CONCEPTS IN BIOLOGY
PART II. CORNERSTONES: CHEMISTRY, CELLS, AND METABOLISM
3. Organic Molecules—The Molecules of Life
3.4. Nucleic Acids
Nucleic acids are complex organic polymers that store and transfer genetic information within a cell. There are two types of nucleic acids: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). DNA serves as genetic material, whereas RNA plays a vital role in using genetic information to manufacture proteins. All nucleic acids are constructed of monomers known as nucleotides. Each nucleotide is composed of three parts: (1) a 5-carbon simple sugar molecule, which may be ribose or deoxyribose, (2) a phosphate group, and (3) a nitrogenous base. The nitrogenous base may be one of five types. Two of the types are the larger, double-ring molecules adenine and guanine. The smaller bases are the single-ring bases thymine, cytosine, and uracil (i.e., A, G, T, C, and U) (figure 3.15). Nucleotides (monomers) are linked together in long sequences (polymers), so that the sugar and phosphate sequence forms a “backbone” and the nitrogenous bases stick out to the side. DNA has deoxyribose sugar and the bases A, T, G, and C, whereas RNA has ribose sugar and the bases A, U, G, and C (figure 3.16).
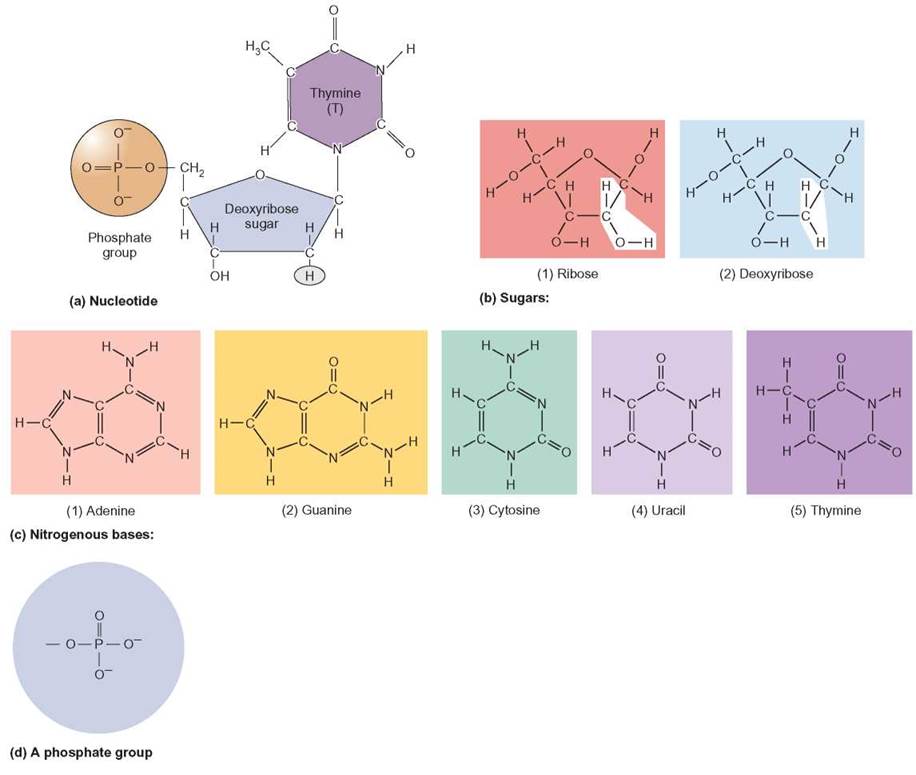
FIGURE 3.15. The Building Blocks of Nucleic Acids
(a) A complete DNA nucleotide composed of a sugar, phosphate, and a nitrogenous base. (b) The two possible sugars used in nucleic acids, ribose and deoxyribose. (c) The five possible nitrogenous bases: adenine (A), guanine (G), cytosine (C), uracil (U), and thymine (T). (d) A phosphate group.
