert and safely stored.
1. DNA does not participate directly in protein synthesis. Instead, DNA produces a messenger molecule, messenger RNA (mRNA), which carries information from DNA to the site of protein synthesis. The mRNA, not DNA, is exposed to the numerous enzymes, substrates, activators, and controlling factors of protein synthesis (FIGURE 15-3). If mRNA is damaged, it can be replaced with more copies of mRNA. Within a single cell, thousands of individual molecules of a particular enzyme may be needed; if the DNA itself had to direct the synthesis of each protein molecule, it would probably be damaged long before enough protein had been synthesized. Instead, however, DNA directs the production of several copies of mRNA, each of which directs the production of hundreds of protein molecules.
2. Most DNA is stored in the nucleus, protected from the cytoplasm by the nuclear envelope. During interphase, the nuclear envelope forms the outer boundary of the nucleus, keeping most cytoplasmic components out and the proper nuclear substances in. The DNA of plastids and mitochondria is protected from cytosol enzymes by being located within plastids and mitochondria themselves. Nuclear genes in plants store information for approximately 20,000 to 40,000 types of proteins; plastid DNA encodes only about 50 to 100 genes, and mitochondrial DNA specifies less than 40.
3. Histone proteins hold most nuclear DNA in an inert, resistant form. Histones are a special class of proteins found in all organisms that have nuclei (plants, animals, fungi, algae, and protozoans). There are five types—H1, H2A, H2B, H3, and H4. The last four are among the most highly conserved proteins known; that is, the sequence of amino acids in the histones of one organism is virtually identical to the sequence in any other organism. For example, the H4 histone contains 103 amino acids, and its sequence in higher animals, such as cows, differs from its sequence in higher plants, such as peas, at only two sites (FIGURE 15-4). Histone proteins are so essential that virtually any change in their amino acid sequence causes the organism to die or at least not reproduce.
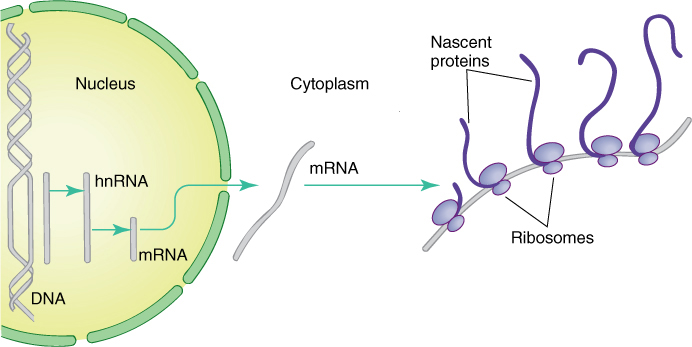
FIGURE 15-3 When a gene is active, its sequence of nucleotides guides the synthesis of “heterogeneous nuclear RNA,” which is modified into messenger RNA and transported to the cytoplasm. mRNA binds to ribosomes that translate (read) its nucleotide sequence and polymerize amino acids in the proper order, thus creating a protein. Ribosomes on the left have just started; thus, their proteins are still short; ribosomes on the right have read almost all the RNA, so their proteins are longer, almost complete.
Histones form aggregates and DNA wraps around them, forming a spherical structure called a nucleosome. Histone H1 then binds nucleosomes into a tightly coiled configuration. In this mode, the DNA/protein structure—chromatin—is so dense that enzymes cannot penetrate it, and DNA is relatively inert. Even if it is exposed directly to DNA-digesting enzymes, called DNases (also written as DNAases), histone-bound DNA is not extensively damaged. However, chromatin is still sensitive to regulatory molecules and can be unpacked in preparation for synthesis of mRNA or for replication of DNA during the S phase of the cell cycle.

FIGURE 15-4 The nucleotide sequence for the gene for histone H4 in wheat is presented in the top row of each set of lines. In the second row is the sequence for the same gene for a different type of wheat. Where the two genes are identical, only a dash appears for the second gene. The portion of the gene that codes for protein begins in the fifth line (labeled +1), and the amino acid sequence—the primary structure of the protein—is given in the third row of each set of lines. Wherever a mutation has caused the second gene to code for an amino acid different from the first gene, that amino acid is given in the fourth row. Although 18 mutations have occurred, the resulting amino acid sequence is unchanged except at one site (amino acid #4 after the +1 start site; most of these mutations have no effect because the genetic code is redundant—discussed later in the chapter). The noncoding regions of the gene—from the beginning to +1, and from +309 to the end—are not highly conserved, and the two genes differ greatly in these sites.
Plastids, mitochondria, and prokaryotes have no histones or nucleosomes; their DNA is naked.
The Genetic Code
Twenty types of amino acids are used in synthesizing proteins, but only four different nucleotides are present in DNA or mRNA; consequently, it is not possible for one nucleotide alone to specify one amino acid because 16 amino acids would be left without nucleotides to code for them. Similarly, nucleotides cannot be used simply in pairs of two, such as AU for isoleucine or CC for proline, because there are only 16 possible pairs. It is necessary for nucleotides to be read and used in groups of three; 64 possible triplets, known as codons, can be made using four nucleotides. TABLE 15-2 shows which amino acid is coded by each codon. Notice that codon refers to triplets in mRNA, not in DNA.
With 64 possible triplets, a surplus of 44 codons remains after each amino acid is paired with a codon. Three codons—UAA, UAG, and UGA—are stop codons; they signal that the ribosome should stop protein synthesis. AUG is the start codon that signals the point in mRNA where protein synthesis should begin. The extra 40 codons also code for amino acids, so most amino acids have two or more codons. For example, both UUU and UUC code for phenylalanine, and CAU and CAC code for histidine. Because multiple codons exist for most amino acids, the genetic code is said to be degenerate. Degeneracy further protects DNA: A mutation in DNA might change a codon in mRNA from UUU to UUC, for example, but because both code for phenylalanine, the same protein is produced before and after this particular mutation.
The genetic code is almost perfectly universal; all organisms and genetic systems but one share the genetic code shown in Table 15-2. Viruses, prokaryotes, fungi, animals, and plants all use the same codons to specify particular amino acids, and the same is true for plastid DNA. Only in mitochondria are several codons changed. This almost universal commonality of the genetic code is one of the strongest pieces of evidence that life arose only once on Earth and that all living organisms have evolved from one ancestral organism.
The Structure of Genes
Most genes, up to 90% in any cell, are quiescent most of the time and are activated and read only when the cell needs the particular enzymes they code for. Each gene must have a structure that allows controlling substances to recognize the gene, bind to it, and activate it at the proper time.
TABLE 15-2 The Codons of mRNA
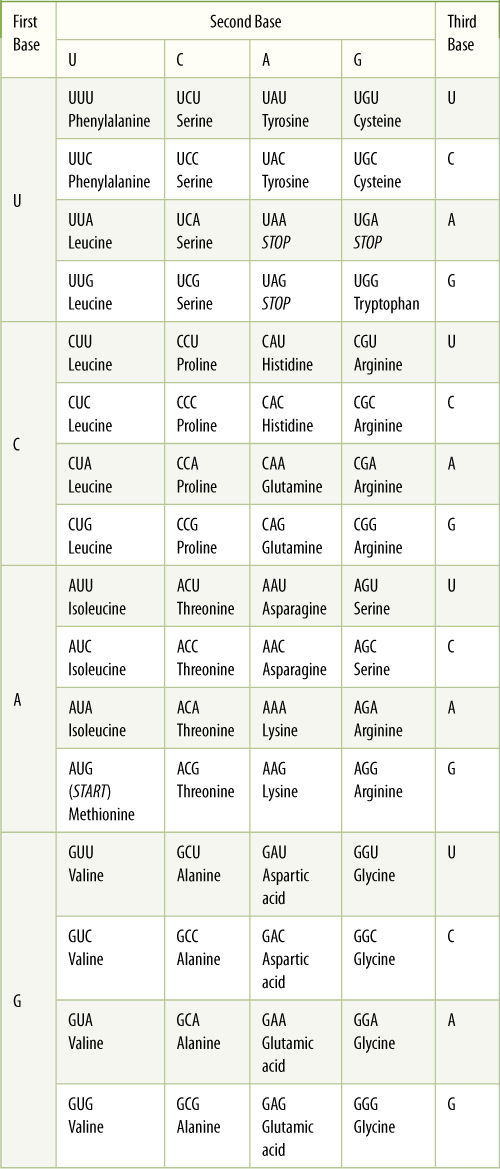
The triplets in mRNA are codons; the DNA triplets in the gene itself are their complements. The first base of the codon is listed on the left and the second base at the top. Within each large box are the four possible third bases and the amino acid specified by each.
Genes are composed of a structural region that actually codes for the amino acid sequence, and a promoter, a controlling region involved in regulating the synthesis of mRNA from the structural region (FIGURE 15-5). The promoter is located “upstream” from the structural region, that is, to the 5' side. It varies in length from gene to gene but can be several hundred nucleotides long. Certain regions are particularly important; one, called the TATA box, is a short sequence about six to eight base pairs long rich in A and T. If the TATA box is damaged by either mutation or experimental treatment, the RNA-synthesizing enzyme RNA polymerase II does not bind well. Most eukaryotic genes have other promoter sequences called enhancer elements located even farther upstream, as many as several hundred base pairs away from the structural region of the gene. When a hormone alters cell metabolism, it does so by producing intracellular chemical messengers that activate genes either by binding directly with the promoter region or by binding with proteins that then interact with the promoter. After activating agents have bound to the promoter, RNA polymerase II can attach.
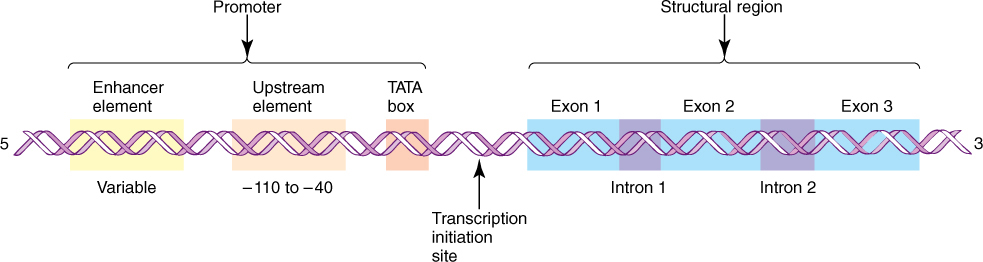
FIGURE 15-5 Carbons in ribose and deoxyribose are numbered from 1' to 5', with phosphate attached to the 5' carbon and the hydroxyl used in polymerization attached to the 3' carbon. Any nucleic acid has a 5' end and a 3' end. A gene is always written with the 5' end, and thus the promoter, on the left. Nucleotides are numbered beginning at the left boundary of the structural region; nucleotides to the left of this are given negative numbers and are said to be upstream. Because DNA is double stranded, its length is measured as the number of nucleotide pairs or base pairs, whereas RNA, being single stranded, is measured as the number of nucleotides or bases.
After RNA polymerase II binds to the promoter, it migrates downstream (toward the 3' end of the DNA strand) toward the structural region; however, it does not create any RNA until it is approximately 20 to 30 nucleotides below the TATA box. The RNA polymerase might be expected to search for the DNA equivalent of the AUG start codon of mRNA, but that is not the case. If some of the DNA is artificially removed between the TATA box and the normal start site, the RNA polymerase begins synthesizing RNA farther downstream than normal.
Like those of prokaryotes, genes of plastids and mitochondria often have multiple promoters, not just one. Plastids use two types of RNA polymerase, one imported from the nucleus and one they make themselves and which is remarkably similar to that of the bacterium Escherichia coli.
The structural portion of genes contains two distinct types of regions: exons and introns. Exons are sequences of nucleotides whose codons are eventually expressed (exon, expressed) as sequences of amino acids in proteins, and introns are sequences of nucleotides that are not expressed, but instead intervene between exons (Figure 15-5 and FIGURE 15-6). Several plant genes have just two or three introns: the gene for RuBP carboxylase and the genes for the storage proteins glycinin and phaseolin of legume cotyledons. The gene that codes for the protein portion of phytochrome has five introns, one of which is 1,500 base pairs long. Genes with 25 introns occur, as do genes with no introns. It is very common for exons to make up much less than half the structural part of a gene.
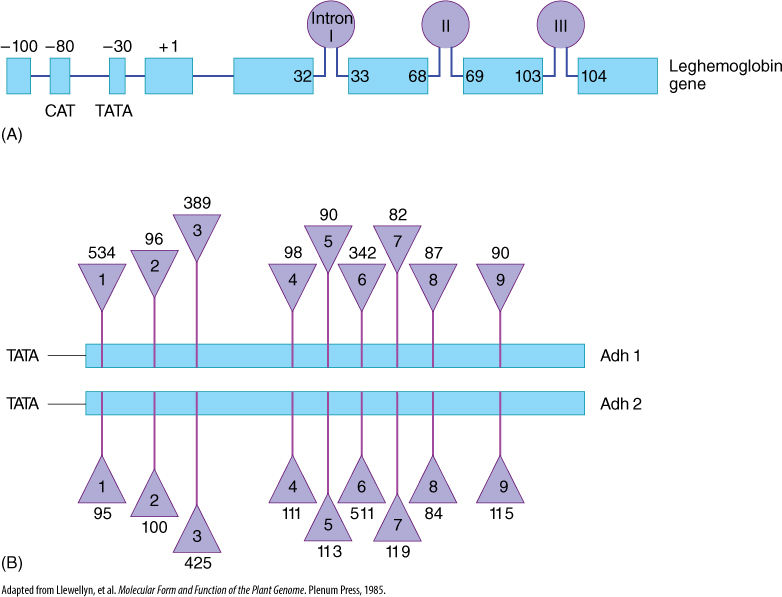
FIGURE 15-6 Two ways of illustrating introns and exons in maps of genes. (A) The gene for leghemoglobin in legumes has three introns: Intron I occurs between bases 32 and 33 of the finished mRNA; intron II between bases 68 and 69, and so on. (B) Two genes in corn produce two similar enzymes, both called alcohol dehydrogenase and distinguished as Adh1 and Adh2. The numbers above and below the triangles indicate the number of bases present in each intron. The two genes are similar, having nine introns located at the same positions; corresponding exons in Adh1 and Adh2 are the same length, but corresponding introns may be quite different. Intron 1 is 534 bases long in Adh1 but only 95 bases long in Adh2.
