Must Know High School Biology - Kellie Ploeger Cox 2019
PART THREE Genetics
Gene Expression and Differentiation
MUST ![]() KNOW
KNOW
![]() Differentiation occurs when a cell begins to select the genes it will express in order to become specialized in its function.
Differentiation occurs when a cell begins to select the genes it will express in order to become specialized in its function.
![]() Transcription is the most important step of differentiation.
Transcription is the most important step of differentiation.
![]() Correct grouping of codons in mRNA (keeping the correct reading frame) is necessary for proper translation of proteins.
Correct grouping of codons in mRNA (keeping the correct reading frame) is necessary for proper translation of proteins.
![]() The proteins that are created by a cell depend not only on the genes, but also on the control by which genes are expressed.
The proteins that are created by a cell depend not only on the genes, but also on the control by which genes are expressed.
![]() An operon makes sure that genes are expressed only when they’re needed.
An operon makes sure that genes are expressed only when they’re needed.
Let me tell you a story: a long time ago, you didn’t exist. Then, one cell fused with another, and you did exist. At least the beginning of you existed. Every organism that is the product of sexual reproduction was formed after a sperm cell fused with an egg cell, creating what is called a zygote (the cell formed after the egg and sperm merged). This single cell needed to do many rounds of DNA replication and division before it formed the glorious specimen that is YOU.
But along the way, other clever things happened. If that beginning zygote simply divided over and over and over again, you would be, what, a huge blob of cells without any specific shape. Think about what you look like now: you have skin, and bones, and muscles, and all sorts of interesting bits. In order for that to occur, the cells in your body—that all have the exact same DNA, by the way—had to start to get picky about what genes they were going to “express.” The evolution of advanced multicellular organisms occurred because cells began to differentiate. Differentiation means a cell begins to express the proteins from specific genes that were otherwise ignored, and by doing so, the cell starts to specialize in form and function.
![]()
IRL
You may often see references to stem cell research and their use in medicine. Stem cells have amazing potential because they are undifferentiated, meaning they have not begun the process of picking and choosing which genes to read (and which cell type to turn into). If a person has a failing organ or needs a skin graft, it would be ideal to collect some of their own stem cells and guide them down the differentiation pathway for whatever organ or tissue type that is needed.
This first step—the cell choosing which genes it cares about and which proteins it wants to create—is the most important step of cell differentiation (one of our must know concepts). But I am getting ahead of myself. Let’s first talk about what gene expression actually means, and how a cell goes about reading a gene and creating the protein that it codes for.
Transcription
Your DNA never leaves the nucleus. It’s too precious and important to go wandering about the cell. It’s the original blueprint for you, so it better stay locked in a safe location. Recall from Part Two, however, that the cell machinery responsible for making the proteins (ribosomes) reside in the cytoplasm, outside of the nucleus. There needs to be a temporary message that can take the instructions from the genes in the nucleus and shuttle them to the ribosomes waiting in the cytoplasm. This “go-between” instruction is the piece of messenger RNA (mRNA) that’s created in the nucleus. It is a single piece of RNA complementary to only a single gene, and the process of creating it is called transcription. The procedure is similar to DNA replication, in that the double-stranded DNA molecule has to unzip by breaking the hydrogen bonds between the two strands, and a polymerase enzyme will then match complementary nucleotides to the exposed template strand. There are, however, significant differences:
1. Only the DNA double helix around the gene being expressed is unwound.
2. Only a single gene is transcribed (not the entire chromosome). There is never a need for a cell to make the proteins of all 25,000 different genes … that’s crazy! Why would a cell in your eyeball need to make the protein for hair growth? Ew.
3. The polymerase that transcribes is called RNA polymerase, and as its name suggests, it matches up RNA nucleotides to the exposed gene template (makes sense, since it’s making a piece of mRNA).
4. Only one side of the DNA double helix for any given gene is transcribed. There are two strands for each gene, but the two strands are not identical—they are complementary. Therefore, the proper recipe for a protein is contained in only one of the two strands; this is designated the template strand.