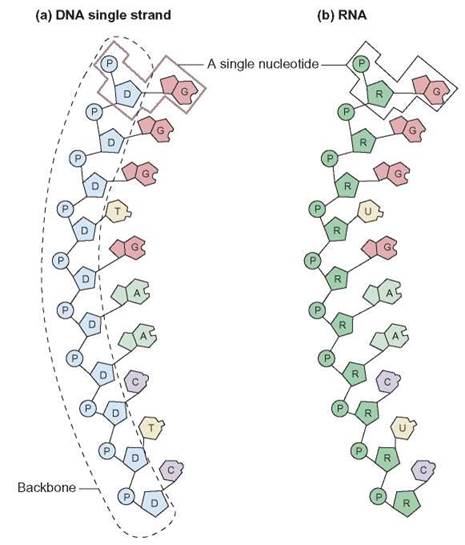
FIGURE 3.16 DNA and RNA
(a) A single strand of DNA is a polymer composed of nucleotides. Each nucleotide consists of deoxyribose sugar, phosphate, and one of four nitrogenous bases: A, T, G, or C. Notice the backbone of sugar and phosphate. (b) RNA is also a polymer, but each nucleotide is composed of ribose sugar, phosphate, and one of four nitrogenous bases: A, U, G, or C.
DNA
Deoxyribonucleic acid (DNA) is composed of two strands, which form a twisted, ladderlike structure thousands of nucleotides long (figure 3.17). The two strands are attached by hydrogen bonds between their bases according to the basepair rule. The base-pairing rule states that adenine always pairs with thymine, A with T (in the case of RNA, adenine always pairs with uracil—A with U) and guanine always pairs with cytosine—G with C.
A T (or A U) and G C
A meaningful genetic message, a gene, is written using the nitrogenous bases as letters along a section of a strand of DNA, such as the base sequence CATTAGACT. The strand that contains this message is called the coding strand, from which comes the term genetic code. To make a protein, the cell reads the coding strand and uses sets of 3 bases. In the example sequence, sets of three bases are CAT, TAG, and ACT. This system is the basis of the genetic code for all organisms. Directly opposite the coding strand is a sequence of nitrogenous bases that are called non-coding, because the sequence of letters make no “sense,” but this strand protects the coding strand from chemical and physical damage. Both strands are twisted into a helix—that is, a molecule turned around a tubular space, like a twisted ladder.
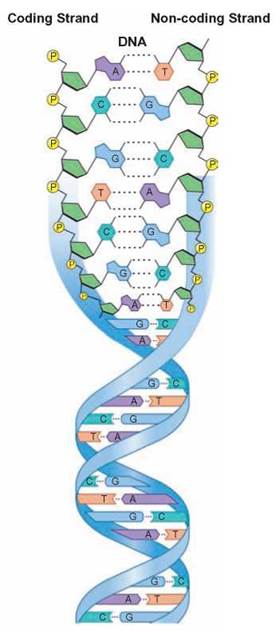
FIGURE 3.17. DNA
The genetic material is really double-stranded DNA molecules comprised of sequences of nucleotides that spell out an organism’s genetic code. The coding strand of the double molecule is the side that can be translated by the cell into meaningful information. The genetic code has the information for telling the cell what proteins to make, which in turn become the major structural and functional components of the cell. The non-coding strand is unable to code for such proteins.