Transcription of Genes
After RNA polymerase binds and encounters the start signal, it begins actually creating RNA, a process called transcription. The two strands of DNA separate from each other over a short distance, and free ribonucleotides diffuse to the region (FIGURE 15-7). If a ribonucleotide containing cytosine approaches a DNA nucleotide that contains guanine, the two form three hydrogen bonds and remain together, at least temporarily. Wherever DNA contains T, a free A can form two hydrogen bonds to it; similarly, free U forms two hydrogen bonds with A in DNA, and so on with G and C. RNA polymerase binds the free ribonucleotide, holds it, and catalyzes the formation of a covalent bond, forming RNA. As each covalent bond is formed, two high-energy phosphate-bonding orbitals are broken. Polymerization is thus a highly exergonic process that cannot be easily reversed. Free ribonucleotides diffuse to and pair with both strands of DNA, but RNA polymerase is located only on the strand that has the gene; the complementary strand is not read.
Transcription proceeds rapidly, incorporating about 30 ribonucleotides per second, with the DNA double helix unwinding ahead of the moving enzyme. After RNA polymerase moves off the promoter/initiation site, a new molecule of RNA polymerase binds and begins synthesizing another molecule of RNA (FIGURE 15-8). Whereas two molecules of DNA wrap around each other into a double helix, RNA/DNA duplexes do not; the RNA polymer that emerges from RNA polymerase releases from the DNA.
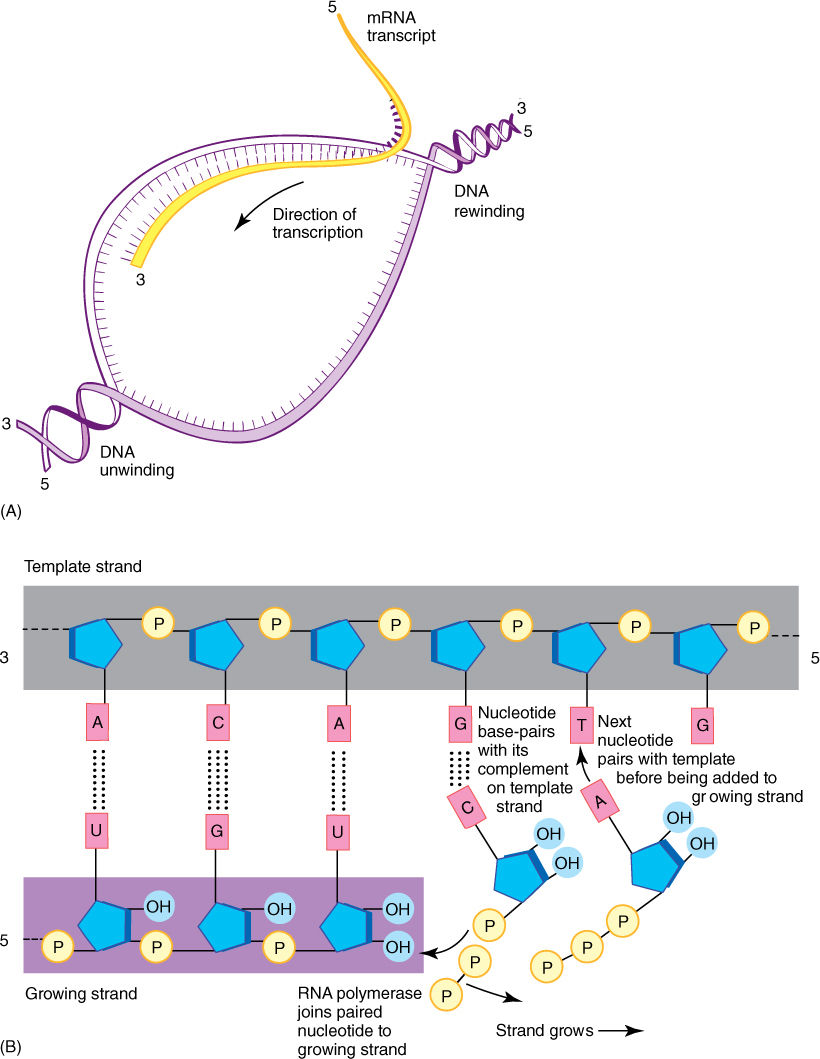
FIGURE 15-7 When a gene is turned on, the DNA double helix separates over a short region (A); free ribonucleotides diffuse in and pair with the region of temporarily single-stranded DNA (B). The formation of two or three hydrogen bonds between the DNA deoxyribonucleotides and the free ribonucleotides allows the DNA sequence to control the sequence of the RNA being formed.
RNA polymerase transcribes both introns and exons into a large molecule of hnRNA (heterogeneous nuclear RNA) that is rapidly modified by nuclear enzymes. Introns are recognized, cut out, and degraded back to free ribonucleotides. Exons are spliced together, resulting in an RNA molecule, all of which codes for amino acids. All RNA destined to become mRNA is somehow recognized by an enzyme that binds to it and attaches a series of adenosine ribonucleotides on its 3' end, forming a poly(A) tail approximately 200 bases long, the only exception being the mRNAs for histone proteins (FIGURE 15-9). Another step in message processing involves changing the first nucleotide into 7-methyl guanosine. Ultimately, a completed mRNA is produced and transported from nucleus to cytoplasm.
RNA polymerase continues to act until it encounters a transcription stop signal in the DNA. The stop signal of several genes consists of two parts. The first is a short series of DNA nucleotides that are self-complementary; that is, the RNA transcribed from them can double back on itself and hydrogen bond to another part of itself. This results in a small kink, a hairpin loop that is believed to affect RNA polymerase. Just downstream of this region of DNA is a long series of adenines. Various protein factors also are involved; in their absence, RNA polymerase sometimes continues transcribing, reading the next region of DNA as if it were also part of the gene.
Plastid and mitochondrial genomes have prokaryotic organization. Their genes are not separated by long stretches of spacer DNA, but instead genes occur in sets, one following another immediately. One set of promoters causes RNA polymerase to transcribe not just a single gene but actually several before it releases. This long, multigene transcript is then processed differently than is hnRNA.
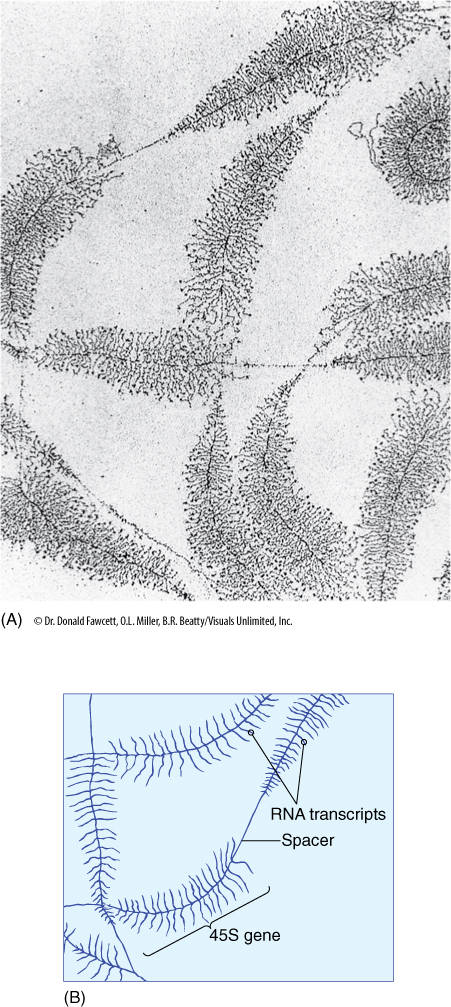
FIGURE 15-8 DNA can be carefully extracted from a nucleus, allowed to spread out, and then prepared for examination in an electron microscope (A). These are ribosomal genes being transcribed into long RNAs that will later be cut into three separate rRNAs. The diagram (B) explains each type of line.
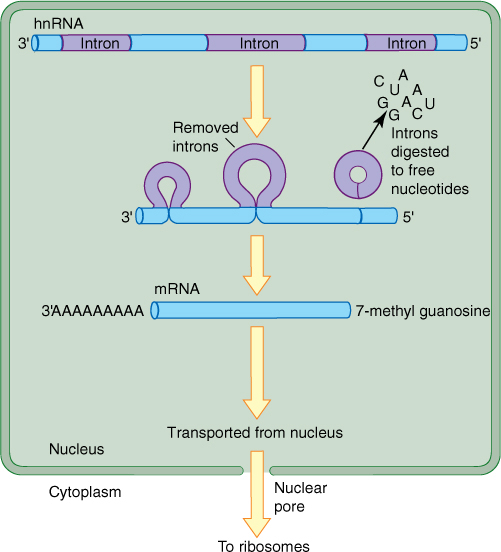
FIGURE 15-9 The primary transcript, hnRNA, has its introns cleaved out and the exons spliced together; the introns are depolymerized back to free nucleotides. An enzyme adds up to 200 adenosine ribonucleotides to the end of the RNA; these are not coded by thymidines in the DNA. The first nucleotide at the 5' end is converted to 7-methyl guanosine.
Protein Synthesis
In the process of protein synthesis, ribosomes bind to mRNA and “read” its codons. Guided by the information in the nucleotide sequence of the mRNA, the ribosomes catalyze the polymerization of amino acids in the order specified by the gene from which the mRNA was transcribed.
Ribosomes
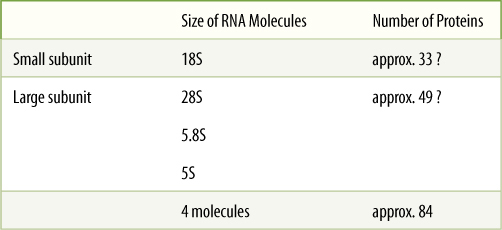
Ribosomes are small particles that “read” the genetic message in mRNA and construct proteins guided by that information. Each is composed of two subunits, one larger than the other, and each is made up of both proteins and ribosomal RNA (rRNA) (FIGURE 15-10 and TABLE 15-3). The small subunit contains one molecule of rRNA, the large subunit contains one molecule each of three types of rRNA. The number of proteins present in eukaryotic ribosomes is known to be greater than 80. Ribosomes found in the cytoplasm of eukaryotes are designated 80S, meaning that they are relatively large and dense; ribosomes of plastids, mitochondria, and prokaryotes are smaller, lighter 70S ribosomes. (S is a Svedberg unit, used to measure the rate at which a particle sediments in a centrifuge.)
The nuclear genes for the three largest rRNAs of 80S ribosomes are unusual because they occur tightly grouped together and act as a single gene with just one promoter (FIGURE 15-11). Transcription of this cluster, which is located in the nucleolus, produces a long RNA molecule that is then cut into three pieces (Figure 15-8). Short regions are digested off the ends of these pieces, resulting in three rRNA molecules. The gene for the smallest rRNA molecule (5S RNA) is not located in the nucleolus but out in the chromatin along with protein-coding genes. These genes are transcribed into rRNA, not mRNA; they do not code for proteins.
TABLE 15-3 Components of 80S Cytoplasmic Ribosomes
Once transcribed, rRNA molecules combine with ribosome proteins in the nucleolus, forming one large particle that then is cleaved into the large and small subunits of a ribosome. These subunits are then transported out of the nucleolus through the nucleus to the cytoplasm.
All cells need large numbers of ribosomes. Most genes are present in a diploid nucleus as only two copies, but just two copies would be inadequate for producing the hundreds of thousands of rRNAs needed. Instead, rRNA genes are highly amplified; that is, many copies of each are present. In flax plants, each nucleus may have up to 120,000 copies of the gene for the small rRNA and 2,700 copies of the gene cluster for the three large rRNA molecules.
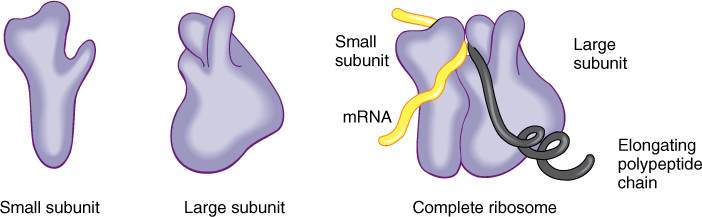
FIGURE 15-10 Ribosomes have two subunits, one large and one small. When they fit together there is a groove for mRNA to pass through, a channel through which the growing protein emerges, and a channel into which amino acid carriers enter.
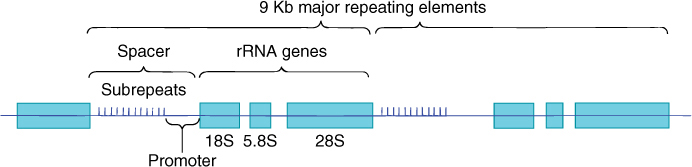
FIGURE 15-11 The genes for the 18S, 5.8S, and 28S ribosomal RNAs occur together as a cluster, separated by short regions of spacer DNA. All three genes are transcribed as just one molecule of RNA, spacers included; spacer RNA is cut out, resulting in three individual rRNA molecules. Upstream from the 18S gene is the promoter and then a region made up of 10 to 15 copies of a short sequence about 135 base pairs long, called subrepeats; they are not transcribed. On either side of the rRNA gene cluster are more rRNA clusters, as many as 2,700, all occurring end to end as a gene “family.” Kb is kilobases; 1 Kb = 1,000 bases.
tRNA
During protein synthesis, amino acids are carried to ribosomes by ribonucleic acids called transfer RNA (tRNA). tRNAs are necessary because a codon cannot interact directly with an amino acid; the genetic code can be read only by a ribonucleic acid that has a three-nucleotide sequence, called an anticodon, that is complementary to and hydrogen bonds to the codon. For example, UUU and UUC are both codons for phenylalanine; the tRNAs that carry phenylalanine have the complementary anticodons of either AAA or GAA. GAA looks backward for something that must bind to UUC; by convention, nucleotide sequences are written 5' to 3', which is GAA. An alternative is to write the numbers to show it is being written backward for easier comparison with the codon: 3'-AAG-5'.