For example, here is a segment of a gene in DNA:
GGTACCTGTGTGTAAATAAGACTCAG ← template strand
CCATGGACACACATTTATTCTGAGTC
After this double-stranded portion of the DNA unzips, RNA polymerase will create a piece of mRNA complementary to that top template strand. Also, keep in mind that RNA has uracil nucleotides instead of thymine.
Here is the resulting mRNA strand created by RNA polymerase:
CCAUGGACACACAUUUAUUCUGAGUC
It is a must know to realize this moment of selecting and transcribing only certain genes is absolutely key to cell differentiation. And since RNA polymerase targets individual genes for transcription, it needs some sort of “landing strip” to help it position properly. These landing sites are called promoters, and it’s simply a segment of DNA with a certain sequence of nucleotides. One promoter is situated before every gene. In eukaryotic cells, in order for the large, ungainly RNA polymerase to land on the promoter, it also needs the help of a collection of proteins called transcription factors. RNA polymerase can’t position itself properly without the help of these special proteins. Once RNA polymerase reaches the end of the gene it is transcribing, it lets go of both the DNA and the piece of mRNA it just created.
You just learned about the how of transcription, but it’s just as important to consider how much. A cell can regulate the amount of a given protein is produced by controlling how many times RNA polymerase scoots down a gene and creates a piece of mRNA. If a cell wants a LOT of a certain protein, it needs to make a LOT of the appropriate mRNA. To do so, there are these special transcription factors (called activators) that bind way upstream from the gene’s promoter at special sequences in the DNA called an enhancer region. Even though the activators bind far away, they somehow help RNA polymerase to land at the promoter. This seems weird, right? How can something hanging out on the DNA way before a gene have any influence on RNA polymerase landing at the promoter? Surprisingly, the DNA molecule has to bend in order for these activators to work:
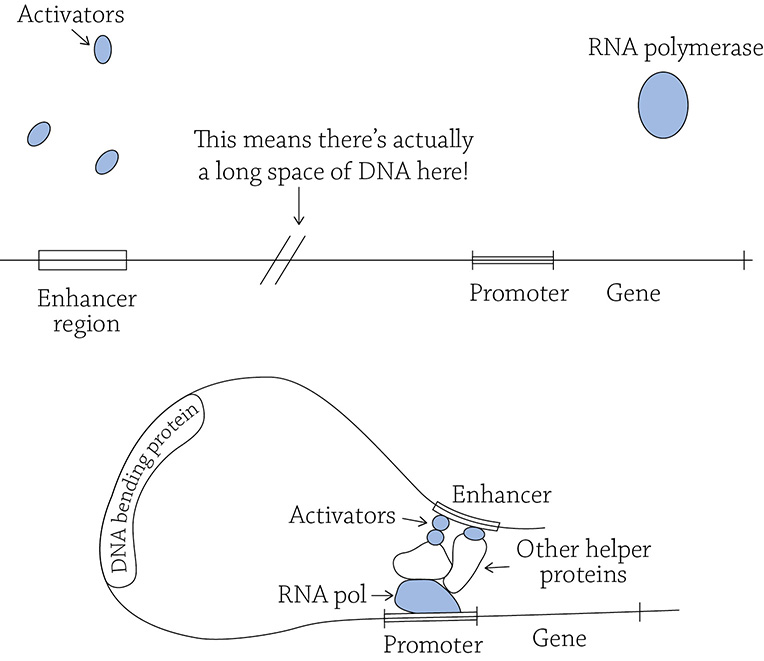
Specific transcription factors (activators) helping RNA polymerase to land
With the help of a DNA bending protein, the strand of DNA loops around to bring the activators close to the promoter. They, along with other helper proteins, help align RNA polymerase on its promoter, facilitating transcription. Recall that our must know concept states that the cell choosing which genes to transcribe is the key step to a cell differentiating into a specific cell type. We will talk about transcription factors in more detail when we learn about the specifics of cell differentiation later on.
Translation
The cell now has a brand-new piece of mRNA, fresh off the RNA polymerase assembly line. The instructions of the mRNA now will be “read” by the ribosomes, who will then assemble the proteins coded for by the mRNA (and originally coded for by the gene). Do you remember where the ribosomes are hanging out? Yes, they’re waiting in the cytoplasm, either floating around freely or stuck onto the rough endoplasmic reticulum. The freshly transcribed piece of mRNA needs to now move from the nucleus into the cytoplasm (easy, because the nuclear membrane has a bunch of pores in it for this very purpose).