The information carried by DNA can be compared to the information in a textbook. Books are composed of words (constructed from individual letters) in particular combinations, organized into chapters. In the same way, DNA is composed of tens of thousands of nucleotides (letters) in specific three letter sequences (words) organized into genes (chapters). Each chapter gene carries the information for producing a protein, just as the chapter of a book carries information relating to one idea. The order of nucleotides in a gene is directly related to the order of amino acids in the protein for which it codes. Just as chapters in a book are identified by beginning and ending statements, different genes along a DNA strand have beginning and ending signals. They tell when to start and when to stop reading the gene. Human body cells contain 46 strands (books) of helical DNA, each containing many genes (chapters). These strands are called chromosomes when they become super-coiled in preparation for cellular reproduction. Before cellular reproduction, the DNA makes copies of the coding and non-coding strands, ensuring that the offspring, or daughter cells, will receive a full complement of the genes required for their survival (figure 3.18). A gene is a segment of DNA that is able to (1) replicate by directing the manufacture of copies of itself; (2) mutate, or chemically change, and transmit these changes to future generations; (3) store information that determines the characteristics of cells and organisms; and (4) use this information to direct the synthesis of structural, carrier, and regulator proteins.
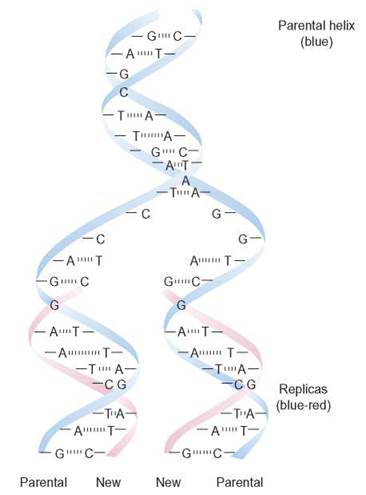
FIGURE 3.18. Passing on Information to the Next Generation
This is a generalized illustration of DNA replication. Each daughter cell receives a copy of the double helix. The helices are identical to each other and identical to the original double strands of the parent cell.
RNA
Ribonucleic acid (RNA) is found in three basic forms. Messenger RNA (mRNA) is a single-strand copy of a portion of the coding strand of DNA for a specific gene. When mRNA is formed on the surface of the DNA, the base-pair rule applies. However, because RNA does not contain thymine, it pairs U with A instead of T with A. After mRNA is formed and peeled off, it links with a cellular structure called the ribosome, where the genetic message can be translated into a protein molecule. Ribosomes contain another type of RNA, ribosomal RNA (rRNA). rRNA is also an RNA copy of DNA, but after being formed it becomes twisted and covered in protein to form a ribosome. The third form of RNA, transfer RNA (tRNA), is also a copy of different segments of DNA, but when peeled off the surface each segment takes the form of a cloverleaf. tRNA molecules are responsible for transferring or carrying specific amino acids to the ribosome, where all three forms of RNA come together and cooperate in the manufacture of protein molecules (figure 3.19).
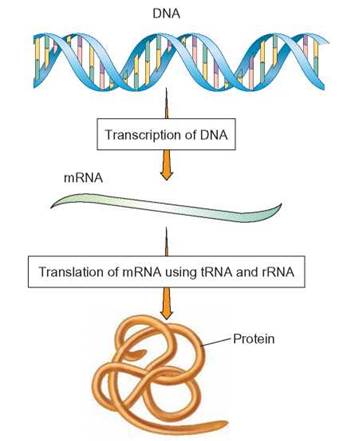
FIGURE 3.19. The Role of RNA
The entire process of protein synthesis begins with DNA. All forms of RNA (messenger, transfer, and ribosomal) are copies of different sequences of coding strand DNA and each plays a different role in protein synthesis. When the protein synthesis process is complete, the RNA can be reused to make more of the same protein coded for by the mRNA.
Whereas the specific sequence of nitrogenous bases correlates with the coding of genetic information, the energy transfer function of nucleic acids is correlated with the number of phosphates each contains. A nucleotide with 3 phosphates has more energy than a nucleotide with only 1 or 2 phosphates. All of the different nucleotides are involved in transferring energy in phosphorylation reactions. One of the most important, ATP (adenosine triphosphate) and its role in metabolism will be discussed in chapter 6.
3.4. CONCEPT REVIEW
10. Describe how DNA differs from and is similar to RNA both structurally and functionally.
11. List the nitrogenous bases that base-pair in DNA and in RNA.