There are as many types of tRNA as there are codons that specify amino acids; stop codons do not have tRNAs. All tRNAs have the same parts, an anticodon and an amino acid attachment site at its 3' end consisting of the sequence CCA (FIGURE 15-12). A special class of enzymes recognizes each tRNA and attaches the correct amino acid to it. This step, called amino acid activation, must be precise. If the wrong amino acid is placed onto a tRNA, it becomes incorporated into the protein as if it were the correct amino acid, causing the protein to have an erroneous structure.
Transfer RNAs contain bases not found in other nucleotides. tRNAs are transcribed from tRNA genes, and like all ribonucleic acids, they contain the common bases A, U, G, and C; however, after these are polymerized into tRNA, enzymes modify some bases to unusual forms (Figure 15-12A).
Each tRNA carries an amino acid only briefly; after it is activated, it rapidly encounters a ribosome that is “reading” the codon complementary to its anticodon. It gives up its amino acid and shuttles back to the cytosol and is reactivated. Even though each tRNA can cycle like this many times per second, millions of tRNAs are needed in every cell, and hundreds or even thousands of copies of each tRNA gene may be present in each nucleus.
The nucleus contains genes for all 61 types of cytoplasmic tRNA, but plant mitochondria have genes for only a few tRNAs and must import the rest from the cytoplasm. Plastids have genes for only about 30 types of tRNA.
mRNA Translation
Initiation of Translation
The synthesis of a protein molecule by ribosomes under the guidance of mRNA is called translation. Protein synthesis begins with a complex initiation process involving the start codon AUG. This codes for the amino acid methionine, but two types of tRNA actually carry methionine, and they have different properties. One, called initiator tRNA, binds to the ribosome small subunit even before any mRNA is present (FIGURE 15-13). Several initiation factors, mostly proteins called eukaryotic initiation factors (eIFs), also bind to the small subunit. In this condition, the complex is competent to bind to mRNA, after which the large subunit of the ribosome binds to the complex and the initiation factors are released. Just how mRNA is recognized is not known, but the initiator tRNA is important for finding the AUG start codon and positioning the small subunit.
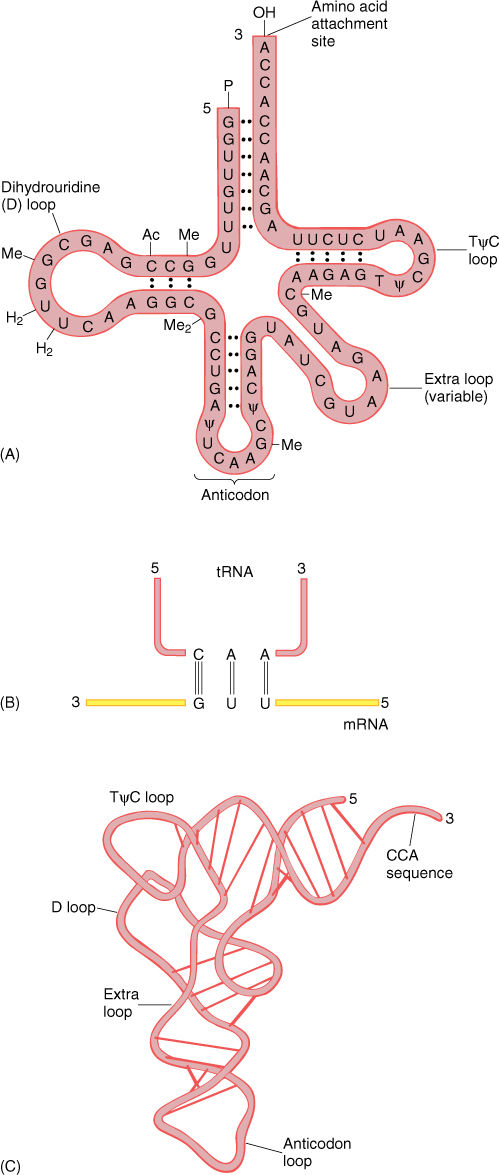
FIGURE 15-12 (A) and (B) All tRNAs have this general shape, with at least three loops caused by self-complementary base pairing. The small fourth loop is present only in some. The anticodon is at the middle loop and the amino acid is attached to the CCA at the 3' end. This is one of the six tRNAs that carry leucine; it has the anticodon CAA, which recognizes the codon 3'-GUU-5', normally written UUG. The unusual symbols (Ac, Me, ψ) indicate bases that are chemically modified into unusual forms. (C) tRNA folds into an L shape rather than lying flat.
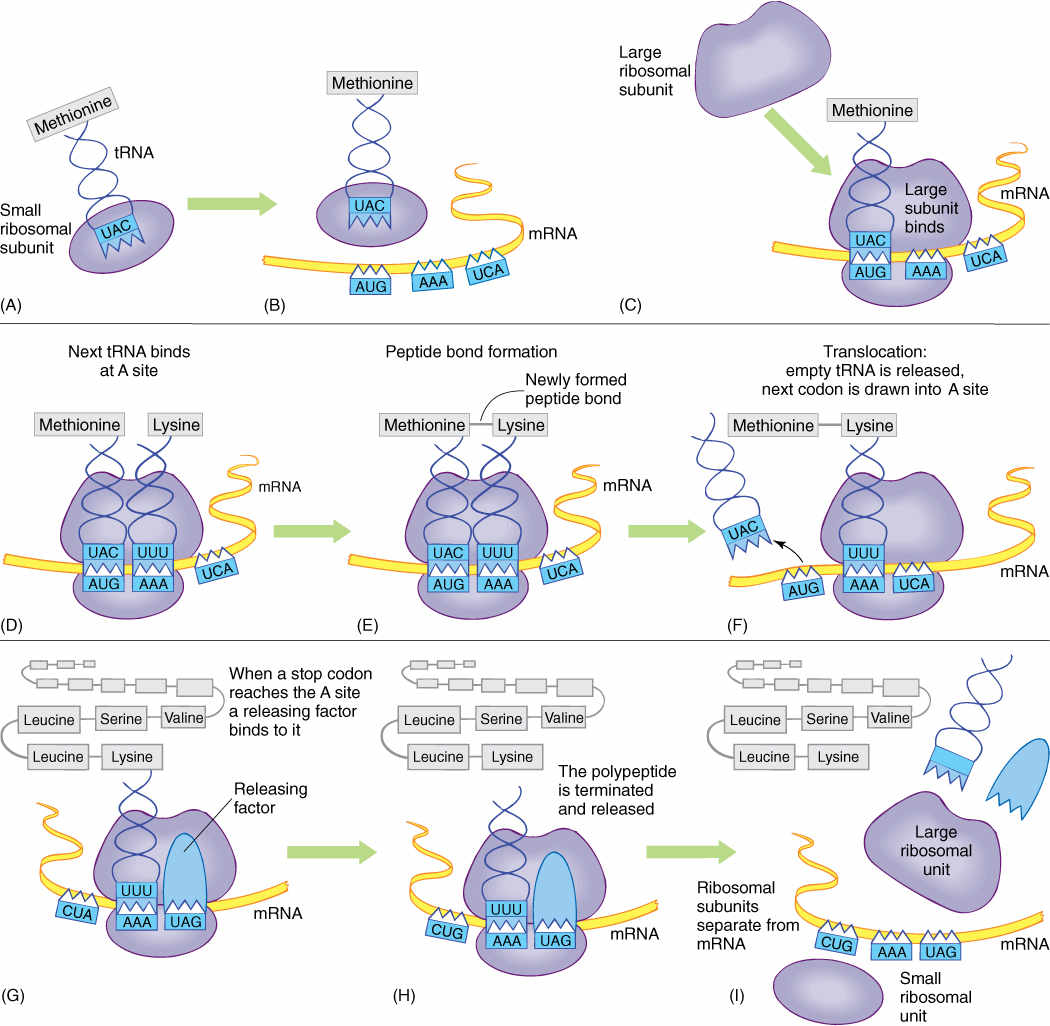
FIGURE 15-13 (A—I) Protein synthesis; the steps are explained in the text.
It is critically important that the ribosome be properly aligned on mRNA because the sequence of nucleotides can be read in any set of three. The sequence CUUGCACAG can be read as CUU GCA CAG and would code for leucine alanine glutamine (FIGURE 15-14), but if the ribosome binds incorrectly, shifted downstream by one nucleotide, the mRNA is read as _ _ C UUG CAC AG _, the codons for phenylalanine histidine and either serine or arginine, depending on the next nucleotide. Reading nucleotides in the wrong sets of three is a frameshift error; because virtually all codons are misread, frameshift errors typically result in completely useless proteins.
Elongation of the Protein Chain
mRNA lies in a channel between the two ribosome subunits. Extending outward from the mRNA channel are two grooves, each wide enough for a tRNA to fit into it such that the tRNA anticodon can touch an mRNA codon. When both channels contain activated tRNAs, adjacent codons are being read (Figure 15-13).
Plants and People
BOX 15-1 Genetic Engineering and Evolution
An important area of genetic engineering is the production of herbicide-resistant crop plants. The concept is to engineer plants that are not harmed by an herbicide, such that fields of the plant can be sprayed with the herbicide to kill weeds without harming the crop itself. There are arguments for and against the basic idea of using herbicides rather than using organic gardening, but for the moment, let us consider just the genetic engineering aspect.
An extremely effective herbicide called glyphosphate became available in the 1970s (sold with the trade name Roundup). Glyphosphate has many favorable features. First, it inhibits an enzyme necessary for the synthesis of three aromatic amino acids (tyrosine, tryptophan, and phenylalanine); this alone would make it deadly by blocking protein synthesis due to missing amino acids. In addition, however, these amino acids themselves are used in other essential plant pathways, and thus, glyphosphate is especially lethal. Second, the enzyme that it inhibits occurs only in plants; animals do not have this enzyme (animals must obtain these amino acids in their diet), so being exposed to glyphosphate does not harm animals. Third, glyphosphate rarely pollutes water because it binds so strongly to soil that it does not wash into ground water or streams. In fact, it is applied by spraying it onto leaves rather than mixing it with soil. Finally, it breaks down quickly into harmless products.
The one drawback of glyphosphate is that it kills all plants. It can be applied to fields only before the crop seeds germinate, killing weeds that germinated before the crop did, or if crop plants are tall and weeds are short, it can be sprayed below the crop’s leaves and onto the weeds’ leaves.
Genetic engineering entered the picture when it was discovered that bacteria have a gene called CP4 that synthesizes the three amino acids but is immune to glyphosphate. Plant scientists isolated the gene and genetically engineered soybeans to use this gene in addition to the natural plant gene. These soybeans would not die if sprayed with glyphosphate. An entire field of these soybeans could be sprayed at any time to kill weeds without harming the crop. Currently, glyphosphate-resistant alfalfa, canola, cotton, corn, and sugar beets have been genetically engineered (such plants are often called genetically modified [GM] plants). This is so effective that many farmers have stopped using other herbicides and rely on glyphosphate. An added benefit is that they do not have to plow their fields before planting; plowing inhibits weeds by burying their seeds deeply; however, it loosens soil so much that it greatly increases erosion, and it requires large amounts of fuel.
The extensive use of a potent herbicide like this creates a strong selection pressure for resistance among other plants: Any weed that has a mutation that makes it resistant to glyphosphate will thrive in a field with fertilizer, irrigation, pesticides, and no competition from other weeds. People thought it would be almost impossible for resistance to evolve because the plant enzyme is so fundamental. How could an entire new enzyme or whole new pathway evolve in a short period of time? But glyphosphate-resistant weeds have appeared already in many parts of the world, and not because they have a new enzyme. Instead, plants are variable in their capacity to transport glyphosphate through phloem. Most transport glyphosphate throughout their body, and it accumulates in shoot and root tips, stopping growth. But a small number of plants have something different about their phloem (we do not know what) that causes them to transport glyphosphate to leaf tips—it harms the leaf tips but does not hurt the rest of the plant. In natural environments, this unusual transport may not help the plant at all, but it is extremely beneficial in a field being sprayed with glyphosphate. Glyphosphate did not cause glyphosphate resistance to come into existence; this feature would have been present already in a naturally variable population of plants. It is just that these plants suddenly are more adapted because glyphosphate is being used in their environment; they will become a greater part of their population as susceptible plants are killed.
Other types of resistance should be expected. It may be that plants already exist that have degrading enzymes that can break glyphosphate down or that have membranes that are impermeable to it. The continued use of glyphosphate will give these plants a selective advantage, and their numbers will increase. It is a simple, clear-cut case of evolution by natural selection.
This experience should remind us that plants and evolution can respond in numerous ways, many of which we might not anticipate. Other areas in which GM crops are being produced and where we might want to be cautious are drought resistance and insect resistance. Plants have already been genetically engineered to require less water for their survival. They require less irrigation, so less water can be diverted from rivers and lakes, which would then retain more of their natural condition. Would seeds of drought-resistant crop plants then be able to invade natural, dry areas and become invasive pests on their own, crowding out the natural plants? A potent insect-killing protein is produced by the bacterium Bacillus thuringiensis; it is easy to transfer that gene into plants, creating plants that resist insects. The gene, however, is also expressed in pollen of genetically modified plants, and poisonous pollen blows away, especially from corn fields, landing on the leaves of other plants, coating them with a poisonous “dust” that could harm any kind of insect.
As is so often the case, advances in technology bring with them both benefits and risks. By analyzing each opportunity for its merits and dangers, we should be able to increase our quality of life without harming the environment, but we must always remember that we are dealing with organisms that can evolve and respond to the altered conditions we are creating.