Once the mRNA gets to the cytoplasm, it’s time for the ribosomes to get to work. A ribosome will grab onto the beginning (5′ end) of the mRNA molecule (we learned about the 3′ and 5′ ends of nucleic acids in Chapter 3). Each mRNA molecule carries the message for the final protein product, originally coded for by a particular gene safely stored away in the nucleus. Keep in mind that a protein is a polymer of individual amino acids. In order to decipher the correct sequence of amino acids, the ribosome needs to look at every three “letters” in the mRNA (each letter is a single nucleotide and its particular nitrogenous base). A grouping of three bases in mRNA is referred to as a codon. Each codon tells the ribosome what amino acid is next in the growing protein. It is a must know that the correct grouping of codons in mRNA—and keeping the correct reading frame—is necessary for proper translation of proteins. Unfortunately, there’s an easy way for the ribosome to mess up. Here is an example of a catastrophic mistake:
![]()
What if, instead, the ribosome thought it should start grouping into sets of three starting at the first “H”?
![]()
Oh, that’s not good. The groupings of three are now totally different! Just as it doesn’t make sense when we read it, it doesn’t make sense when making a protein. The ribosome would piece together seven amino acids, but they would be the wrong amino acids. Furthermore, notice that the original protein should have eight amino acids. Because of the unfortunate shift, there’s a last grouping of two letters, which is not enough to code for an amino acid (a codon contains three bases). When a ribosome is translating a protein, this type of mistake is called a frameshift mutation. It occurs because the ribosome didn’t line up properly when it grabbed the mRNA. In order to make sure it aligns correctly, it needs a start point in order to set the correct reading frame. Luckily, there is such a start point! It is a special codon called the start codon, and it’s always adenine-uracil-guanine (AUG) and codes for the amino acid methionine. This is where the ribosome situates itself when it lands at the beginning of the mRNA. By doing so, it sets the correct reading frame because it creates the proper grouping of three bases. Consider our example mRNA sequence from earlier:
mRNA:
CCAUGGACACACAUUUAUUCUGAGUC
If you look carefully, can you figure out where the ribosome would land and establish its reading frame?
CC [AUG] [GAC] [ACA] [CAU] [UUA] [UUC] [UGA] [GUC]
The ribosome essentially ignores any nucleotides before the AUG start codon. Now each of those codons code for a single amino acid in the final protein. The ribosome relies on another type of RNA to bring over the correct amino acid for a given codon. These are called transfer RNA (tRNA) and they are molecules of RNA with two important “ends”—one end that attaches to a specific amino acid (of which there are 20 options), and the other end that wants to hydrogen bond with the specific codon it is destined to recognize. The part of the tRNA that hydrogen-bonds with a codon in mRNA is called the tRNA’s anticodon.
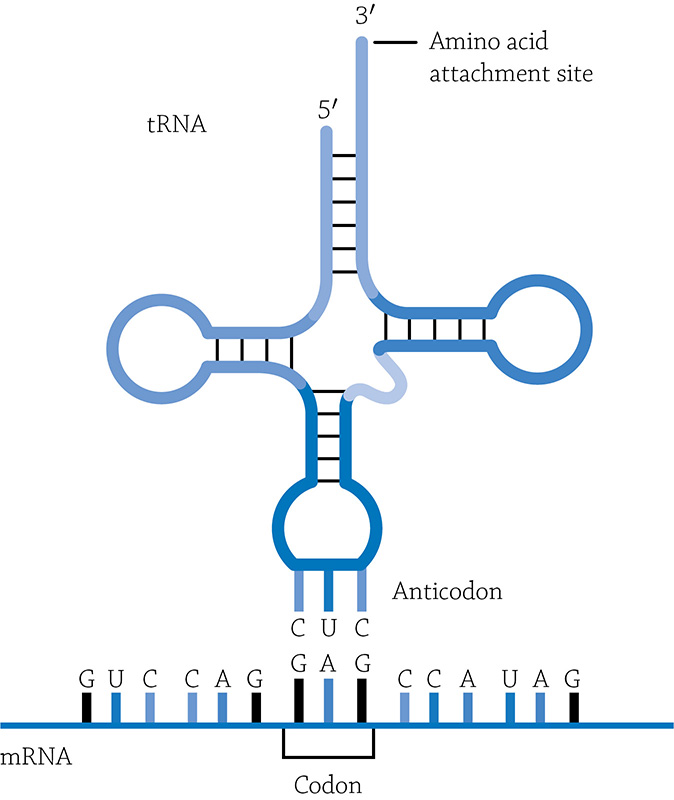
A tRNA molecule hydrogen-bonding with its correct codon
Author: Yikrazuul. https://commons.wikimedia.org/wiki/File:TRNA-Phe_yeast_en.svg
After the correct tRNA binds and brings in the starting methionine amino acid, the ribosome shifts down the mRNA to the next codon. A different tRNA will arrive, carrying with it the correct amino acid. A special covalent bond called a peptide bond will form between the two adjacent amino acids, and the first tRNA releases its amino acid. It can then leave the ribosome, float off into the cytoplasm, and find another methionine amino acid to grab. Meanwhile, the ribosome shifts down another codon, and the process begins anew.