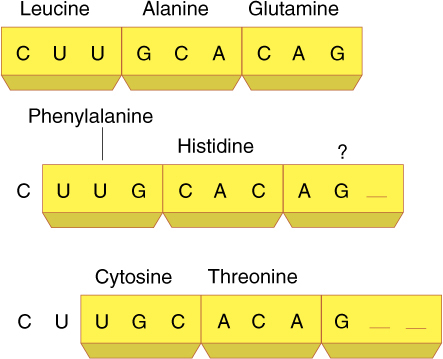
FIGURE 15-14 Because there are no spacers between codons, the ribonucleotides can be read in three possible ways. Each results in completely different proteins, only one of which has the proper primary structure.
At the time of initial binding, the small subunit already contains initiator tRNA in the P channel (P for protein). The adjacent A channel (A for amino acid) is empty, but numerous molecules enter it at random. Some are activated tRNAs, but if their anticodons do not complement the exposed codon at the bottom of the A channel, they diffuse out. If a tRNA with the proper, complementary anticodon enters, hydrogen bonds form between the codon and the anticodon. This holds the tRNA in place long enough for an even more stable binding to occur. Enzymes located in the large ribosomal subunit break the bond between the methionine and its tRNA in the P channel, simultaneously attaching the methionine to the amino group of the amino acid on the tRNA in the A channel. This reaction needs no outside source of power: The broken bond is a high-energy bond, whereas the newly formed peptide bond is only a low-energy bond.
The empty tRNA, freed of its methionine, is released from the P channel, and the ribosome pulls itself along the mRNA for a distance of three nucleotides. This movement is powered by GTP and seems to be performed by proteins on the large subunit. As the ribosome slides along the mRNA, the A channel slides to the next codon, and the tRNA with the two amino acids attached becomes surrounded by the P channel, not the A channel. When the proper activated tRNA diffuses into the A channel and hydrogen bonding between codon and anticodon occurs, the large subunit enzymes again release the short protein chain (now two amino acids long) from the tRNA in the P channel and attach it to the amino acid on the tRNA in the A channel, creating a protein three amino acids long. This process repeats until the ribosome reaches a stop codon.
Termination of Translation
When a stop codon is pulled into the A channel, normal elongation cannot occur; no tRNA is present with an anticodon complementary to a stop codon. Instead, a release factor enters the channel and stimulates the large subunit enzymes to initiate the normal reactions. The high-energy bond holding the protein to the P-channel tRNA is broken, and a new bond is formed with water, releasing the protein from both the tRNA and the ribosome. The tRNA is released, and the small subunit disassociates from the large subunit and releases the mRNA. All components diffuse away, but as soon as the small subunit encounters an initiator tRNA and other initiating factors, it binds to another mRNA and the process begins again.
In summary, protein synthesis involves the following steps: RNA polymerase transcribes hnRNA, being guided by the sequence of DNA nucleotides in a gene. The hnRNA is processed into mRNA as introns are cut out and exons are spliced together. After moving from nucleus to cytoplasm, mRNA binds with ribosomes, and tRNAs carry amino acids to the ribosome-mRNA complex. The ribosome translates the mRNA codon by codon, and tRNAs fit into the ribosome only when their anticodon is complementary to the codon in the A channel. After the protein is completed, it is released and the ribosome subunits detach from the mRNA. All components diffuse away from each other, but the ribosome subunits can translate the next mRNA they happen to meet. The mRNA can be translated again by other ribosomes.
![]() Control of Protein Levels
Control of Protein Levels
As cells undergo differentiation and morphogenesis, their metabolism and structure become different from those of other cells because of the presence of proteins, especially enzymes, unique to that cell type. A central question in developmental biology is the mechanism by which distinct cell types control the activities of genes so that they undergo the proper differentiation and obtain the proper set of proteins. There are several points at which protein synthesis and activity theoretically could be controlled: making a gene physically available for transcription; nature of the promoter region; processing of hnRNA into mRNA; transport of mRNA from nucleus to cytoplasm; binding of mRNA to the ribosome small subunit; rate of translation; processing of protein, and activation or inactivation of the protein.
Many enzymes and structural proteins are present in a cell in an inactive form. Tubulin is an excellent example: A cell may contain a large pool of tubulin monomers and then aggregate them into microtubules at a specific time. Microtubules can appear rapidly without the need for gene activation or protein synthesis. Similarly, enzymes are often completely inactive until phosphate groups are added by a class of enzymes, called kinases, that are themselves activated by the arrival of hormones. Hormones arrive at the plasma membrane and bind to receptors, which then synthesize second messengers that enter the cell. These activate the phosphorylating enzymes that in turn activate the dormant enzymes, leading to a significant change in the cell’s metabolism. This is mostly an activating rather than a differentiating mechanism; these cells are already prepared for highly specific responses.
It would be extremely inefficient if a cell transcribed all its genes and synthesized all of its possible proteins when only a few are needed. For maximum efficiency, a cell should not even synthesize the mRNA for proteins it does not need. We expect that the most fundamental level of control of morphogenesis would occur at the level of transcription.
We know very little about control of transcription in eukaryotes, especially plants, but our knowledge is increasing rapidly. In many cases, gene activity is controlled by transcription factors, proteins that bind to promoter or enhancer regions and activate genes. Many transcription factors have a sequence of amino acids that fits into the large groove of a DNA double helix, recognizing a specific sequence of nucleotide bases. Interestingly, most transcription factors must act as dimers: Two similar factors first recognize each other, and only then can they bind to the proper promoter. By acting as dimers, a moderate number of transcription factors can control a very large number of genes; for example, three proteins A, B, and C can form six dimers: AA, AB, AC, BB, BC, and CC. The binding of transcription factors to DNA creates a structure to which RNA polymerase can bind. Many transcription factors can be classified together based on their overall structure: “Helix-turn-helix” transcription factors have two regions of α helix (part of their secondary structure) joined by a looping section of protein; in “basic leucine zipper” transcription factors, the two parts of a dimer are held together by interactions of leucine amino acids on their surfaces, and so on.
Because transcription factors come from somewhere else and bind to DNA, they are said to be transacting factors; promoters, enhancers, and TATA boxes are part of the gene itself and thus are cis-acting factors.
Gene expression is also controlled by a family of short RNA molecules called micro-RNAs. Many types of micro-RNAs are now known, and there is a large number of names as well; however, each name ends in -RNA, so they are easy to recognize when you read about them. These short pieces of RNA act in many ways, some recognizing sites on DNA itself and binding there, and others recognizing sites on hnRNA or mRNA and attaching to those molecules. In many cases, binding by micro-RNAs inhibits gene expression or mRNA translation. Because RNA consists of nucleotides, it has the potential to recognize sequences in DNA and RNA very precisely and thus exert precise control over gene action.
![]() Analysis of Genes and Recombinant DNA Techniques
Analysis of Genes and Recombinant DNA Techniques
Nucleic Acid Hybridization
The two halves of a DNA double helix can be separated by heating them just enough to break the hydrogen bonds between complementary bases. This separation, which produces a solution of single-stranded DNA molecules, is called both DNA melting and DNA denaturation. If the solution of single-stranded DNAs is cooled slowly to a temperature low enough for hydrogen bonds to reform, two molecules with complementary sequences form hydrogen bonds and stick together whenever they collide. If the two halves of one piece encounter each other, all of their bases pair and adhere firmly even at a relatively high temperature (FIGURE 15-15A, B, and C), but just by chance, many pieces have short sequences that are complementary, whereas most of their sequences are not. If these encounter each other, they form only a small number of hydrogen bonds and probably fall apart again if the mixture is cooling only slowly (Figure 15-15A, B, and FIGURE 15-15D). As the degree of complementarity decreases, the stability of pairing decreases.
The reformation of double-stranded DNA by cooling a solution of single-stranded DNAs, called both DNA hybridization and reannealing, is used to determine the relatedness of two types of DNA. For example, DNA can be extracted from two organisms, cut into small pieces, and melted. The sample from one is attached to a filter, and the other sample, which has been made radioactive (or fluorescent), is poured over it at a temperature that permits hybridization. If the two organisms are related, a large amount of the radioactive DNA hydrogen bonds firmly to the DNA on the filter, so the filter becomes very radioactive. If the two species are not closely related, they have so few sequences in common that few hydrogen bonds form, and most of the radioactive DNA pours through; therefore, the filter does not become radioactive.
This method is also used to measure the number of copies of a gene that occurs in a nucleus. It had always been assumed that any diploid nucleus contains two copies of every gene, one from the paternal parent and one on the homologous chromosome inherited from the maternal parent. If such DNA is broken into small pieces, denatured, and allowed to cool, the reannealing is extremely slow. Of the hundreds of thousands of pieces, each has only two that can pair with it—its own that had melted away from it and one from the homologous chromosome. Thus, each piece undergoes thousands of collisions before its complement is encountered and stable reannealing occurs. Although most genes do act this way and reannealing is extremely slow, a portion reanneals very rapidly, seeming to encounter complementary pieces easily, as if thousands of the same gene occur. These are genes for rRNA and tRNA, which have thousands of copies in each nucleus.
Restriction Endonucleases
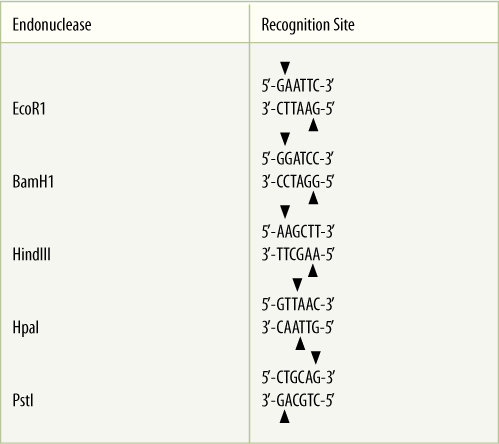
Natural DNA is such a long molecule it cannot be worked with easily. It can be broken into smaller pieces by chemical treatment or simply by agitating a solution violently (FIGURE 15-15E). When breaking it into fragments of a more manageable size, it is often critical to cut it at specific known sites so that repeat experiments can yield the same pieces as the first experiment. Before the 1970s, this was impossible; both chemical treatment and agitation cut DNA at random, and no two experiments ever yielded the same pieces of DNA. Then a class of bacterial enzymes, restriction endonucleases, was discovered. Each restriction endonuclease recognizes and binds to a specific sequence of nucleotides in DNA and then cleaves the DNA (TABLE 15-4). Because of these properties, we always know exactly where DNA will be cut by a particular restriction endonuclease, and when two identical batches of DNA are treated with the same restriction endonuclease, the resulting fragments are always the same.
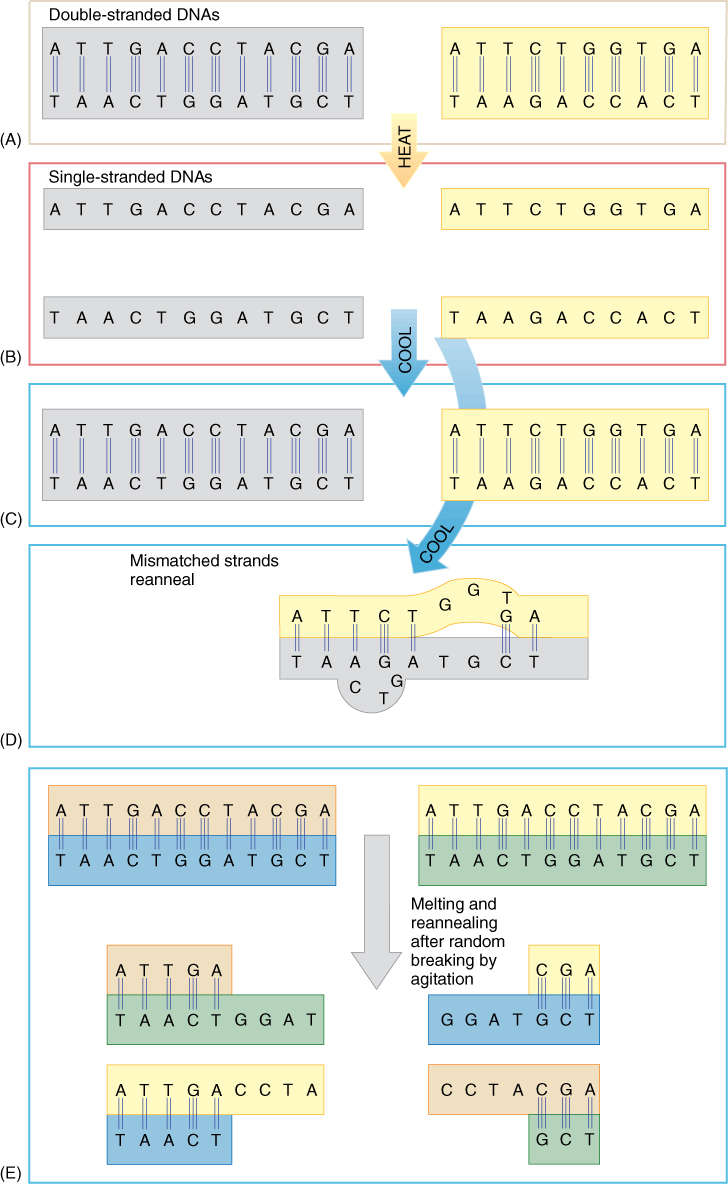
FIGURE 15-15 (A) and (B) Mild heating of DNA disrupts hydrogen bonding, allowing the two halves to separate into single-stranded molecules. (B) and (C) Cooling allows them to reanneal. (B) and (D) In the millions of nucleotides in a single DNA molecule, short sequences occur many times simply by chance, so almost any two pieces have a few short complementary sequences; however, much of the sequences are mismatched and do not adhere. The poorly bonded DNA duplexes fall apart if the solution is still warm, giving each piece another chance to encounter its true complementary partner. (E) If two identical pieces of DNA are broken at random, each produces pieces perfectly complementary to those produced by the other, but because the pieces are unequal in length, a large amount of single-stranded DNA remains after allowing them to reanneal.
The sequence recognized by a restriction endonuclease is present in both strands, running in opposite directions; such sequences are palindromes. The sequence can be read “forward” or “backward,” depending on the strand. Also, because most restriction endonucleases cut each DNA strand near the ends of the palindrome, the two cuts are not aligned. Each end is complementary to and capable of pairing with any other end made by that type of restriction endonuclease; the ends are said to be “sticky” (FIGURE 15-16). Currently, more than 3,000 restriction endonucleases have been discovered, and 600 are commercially available, giving us a large choice of cleavage sites.
TABLE 15-4 Sites Recognized by Restriction Endonucleases
All fragments produced by a particular class of restriction endonucleases have exactly the same sequence in their single-stranded ends. Thus, if fragments made from the DNA of one organism are mixed with those of another organism, they adhere to each other. A DNA repair enzyme, DNA ligase, can be added to the mixture to repair the cuts so that the two fragments join together. DNA prepared by this method is recombinant DNA.
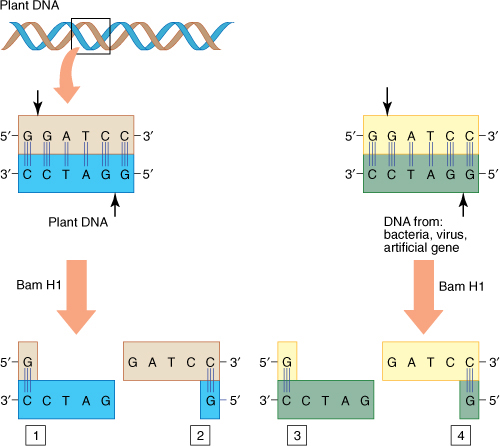
FIGURE 15-16 Most restriction endonucleases cut near the ends of palindromes, resulting in pieces with sticky ends. DNA pieces from different sources can be mixed together and tend to adhere, making it much simpler to work with them. Both pieces 1 and 3, even though from different organisms, have the same sequence at their ends because Bam H1, like all restriction endonucleases, binds to and cuts the DNA only if it finds a particular sequence. The same is true of pieces 2 and 4.
Identifying DNA Fragments
Evolutionary Studies
After restriction endonucleases have acted, the DNA fragments can be identified and used. Most simply, fragments are used directly to study the evolution of DNA. For example, plastid DNA is a small molecule containing only 60,000 to 80,000 base pairs. Treatment with the Pst I restriction endonuclease produces about 10 to 20 fragments. These can be separated by gel electrophoresis and then made visible by staining, producing a restriction map of the plastid DNA (FIGURE 15-17). The number of fragments reveals the number of Pst I sites and the number of base pairs between them in the plastid DNA. If plastid DNA is extracted from the chloroplasts of a second, closely related species, it should have the same number of Pst I sites and the same spacing between them as in the first species. If two species are not closely related, their fragment profiles differ: There is a restriction fragment length polymorphism (RFLP). A mutation may have altered one of the Pst I sites so that Pst I neither recognizes nor binds to it. If so, one less fragment is present, and one of the remaining fragments is extra long. Conversely, a mutation may have altered an ordinary sequence, converting it to a new Pst I site and thus producing an extra fragment. In addition, two species may have equal numbers of fragments, but with a fragment that is longer in one species than the corresponding fragment in the other: A mutation has added extra base pairs to one species or removed some from the other. RFLP analysis is easy, quick, and inexpensive, and it can be done with various restriction endonucleases, each providing its own information about how much change has occurred in the DNA.
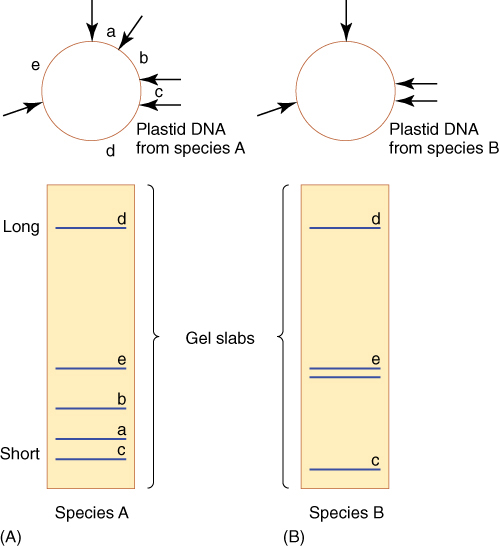
FIGURE 15-17 (A) Plastid DNA from species A can be cut with a particular restriction endonuclease, resulting in several pieces that can be identified by gel electrophoresis. The enzyme digest is placed on a gel slab and a voltage is applied. Phosphate groups on the nucleotides cause the pieces to move in the electrical field, and the shortest DNA pieces slip quickly through the gel matrix, thus moving the farthest. The largest DNA pieces can barely move through the gel; therefore, they stay at the top. After staining, the gel reveals the number and length of pieces. Here, we have indicated which band on the gel corresponds to each position in the plastid DNA circle, but you would not know that from this type of experiment. (B) In a closely related hypothetical species B, a mutation has changed a nucleotide between a and b so that that region does not have the proper sequence for the enzyme, so no cutting occurs. Electrophoresis shows that the two species have three bands in common and that species B has one band as long as the combined length of the missing two.
For further analysis, some or all fragments can be sequenced; that is, the identity of every nucleotide can be revealed in order by techniques described below. Similar analyses can be performed with mitochondrial DNA, but mitochondria are used more often in studies of animals and fungi. For plant studies, plastid RFLP analysis is more convenient. Nuclear DNA cannot be used easily because there is too much of it; it produces thousands of fragments, and the addition or loss of a few cannot be detected.
Physiological Studies
In many cases, the objective of the experiment is to locate and isolate one particular fragment, such as the one that contains a specific gene. The following method can be used if any cell forms large quantities of the protein; for example, developing cotyledons of legumes such as beans and soybeans produce large amounts of the storage proteins phaseolin and glycinin, respectively. While the cells are actively synthesizing the protein, ribosomes can be extracted from them and mRNA obtained. The mRNA can be mixed with reverse transcriptase, a virus enzyme that synthesizes DNA using RNA as a template (FIGURE 15-18). This complementary DNA (cDNA), is complementary to the exons of the gene. It is synthesized using fluorescent nucleotides; it can then be placed on the various DNA fragments produced by the restriction endonuclease treatment of nuclear chromatin. The cDNA forms hydrogen bonds to whichever fragment contains the gene, and this bonding can be detected by assaying for the fluorescence. The gene itself may contain a restriction site so that it is cut in two and separated into two fragments; the fluorescent cDNA probe hybridizes with both fragments. If this happens, the experiment may have to be repeated with other restriction enzymes that do not cleave inside the gene itself. The best enzyme can be found only by trial and error. Few cells in plants, other than those in cotyledons, produce large amounts of just one protein; as a result, most cells contain hundreds of types of mRNAs, and it is not possible to know which one codes for the protein of interest. Reserve proteins of seeds, however, are some of our most significant, important foods, and hundreds of billions of dollars are spent every year buying storage proteins in the form of beans, wheat, corn, and soybeans. These significant proteins are the objects of intensive study and genetic manipulation.
A second method can be used if mRNA is difficult to obtain, but something is known about the amino acid sequence in the protein, even just a little of it. If the sequence of 5 to 10 amino acids is known, the genetic code in Table 15-2 can be used to guess the probable sequence of nucleotides in the corresponding exon. For example, if the known protein sequence contains phenylalanine, the exon may contain either UUU or UUC. After two or three probable nucleotide sequences have been chosen, they can be synthesized by machines that produce DNA in the form of a radioactive probe. This is used to detect which fragment contains the complementary sequence.
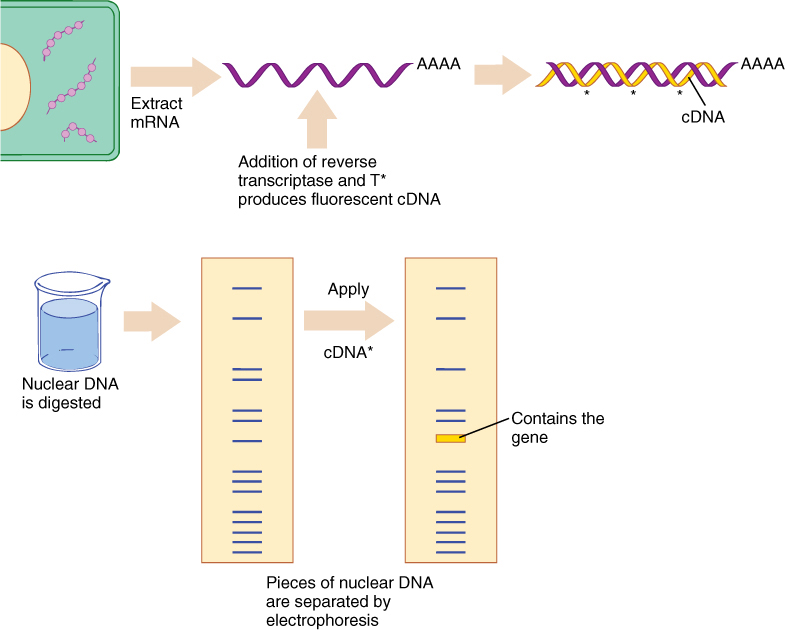
FIGURE 15-18 The method for isolating a particular piece of DNA that contains a gene of interest. T* indicates fluorescent thymidine; the gel slab contains fragments made from restriction endonuclease treatment of nuclear DNA. The method is described in the text.
If neither of these approaches is possible, all of the restriction endonuclease fragments from the plant are modified and mixed with bacteria. The bacteria take up the fragments; some take up many; others absorb one, and some take up none. In many cases, the plant DNA is digested by the bacterium’s own restriction endonucleases, but often it is incorporated into the bacterium’s DNA and replicated. The bacteria are spread over dozens of Petri dishes, and every bacterium grows into a small colony. Each colony is tested to see if it is making the protein of interest. Any colony that is producing the protein must be replicating the gene as well as transcribing and translating it. That colony can be transferred to a new Petri dish and grown. Then DNA is isolated from some of its members and is treated with the same restriction endonuclease that was used to obtain the original plant fragments. At least one fragment of the bacterial digest should match in size one fragment of the plant digest; that fragment contains the gene.
It is not possible to compare each of the dozens of bacterial fragments with the tens of thousands of fragments from the original plant material, but that is no longer a problem. Genetically modified bacteria are used, and we know every type of fragment that the bacterial DNA will be digested into when treated with any restriction endonuclease if it has not picked up foreign DNA from our experiment. Any fragment that does not match the maps of the bacterial DNA must correspond to the plant fragment that was introduced.
Expression profiling uses cDNAs to examine gene expression during development or to compare development in one species with that in another. For example, all mRNA can be extracted from a young leaf primordium and converted to cDNA; then each type of cDNA is separated from the others. Each type is attached to many glass microscope slides in an orderly matrix, a DNA microarray: Each slide will have thousands of microscopic dots, each dot being a different cDNA and each slide being identical to all other slides (FIGURE 15-19). Then mRNA is extracted from an older leaf primordium and placed onto one of the slides such that each mRNA can find and bind to the spot that has its cDNA. Excess mRNA is washed off, and chemicals are added to detect DNA/RNA pairs; then the slide is examined to see which spots have picked up mRNA. Spots that have no mRNA bound to them correspond to genes that became inactive as the leaf developed from the younger to the older stage. Similarly, mRNA from flower petal primordia might be added to another slide to see which genes are active in both leaf and flower primordia. This does not tell us what the genes are or even their sequence, but by examining microarrays, we can study general gene expression patterns.
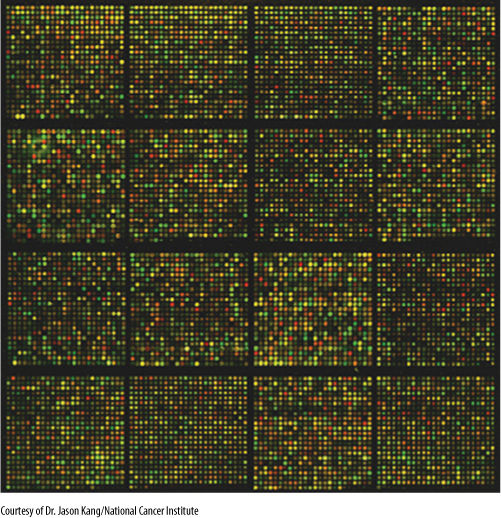
FIGURE 15-19 DNA microarray. See text for details.
DNA Cloning
The method of placing DNA fragments into bacteria, as just described, is an extremely useful technique of DNA cloning. The colony that contains the important fragment can be subcultured and grown easily, and each time a bacterium divides, a new copy of the experimental DNA fragment is made. The bacteria can be cooled, induced to become dormant, and stored for years. When the gene is needed again, the bacteria are revived and cultured. As long as the proper restriction endonuclease is used, the gene can be obtained easily.
Placing the original plant DNA fragments into bacteria is much easier than it may seem. Fragments are not simply mixed with bacteria, but are typically combined with plasmids or virus DNA. A plasmid is a short, circular piece of DNA that occurs in bacteria and acts like a tiny bacterial chromosome. Plasmids can move from one bacterium to another and are readily taken up from solution by bacteria. Recall that many restriction endonucleases cut DNA near the ends of a palindrome, resulting in sticky ends. If the plasmid or virus DNA is cut with the same enzyme used to isolate the DNA fragment from the plant, then when the two batches of DNA are mixed, some of the plant DNA adheres to plasmid DNA by means of their complementary ends. DNA ligase is then added to bond the pieces covalently into one continuous double helix (FIGURE 15-20).
Several plasmids, such as pBR322, have been genetically engineered to be ideal DNA fragment vectors (carriers). In their current highly modified form, they have factors that allow them to enter bacteria readily and be replicated. They have antibiotic resistance genes, and they have single sites for several restriction endonucleases so that fragments can be incorporated in precisely known positions. After the fragment is added, the plasmid is mixed with bacteria and absorbed. After a few hours, all bacteria are treated with the appropriate antibiotics; those that did not absorb a plasmid die. The survivors have the plasmid and therefore DNA fragments from the original plant digest.