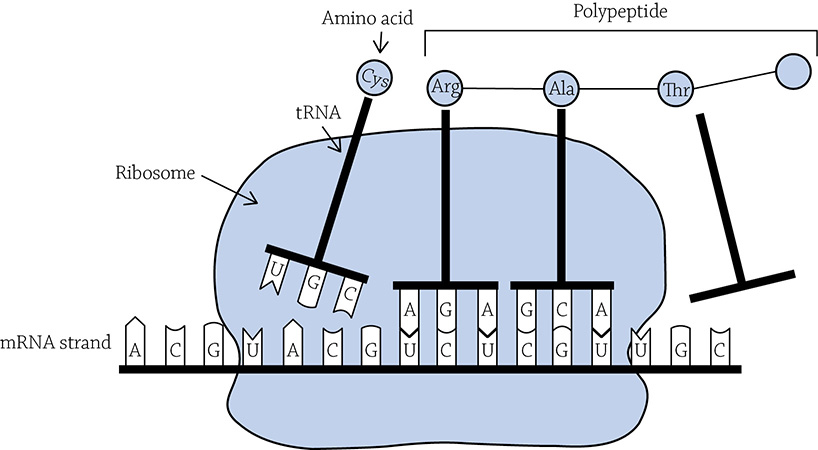
A ribosome coordinating translation of a mRNA into a protein
Author: Sarah Greenwood. https://commons.wikimedia.org/wiki/File:Protein_Synthesis-Translation.png
Similar to the ribosome knowing where to start making a protein by landing on the start codon, the ribosome knows when it’s done once it hits the stop codon. Unlike the start codon (which actually coded for the specific amino acid methionine), the stop codon doesn’t add an amino acid to the protein. Instead, a special protein called the release factor comes over and sets free the ribosome, the mRNA, and the protein. Process complete!
![]()
Once a “naked” tRNA leaves the ribosome (it’s naked because it lost its amino acid), and scoots off to grab another one, it doesn’t just grab any of the 20 possible amino acids. Remember the actual structure of a tRNA molecule: it’s a piece of RNA with a specific sequence of bases for its anticodon. The anticodon of a tRNA never changes, so a tRNA molecule will always recognize the same codon and bring in the same amino acid.