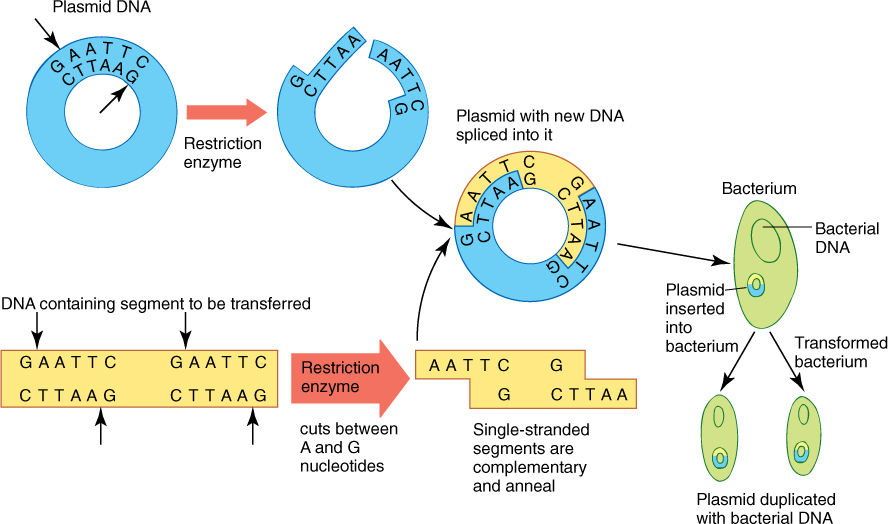
FIGURE 15-20 The method by which a plasmid is used to insert plant DNA into a bacterium for cloning. A virus could be used instead of a plasmid. The method is described in the text.
Several viruses are being used like plasmids; they contain a short fragment of DNA and can infect bacteria and then replicate. As with plasmids, certain viruses have been modified into highly efficient vectors for genetic engineering.
Genetically modified bacteria are easy to culture and handle in the laboratory, but because their genomes are short circles, they cannot accept long fragments of DNA for cloning. Most plant chromosomes are hundreds of times larger than a typical bacterium, and thus, even a short chromosome from a plant nucleus would have to be cut into thousands of fragments for cloning in bacteria. Yeast artificial chromosomes (YACs) can be used instead. A YAC contains the essential parts of a yeast chromosome (telomeres, a centromere, replication start sites) plus a gene for drug resistance and parts of plasmid that can accept experimental DNA cut with the proper restriction endonuclease. Such a YAC is tiny and thus has room for a very large amount of DNA—up to 1 million base pairs—to be cloned. After the experimental DNA is inserted, the YAC is placed into a yeast cell, which is much larger than a bacterial cell and can hold more DNA. The yeast cell is then cultured and allowed to grow and multiply. Every time the yeast cells replicate their own chromosomes, they also replicate the YAC. The yeast can be cultured until billions of cells (and billions of YACs) are present, and then some can be used to obtain the cloned DNA; the rest can be frozen indefinitely for use later.
The Polymerase Chain Reaction
A powerful technique for DNA cloning is the polymerase chain reaction (PCR), in which only enzymes, not living bacteria or yeasts, are used. The sequence to be amplified is heated to separate the two strands of the helix; after cooling, DNA polymerase is added, and it replicates both strands of DNA. This enzyme can add nucleotides only to a preexisting nucleic acid; therefore, before the replication can begin, it is necessary to add two types of primer DNA, each complementary to a short region at either end of the sequence to be cloned. End sequences are known if closely related genes are being studied, but often no part of the nucleotide order is known. In that case, artificial DNA—usually a short sequence such as AAAAAA—is added chemically to both ends; then the primer TTTTTT will be effective.
After the primer has hydrogen bonded to the sequence, a molecule of DNA polymerase attaches and begins working toward the other end. After replication is completed, the mixture is heated temporarily to separate the two strands; then the process is repeated. A heat-stable enzyme, Taq polymerase extracted from hot springs bacteria, is used because it is not denatured by the heating.
After each heating/replication cycle, there are twice as many copies of the sequence being amplified. Consequently, extremely small amounts of DNA can be cloned very rapidly, and PCR is used for rare copies of DNA. Examples are small amounts of cDNA made from the mRNA of just a few cells, as well as the DNA present in the early stages of viral infection (HIV, which causes AIDS, is detected very early with PCR) or the DNA present in a hair, a drop of blood, or a bit of skin at the scene of a crime.
DNA Sequencing
Various methods are currently used to sequence DNA. In the chain termination method, DNA to be sequenced is first cloned to obtain a large sample and is then divided into four batches. To each batch are added all the enzymes and free nucleotides necessary to carry out DNA duplication. To one tube a small amount of dideoxyadenosine is also added. A dideoxynucleotide can be added to a growing DNA; however, it cannot react any further, and the growth of the DNA stops. Nucleotides cannot be added to it. In this tube with dideoxyadenosine, the DNA acts as a template and replication begins; when a T is reached in the template molecules, a few incorporate a dideoxyadenosine and stop. Most growing DNA strands incorporate a normal A and keep on growing; then a few stop at the next T, a few more stop at the next, and so on. When the reaction is complete, the test tube contains thousands of DNA molecules of hundreds of sizes, but each size corresponds to the point where a T occurred in the template DNA being analyzed. Similarly, the second test tube contains a small amount of dideoxy T, the third dideoxy C, and the fourth dideoxy G (FIGURE 15-21).
Until the last few years, the method of analyzing the results was as follows. When all four batches are finished, they are loaded into separate lanes in a gel electrophoresis apparatus and allowed to separate, as in Figure 15-17 and FIGURE 15-22. Each lane contains bands corresponding to the sizes of the DNA molecule. For example, if the DNA contained T as the third, seventh, eighth, and fifteenth base, the lane containing dideoxyadenosine has bands corresponding to DNAs that are 3, 7, 8, and 15 nucleotides long. The DNA sequence can be read immediately (Figure 15-22). At present, gels are almost never used; instead, all processing of DNA samples is now done by machines. Sequences are read and transferred directly to databases. At present (2016) gel electrophoresis has been replaced with much faster methods.
In the pyrosequencing method, DNA is added to a solution with all enzymes for replication. In addition, there are other enzymes that release light when pyrophosphate is present (pyrophosphate is the set of two phosphate groups given off when a nucleotide is added to growing DNA; it is represented as two yellow circles in Figure 15-7B). Then a single nucleotide is added; if it is the correct nucleotide, DNA polymerase incorporates it and releases pyrophosphate, which causes a flash of light. The sequencing machine records the nucleotide that caused the flash and then introduces another nucleotide to continue the process. When the wrong nucleotide is introduced, there is no flash, and the sequencer notes that, then washes it away and introduces another. The process is repeated thousands of times as the template DNA is replicated. The latest technology is HiSeq X 10, produced by the company Illumina, which became available in 2015. It reportedly can sequence an entire human genome in just 3 days for as little as $1,000.
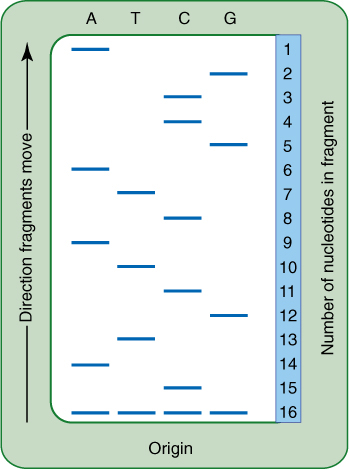
FIGURE 15-22 Diagram of a gel for a DNA fragment. Each lane marked A, T, C, or G corresponds to one of the test tubes in Figure 15-21. You can read the nucleotide sequence, starting at the top with the shortest, fastest nucleotide. A real gel would be much longer and have hundreds of bands.
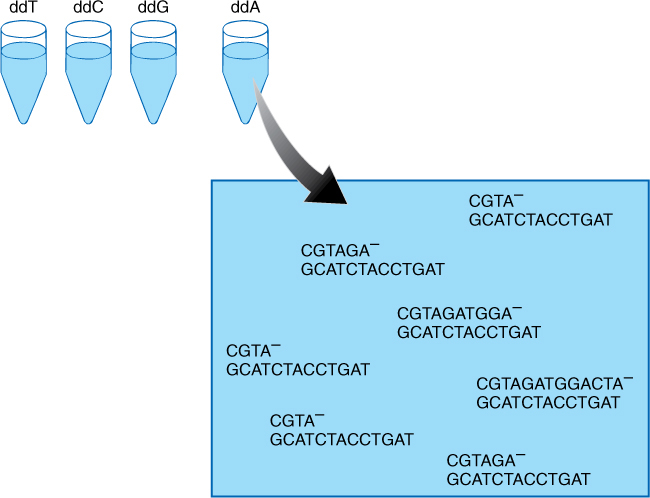
FIGURE 15-21 Chain termination method of sequencing. Into four test tubes, identical pieces of DNA have been placed; all received everything necessary, but each received a small amount of chain terminator. The one depicted here received dideoxyadenosine. If too much of the chain terminator is added, almost all stop at the first T; if too little is added, almost no chains stop at any T, and most finish the entire template. The correct amount produces a good number of copies of every possible length. After incubation, the contents of each test tube would be placed into a lane of a gel electrophoresis machine and separated by length, as shown in Figure 15-22.
Computer programs analyze the sequences, searching for regions that might be promoters or enhancers, TATA boxes, AUG start sites, and areas that might be boundaries between exons and introns. If a region is found that appears to have these gene-like features, it is referred to as an open-reading frame (ORF). To determine whether it actually is a gene, databases are searched to see if the ORF matches the sequence of any known genes. If there is no matching sequence, it continues to be called an ORF. Often there will be some sequence similarity with a known gene in the same or another organism; if the similarity is high (90% or more bases are the same), this ORF is probably a gene with the same function as the known gene, but if the similarity is lower, we are less certain—This may be a real gene, a mutated gene, an ancient duplicated gene that is evolving into junk DNA or simply a random sequence that resembles a gene.
Sequencing Entire Genomes
The sequencing described above is only effective for fragments less than several hundred bases long. To sequence a plastid or mitochondrial genome, organelles are extracted from a cell. Their circles of DNA are isolated and then cloned and divided into several batches. The DNA is cut into fragments, each batch being cut with a different restriction endonuclease, and then each fragment in each batch is sequenced. In the first batch, we might have several hundred fragments, all perfectly sequenced, but we do not know the order of the fragments. The same is true of the second batch, but each fragment here will have some portion that matches one or several portions of fragments in the first batch. By aligning the equivalent regions in the two batches, we should be able to align all fragments in proper order. Sequences from the third batch act as a verification (FIGURE 15-23). To sequence the immense genome inside nuclei, each chromosome is isolated from the others and sequenced individually by the same method.
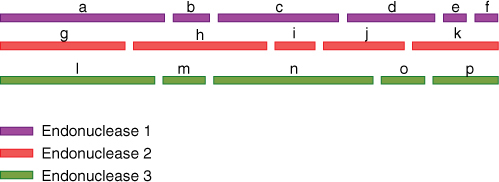
FIGURE 15-23 Very long pieces of DNA are sequenced by cloning the DNA, dividing it into several identical batches and then cleaving each batch with a separate restriction endonuclease. Each fragment is then sequenced. If we had only used endonuclease 1, we would have gotten fragments a-f, but we would not know their proper order. By comparison with the fragments from a second endonuclease, we would see that the left end of fragments a, g, and l are the same. Fragment h matches the right end of a, all of b, and the left end of c, and fragment j matches parts of c and d and so on.
![]() Genetic Engineering of Plants
Genetic Engineering of Plants
Recombinant DNA techniques have made it possible for botanists to identify, isolate, and study the structure and activity of many genes. They also allow botanists to insert genes into plants that do not normally contain those genes. For example, cotton plants have received a gene from the bacterium Bacillus thuringiensis, which codes for a protein toxic to caterpillars but not to other insects or mammals (including humans). If the gene protects the plant, it could prevent as much as $100 million in crop losses annually. Botanists have transferred genes from desert petunias into normal petunias, resulting in plants that require 40% less water. If such drought-resistance genes can be transferred to crop plants, the amount of water needed for irrigation will be greatly reduced. Tomatoes have been engineered such that the enzymes that cause them to become mushy are inhibited without inhibiting the other enzymes involved in developing flavor and aroma. The tomatoes can be allowed to ripen fully on the vine but are still firm enough to ship to market.
These GMOs (genetically modified organisms) are not welcomed by all people. In many cases, it is argued that they are not being used to prevent starvation but rather to allow agribusiness to make more profit. The argument continues that rather than genetically altering tomatoes so that they can be harvested and shipped while green and hard, isn’t it better to buy locally grown tomatoes, perhaps even ones that have been grown organically and harvested at the peak of their flavor? For example, Golden Rice has been genetically engineered to produce more beta-carotene, a precursor to vitamin A. Many people in Southeast Asia have a diet heavily dependent on rice, and with normal rice many suffer from vitamin A deficiency. Golden Rice could provide them with more vitamin A, which is good, but the counter argument is that this is still a peasant diet, a poverty diet, and there is an alternative solution: provide people with more fresh vegetables, make them less dependent on rice. Rather than focus only on vitamin A, improve more aspects of the people’s nutrition.
Obtaining some genes is not very difficult, but at present, inserting them into nuclear DNA properly so that they can be transcribed and translated is not easy. A gene may code for an improved, more nutritious storage protein and should be expressed in cotyledons during seed formation, but if the gene inserts into a region of nuclear DNA that codes for root, stem, or wood characteristics, the engineered gene either may not be activated or may become active in the wrong place. Research on the nature of promoter sites and their interaction with chemical messengers is especially intensive. Many genes have been located that are expressed only in particular tissues such as cotyledons, wood, chlorenchyma, or epidermis. Their promoters are valuable because a cotyledon promoter can be attached to our foreign gene before insertion, increasing the likelihood the gene will respond to the appropriate chemical messenger, regardless of where it inserts into the DNA (FIGURE 15-24).
FIGURE 15-24 The gene for a luminescent protein from fireflies was inserted into a plant cell in tissue culture; then the cell was induced to grow into a full plant. Apparently, this gene had a promoter that is normally activated in every cell because all cells are glowing. By attaching different promoters to this gene before the genetic engineering, it is possible to study when and where the promoter is normally active. Biologists hope to find promoters that, when attached to this gene, cause only specific cells or tissues to luminesce; then those promoters can be used whenever we want to specifically affect those types of cell or tissue.
After a gene and promoter have been prepared, they are attached to an insertion vector, usually the ti plasmid from the bacterium Agrobacterium tumefasciens (FIGURE 15-25). The plasmid has been modified by botanists by adding genes for antibiotic resistance. The completed plasmid-promoter-gene is mixed with plant cells in tissue culture; they are allowed to grow and then are treated with an antibiotic (often, hygromycin). Those cells that did not take up the plasmid, and those that took it up but are not expressing it, are killed by the herbicide. Those cells that have taken up the plasmid and are transcribing the gene and translating the mRNA into protein are resistant to the herbicide and survive. They can be cultured further. The surviving cells are induced to form new plants, which in many cases not only carry the gene and express it but pass it on to their progeny when they undergo sexual reproduction.
![]() Viruses
Viruses
In the past, much of the emphasis in studying viruses in plants was on preventing the spread of virus diseases in crops. Now many viruses are especially interesting as possible vectors for plant genetic engineering. Also, because most are RNA viruses (described below), they contain many unusual enzymes that are useful for the experimental manipulation of nucleic acids.
Virus Structure
Viruses are extremely small particles that usually contain only protein and nucleic acid. They were originally discovered in 1892 as factors that cause disease but were so small they could not be seen with a microscope and could pass easily through filters with pores fine enough to trap even bacteria. They were never actually seen until the development of the electron microscope (FIGURE 15-26). They were originally thought to be very small cells, but now we know that is not true: They have no protoplasm, no organelles, and no membranes. They cannot carry out their own metabolism independently—they must always parasitize cells of some sort. The great majority of viruses, especially those that attack plants, consist of only one or a few types of proteins and a small amount of nucleic acid (FIGURE 15-27).
Plant viruses always have a simple morphology, either long or short rods or even round particles. Tobacco mosaic viruses are rods 15 × 300 nm, whereas citrus tristeza viruses are rods up to 2,000 nm long. Spherical or polyhedral virus are common, often having a diameter of about 60 nm.
The diversity of nucleic acids in plant viruses is great. Of the known viruses, the greatest number (400) are retroviruses, which contain single-stranded RNA. Retroviruses are our source of reverse transcriptases, needed to make cDNA. Many viruses that cause cancer in humans are animal retroviruses. Twelve known plant viruses have double-stranded DNA, and there are two groups of unusual types: 10 contain double-stranded RNA, and 15 contain single-stranded DNA. Furthermore, many plant viruses are split genome viruses—not all of their nucleic acid is packaged as one particle. Instead, the virus consists of at least two different particles, and both must be transmitted to a new host cell for viral metabolism to occur. Alfalfa mosaic virus consists of four distinct particles.
Most plant viruses have enough nucleic acid to code for only a very small number of proteins. Tobacco mosaic virus contains only 6,400 nucleotides; its one and only coat protein contains 158 amino acids; thus, a minimum of 158 × 3 = 474 nucleotides are needed just for that. Three other genes exist in this virus; two large ones code for replicase enzymes, and a smaller one codes for a protein thought to mediate spread of the virus from cell to cell. Most other plant viruses are similarly small.
Virus Metabolism
Viruses must always invade a living cell in order to reproduce, and all known types of organisms are attacked by viruses: plants, animals, fungi, protozoans, algae, and prokaryotes. Viruses that attack bacteria are called bacteriophages or phages, but these are viruses just like the others. Viruses that attack bacteria and animals are usually extremely specific: A particular type of virus can attack only a certain species of host. The same is true of many plant viruses, but others are able to attack many related plant species. Fungal and algal viruses are less well known.
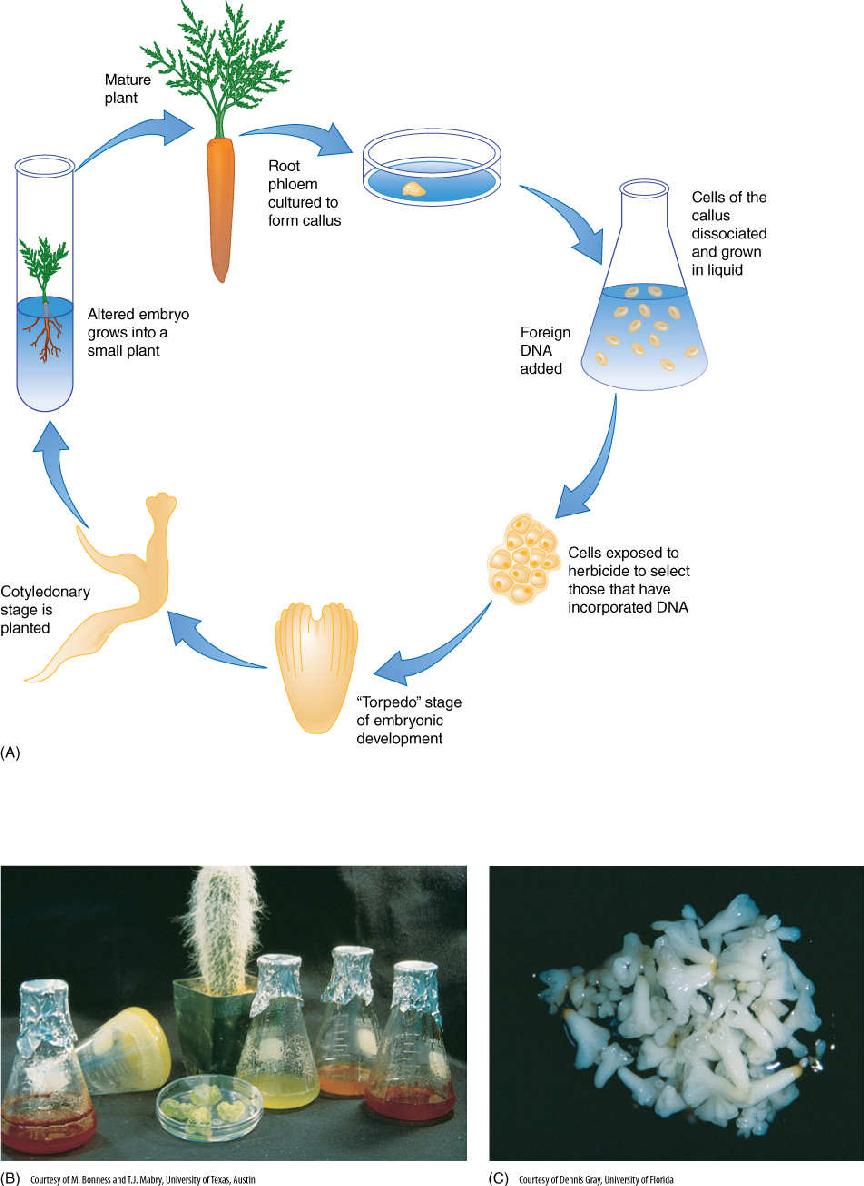
FIGURE 15-25 (A) This diagram illustrates the method involved in using recombinant DNA techniques to genetically alter a plant. The method is explained in the text. (B) Several components of a tissue culture experiment: the original plant (the cactus Cephalocereus senilis), callus culture on agar in foreground, liquid cultures in flasks. The red liquid cultures have been experimentally induced to form pigments. The flask tipped on its side shows that these cells can grow so extensively that they consume all the liquid medium and form a solid mass of cells. (C) Tissue culture experiments can also produce embryos. If they have been genetically engineered, they grow into altered plants.
To invade a plant, viruses rely on damage to living cells, such as through the action of aphids, chewing insects, or open wounds left by pruning or breaking. If an insect has chewed or sucked on an infected plant, the virus particles adhere to its mouth parts and feet. If these penetrate a host cell, some virus particles are transferred, allowing a virus particle to enter the protoplasm directly, completely bypassing the cell wall. During experimental studies of virus activity, healthy plants are infected by first abrading the epidermis with sandpaper to create fine breaks in the cells and then rubbing into the wound a solution of virus particles extracted from an infected plant; alternatively, freshly crushed, infected leaves are rubbed into the abrasion.
After the virus is inside a suitable host cell, protein molecules of the coat fall away from each other, releasing virus nucleic acid. If the virus is a DNA virus, its liberated DNA is recognized by the plant’s own RNA polymerases, and transcription of viral genes into mRNA begins. These mRNAs are translated by the plant’s ribosomes, and within minutes of infection, new viral protein appears in the cell. Transcription and translation of some viruses are rather slow, and the virus does little harm. In other types, viral mRNAs dominate the ribosomes, and the plant’s protein-synthesizing apparatus is completely taken over. At the same time that RNA polymerases are transcribing viral DNA, DNA-replicating enzymes bind to and copy the DNA, making new viral double helixes. As the number of viral DNA molecules increases, the rate of viral transcription and translation also increases. Finally, all plant cell metabolism is redirected to viral metabolism.
Retroviruses, which have RNA but no DNA, may act as an mRNA and be picked up by a plant ribosome and translated. Usually one of the first proteins to result is reverse transcriptase, which binds to the RNA and synthesizes a complementary molecule of DNA. Another enzyme then synthesizes the other half of the DNA duplex, and the rest of the steps are the same as for a DNA virus. Some retroviruses bring molecules of reverse transcriptase with them as part of their coat; therefore, reverse transcription is the first step.
As virus components become more abundant, viral nucleic acid moves into surrounding cells by means of plasmodesmata, and perhaps by passing through the wall as well. Viral nucleic acid that enters phloem spreads rapidly; the only tissues that are somewhat safe are root and shoot apical meristems, which do not contain phloem. Even in a heavily infected plant, the shoot apex itself may remain virus free.
The rate at which viruses take over host cell metabolism is variable; in many plants, it is slow and viruses never become abundant. Such plants show few disease symptoms, and the presence of virus is detected only by electron microscopy. This type of virus is common in many crop plants. If the virus multiplies quickly and dominates the cell, symptoms such as chlorosis, necrosis, and leaf curling may appear (FIGURES 15-28 and 15-29). Such viruses are virulent.
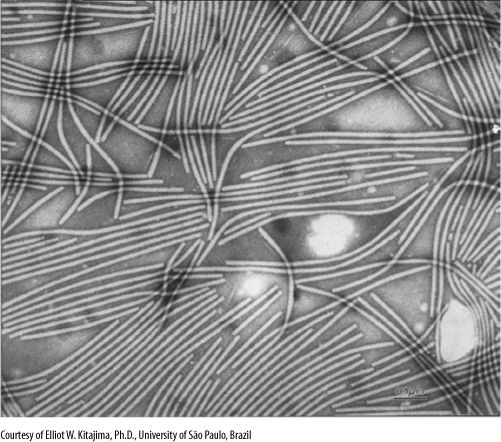
FIGURE 15-26 Turnip mosaic virus particles are long, narrow filaments. In this preparation, viruses have been isolated from plant cells, washed, and treated with heavy metals to make them visible in an electron microscope (×180,000).
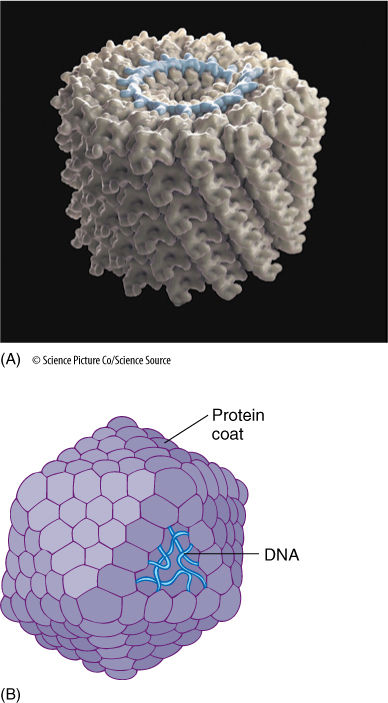
FIGURE 15-27 Most viruses, but especially plant viruses, are extremely simple. (A) Tobacco mosaic virus contains only one type of protein, which binds to the DNA, forming the long rod. In this form, the DNA is well protected. (B) In the virus shown here, the protein does not bind so closely to the nucleic acid but rather forms a coat, often called a capsid, around the nucleic acid.
Some viruses, once freed of their coat protein, insert viral DNA into the host DNA. Little is known about this process, but apparently, viral DNA lies next to host DNA, and then breaks are made in both molecules. The ends join and the cuts are healed by DNA ligase. Such viral DNA usually lies dormant, perhaps simply because so little of the eukaryotic DNA is expressed in any particular cell. However, if this insertion happens in young plant tissues, viral DNA is replicated along with plant DNA during the S phase of every cell cycle, and both daughter cells receive infected DNA during mitosis. Such viruses are termed temperate and may produce no symptoms whatsoever; they may remain hidden forever and die when the plant dies. In some, however, they become active and reproduce just like virulent viruses. The factors that induce conversion from temperate to virulent are not known. Perhaps the viral DNA inserted itself downstream from the promoter region for a gene that is now being activated as part of the cell’s differentiation. After the promoter region allows RNA polymerase to bind and transcribe, the viral DNA is transcribed as well. This hypothesis has not yet been proven, and other factors may be important.
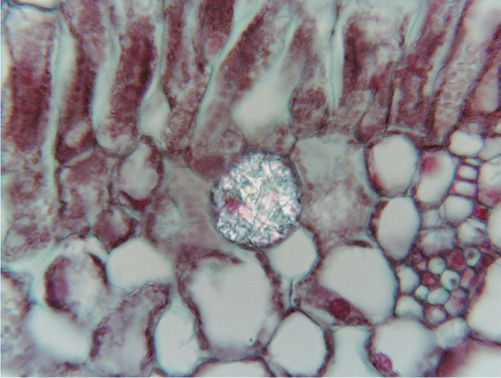
FIGURE 15-28 These cells of tobacco leaf are infected with tobacco mosaic virus. Although the cytoplasm is almost filled with virus particles, the surrounding cells appear healthy, and the vacuoles are virus free (×400).
Formation of New Virus Particles
At some point, viral components assemble into new particles (Figure 15-27). For many viruses, such as tobacco mosaic virus, this is a self-assembly process. Viral coat protein has a tertiary structure that causes it to bind to viral DNA. This binding then permits it to attract and adhere to more viral protein, and a new protein/DNA viral particle is quickly assembled. The protein monomers by themselves do not adhere to each other; viral DNA must be present. No other components are necessary, and even in a test tube, the two self-assemble into infectious virus particles.
In many types of animal viruses and bacteriophages, one of the last proteins made is an enzyme that destroys the host cell, causing it to burst (lyse) and release virus particles into the environment. This does not happen with plant viruses; perhaps the cell wall is too massive to be digested. Instead, virus particles remain in the cell until it is broken open by insects or larger animals. If an infected leaf is never eaten but instead is abscised in autumn, virus particles are released as the leaf decomposes; these too can be spread by animals.
Origin of Viruses
Many, if not most, viruses are actually portions of genes of the host species or a species closely related to the host. As living organisms are damaged or die and decay, their nuclei break down along with the rest of the cell material. It is possible that occasionally a fragment of a chromosome codes for proteins that can self-assemble into a crude coat and have some infectious potential. Such a fragment has the possibility of acting as the forerunner of a virus; the fragment does not have to be as efficient as a full-fledged virus because it can evolve just like any other genetic system. With a long span of time, natural selection favors mutations in this DNA fragment that improve its survival rate.

FIGURE 15-29 Squash mosaic virus affects not only squash, but related plants as well, such as watermelon. Symptoms occur in both leaves (A) and fruits (B).
An alternative hypothesis postulates that viruses are highly evolved, extremely efficient parasites. Whenever an organism can obtain required compounds from its environment, it is selectively advantageous not to waste energy synthesizing them, but even the most reduced, simplified parasites are vastly more complex than viruses. Could viruses be reduced parasitic bacteria instead? This seems doubtful for most viruses because the metabolism of plant and animal viruses should then resemble bacterial metabolism, but instead, it matches plant or animal metabolism.
Plant Diseases Caused by Viruses
Plants suffer from at least a thousand different virus-caused diseases. Because symptoms are similar to those of mineral deficiency or other environmentally caused problems, detection can be difficult (Figure 15-29). Few effective treatments exist for plants infected with viruses. We do not try to cure entire crops of viral disease; rather, we try to maintain healthy, uninfected breeding stock for virus-free seeds or cuttings. Heat treatment inactivates some viruses; entire plants can be kept in hot (35°C to 40°C) growth chambers or greenhouses for several weeks to several months, after which they may be free of virus. Even these techniques are ineffective in most plants and against most virus diseases; the best policy is to use virus-free plants and protect them from infection. Virus-free plants are obtained by shoot meristem propagation or sometimes by normal sexual production of seeds, if stamens and carpels can grow and set seed more rapidly than virus particles can infect them.
 At the Next Level
At the Next Level
1. Proofreading and error correction during DNA replication. As enzymes copy DNA they occasionally make mistakes by putting the wrong base in or by skipping several bases and not replicating them. Every error is a mutation. Many methods of deleting and correcting errors have evolved. Because plants grow by localized growth in shoot and root apical meristems, it is crucial for meristematic cells to detect and correct as many mutations as possible. As you investigate this, ask yourself what the consequence would be if an organism were to evolve such that it had perfect DNA replication, that either no errors were ever made, or if all errors could be detected and corrected. How would that affect the organism’s further evolution?
2. Chromosome structure. In an introductory course such as this, we explain things at a basic level: A chromosome is presented as a single DNA duplex (two complete DNA molecules wrapped around each other in a double helix) with a centromere and two telomeres. But as you might have guessed, chromosomes are much more complex: Only very small regions of the DNA consist of genes, other parts are control elements where regulators, activators, or inhibitors attach; there are regions that allow DNA to become attached to chromosome structural proteins and to the skeletal proteins of the nuclear envelope and so on. All these aspects of DNA affect the expression of genes, and all are important in plant development.
3. DNA methylation and DNA imprinting. For most traits, it does not matter which allele of a gene we inherit from our mother and which from our father. The same is true for plants. But for a small number of traits, it matters very much which allele comes from which parent. As it turns out, in both plants and animals, eggs often modify some of the genes by adding methyl groups to some of the bases whereas the sperm cells do not. Once combined into a zygote, the mother’s genes have more influence than do the father’s. The consequences and benefits of this are not yet completely understood, and now we have just discovered that in humans, fathers also mark some of their genes. It is possible that DNA imprinting will be one of the most important topics in developmental biology in the next several years.
4. Plant cloning through tissue culture and embryogenesis. It is now extremely easy to modify DNA by deleting certain elements or adding new parts. In many cases, the difficulty is then inserting the new DNA into a plant cell and forcing that cell to grow into a new plant. Often it will grow only as an irregular lump of callus in tissue culture. A great deal of research has been aimed at developing tissue culture techniques that could easily and reliably cause altered cells to grow into plants. That goal has not been achieved, but every year some progress is made. If we could trick a modified cell into acting like a zygote, the process might be universally effective.
SUMMARY
1. All information required to specify protein primary structure—the sequence of amino acids—is stored as the sequence of deoxyribonucleotides in DNA.
2. Cell differentiation is based largely on differential activation of genes and control of the processing of heterogeneous nuclear RNA into messenger RNA.
3. The exact details of the mechanism by which a plant hormone induces differential activation of either nuclear or organellar genes are not known. Binding of a hormone to its receptor results in the formation of transcription factors that bind to DNA promoter regions.
4. The genetic code consists of triplets of nucleotides, each triplet coding for only one amino acid, or for STOP or START. The code is degenerate, each amino acid being coded by several codons.
5. Genes consist of a promoter region that contains enhancer elements and a structural region that usually contains both exons and introns.
6. In transcription, RNA polymerase attaches to the promoter region, moves to a start site, and then polymerizes RNA, being guided by base pairing in a short region of single-stranded DNA. Both introns and exons are transcribed.
7. Heterogeneous nuclear RNA is processed to mRNA and then transported to the cytoplasm where it binds to ribosomes. Each ribosome has a large and a small subunit, four molecules of rRNA, and approximately 80 proteins.
8. Amino acids are carried to ribosomes as part of an activated tRNA, each of which has an anticodon complementary to the codon for the amino acid it carries. All tRNAs have similar structures.
9. Restriction endonucleases cut DNA at specific sequences; the resulting pieces can be melted to the single-stranded state. Single-stranded nucleic acids from different sources can be mixed and allowed to hybridize, either as a measure of their relatedness or as part of the construction of a new molecule of DNA.
10. Specific sequences of DNA can be synthesized artificially by incorporating one copy into a vector and then inserting the vector into a bacterium. As the bacterium reproduces, the sequence of DNA is reproduced as well.
11. Most viruses are short pieces of DNA or RNA that contain a few genes closely related to normal host genes. Most plant viruses have RNA, not DNA, and a coat of just one type of protein.
12. Viruses infect plants through wounds and then divert the plant’s nucleic acid and protein-synthesizing metabolism to the synthesis of more virus molecules, which then self-assemble into complete virus particles.
IMPORTANT TERMS
anticodon
bacteriophages
chromatin
codons
complementary DNA (cDNA)
differential activation of genes
DNA cloning
DNA denaturation
DNA hybridization
DNA ligase
DNA microarry
eukaryotic initiation factors (eIFs)
exon
expression profiling
gene
introns
messenger RNA (mRNA)
palindromes
polymerase chain reaction (PCR)
promoter region (of a gene)
recombinant DNA techniques
restriction endonucleases
restriction map
retroviruses
reverse transcriptase
ribosomal RNA (rRNA)
ribosomes
start codon
stop codon
structural region (of a gene)
transcription
transfer RNA (tRNA)
yeast artificial chromosome (YAC)
REVIEW QUESTIONS
1. Plants are composed of numerous types of cells that are all unique because they have distinct metabolisms. What are these metabolisms based on?
2. The information needed to construct each type of protein is stored in _______________.
3. Because an organism grows by duplication division, all its cells have (choose one: identical, unique) genes.
4. What is meant by the differential activation of genes? Explain how this affects the synthesis of cutin and P-protein.
5. Cutin, lignin, and chlorophyll are not proteins. How is it possible for genes to control the synthesis of these polymers?
6. A gene is made up of (choose one: RNA, protein, DNA, carbohydrate).
7. For each of these symbols, write out the full name of the base and of the nucleoside. Indicate which are components of DNA and which are components of RNA:
a. T
b. A
c. G
d. C
e. U
8. The text describes three important ways that cells protect their genes. List these methods.
9. DNA does not participate directly in the synthesis of proteins. What molecule transfers the information in DNA to the site of protein synthesis?
10. Histones are proteins in the nucleus, and DNA wraps around them forming a spherical structure. What is the name of the structure?
11. What is the name of the enzyme that digests DNA?
12. What is a codon? How many exist? Why is the genetic code described as being degenerate?
13. Examine Table 15-2. Which amino acids are coded by the following codons? (Hint: For the first base [letter] in each of the codons listed below, look at the leftmost column of the table labeled “First Base.” For the second base in each codon, look at the top row of bases, and for the third base, look at the column on the right-hand side of the page).
a. UUU
b. UCU
c. UAU
d. UGC
e. CUU
f. CGA
g. CGG
h. AAA
i. AAG
j. GAG
k. GGU
l. GGC
m. GGA
n. GGG
14. What is unusual about the answers for Questions 13k, 13l, 13m, and 13n? Because the multiple codons exist for most amino acids, the genetic code is said to be _____________.
15. Examine Table 15-2. What do the following codons specify:
a. UAA
b. UGA
c. UAG
What happens when a ribosome comes to one of these codons?
16. Examine Table 15-2. The codon AUG codes for the amino acid methionine and also for “start.” What does “start” mean?
17. What are the two portions of a gene? Which portion actually codes for the amino acid sequence?
18. Describe the promoter and structural region of a nuclear gene. What is a TATA box? What are exons and introns?
19. The structural portion of genes contains two distinct types of regions—exons and introns. Which consists of codons that are eventually translated into the amino acid sequence of a protein, and which consists of codons that are not expressed?
20. After RNA polymerase binds to DNA, it begins making mRNA. What is the name of this process?
21. What is the name of the cytoplasmic particles that translate mRNA into proteins? What type of RNA brings amino acids to this particle? This RNA has a region called an anticodon. What does the anticodon do?
22. One of the codons in mRNA that specifies the amino acid phenylalanine is UUC. What is the anticodon on the tRNA that carries phenylalanine?
23. What is a frameshift error? Does the binding of methionine tRNA to the small subunit help reduce frameshift errors? If so, how?
24. If a molecule of mRNA had the following sequence, what would be the sequence of the gene that coded the mRNA? Which amino acids would be incorporated into the protein?
gene: 3'-_____________________-5'
mRNA: 5'-UCGAACAAUUGUCCCGGCCUC-3'
protein:
25. Describe the steps of polypeptide elongation by ribosomes.
26. When a stop codon is pulled into the A channel of a ribosome, what happens? Is there any tRNA with an anticodon that is complementary to the stop codon?
27. There are three main classes of RNA involved in protein synthesis: ______________ RNA, ________________RNA, and _____________ RNA.
28. Describe DNA melting and DNA reannealing.
29. What is a restriction endonuclease?
30. What are palindromes, and how are they related to restriction endonucleases? Why are they useful for inserting one piece of DNA into another?
31. DNA fragments can be identified. For example, if plastid DNA is treated with Pst I restriction endonuclease, it cuts the DNA into about 10 to 20 fragments. If these are separated on an electrophoresis gel and then stained, this is a ___________________ ____________ of the plastid DNA.
32. Imagine that plastid DNA of species A is treated with a restriction endonuclease in order to make a restriction map. Now imagine that species B is not very closely related to species A, but species C is. If plastid DNA of species B and species C are treated with the same restriction endonuclease that was used for species A, will the restriction map of species B or species C be more similar to that of species A?
33. If mRNA is extracted from a plant and mixed with reverse transcriptase, what is the name of the DNA that is produced? If it was synthesized with radioactive nucleotides, what can be done with it?
34. Briefly describe how a piece of DNA can be cloned using bacteria. Why would it be important to use the same type of restriction endonuclease in the harvest phase as in the preparation phase? After the DNA had been cloned, how would you go about sequencing it?
35. Briefly describe how a piece of DNA can be cloned using PCR.
36. In the genetic engineering of plants, after a gene and promoter have been prepared, they must be inserted into the plant with an insertion vector. A very important vector comes from Agrobacterium tumefasciens. What is the vector’s name? After the vector and the gene-plus-promoter have been added to many plants, the plants are treated with a herbicide. Why? Which plants will survive?
37. Corn has been genetically engineered to produce the anti-insect poison of a bacterium Bacillus thuringiensis. What is one benefit of this? What are some of the risks?
38. Viruses are extremely small particles that usually contain only ____________________ and____________________ _________.
39. The diversity of nucleic acids in plant viruses is great. Which class of viruses contain single-stranded RNA? These viruses are the source of which important enzyme (Hint: This is the enzyme needed to make cDNA)?
40. There are three hypotheses about the origin of viruses. Briefly describe each hypothesis.
41. About how many plant diseases are caused by viruses?
Design Credits: Hummingbird: © Tongho58/Moment/Getty; Green plant cells: © ShutterStock, Inc./Nataliya Hora; Purple tulip: © ShutterStock, Inc./Marie C Fields; Dandelion: © ShutterStock, Inc./danielkreissl; Poppy: © ShutterStock, Inc./Saruri; Plant icon: © ShutterStock, Inc./Vector; Digging man icon: © ShutterStock, Inc./Z-art