You are able to crack the genetic code of a gene. All you need is a codon table and to remember the must know step of setting the correct reading frame. How do you do that, you ask? First, circle the start codon (AUG), and mark every codon (three bases) thereafter. Then you use a codon table to translate. For example, for this mRNA sequence, determine the sequence of amino acids of the protein:
CUAUGAACGUCGAGGUAUUUUAACCGAGUA
![]()
CUAUGAACGUCGAGGUAUUUUAACCGAGUA
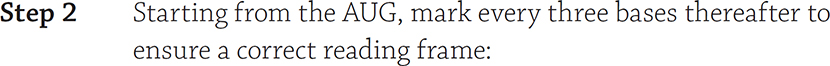
CU AUG AAC GUC GAG GUA UUU UAA CCG AGU A
Ignore the “CU” at the very beginning, because you only start translating at the AUG start. Now use the codon table to crack the code:
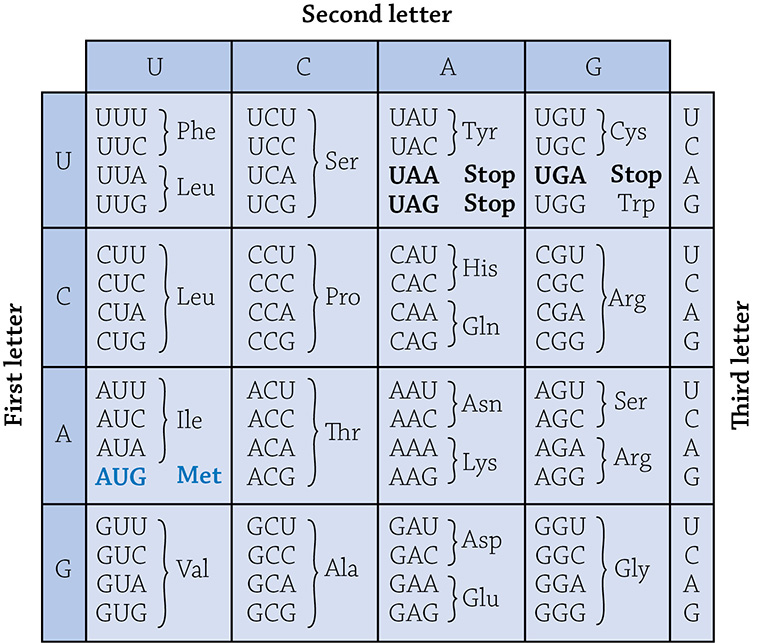
Codon table
Okay, so when you use a codon table, simply consider the three bases in a single codon. Find the first letter along the left-side column, and notice that every codon along that row starts with the same letter. Next, find the correct second letter by choosing the correct column (look at the top of the table). Finally, chose your specific codon (decided by the final third letter).
AUG = methionine (MET … three-letter abbreviations are fine)
AAC = asparagine (ASN)
GUC = valine (VAL)
GAG = glutamic acid (GLU)
GUA = valine (VAL)
UUU = phenylalanine (PHE)
UAA = STOP!
Therefore, your final protein has a total of six amino acids, each held together by a total of five peptide bonds:
MET-ASN-VAL-GLU-VAL-PHE
Even though there are more bases at the end of your mRNA strand, if they occur after the STOP codon, just ignore them.
![]()
IRL
Notice in our above protein that the amino acid valine was coded for by two different codons: GUC and GUA. There are a total of 20 different amino acids but a total of 64 different three-letter combinations of A, C, U, and G. That means that for all of the amino acids (besides methionine) there are at least two different codon options. Furthermore, for the most part, the change occurs in the third base. The third base is referred to as the “wobble position” because it can often be swapped out for another base and give you the same amino acid.
Cell Differentiation and Epigenetics
Let’s go back to the fact that you used to be a single, undifferentiated blob of cells. They were, in fact, stem cells, because they had the potential to turn into any cell type. Eventually, the cells in your body changed into different tissues and formed different organs. The cells that compose these different body parts are very different, both in what they look like (form) and what they do (function). The cool thing is, they all originated from that early blob of stem cells, and they all have the same genes. But because of those special transcription factors called activators, each cell could begin to pick and choose which genes to focus on. For example, a pancreatic beta cell needs to produce a lot of insulin, so it has the activators specifically to increase transcription of the insulin gene. The beta cell, however, does not have the specific activators to “turn on” the gene for stomach acid production because, well, why would it want to do that? The pancreas cell has the gene for hydrochloric acid, but it never bothers to transcribe it. The gene isn’t gone, it’s just quiet. Some cells go one step further than just not bothering to transcribe a gene; a cell can take steps to turn OFF huge swaths of a chromosome by blocking RNA polymerase. So, essentially, there are two ways to tweak which genes are expressed: large scale regulation and small-scale regulation.
Large-Scale Regulation
Recall that it is necessary to wrap DNA around histone proteins in order to pack all that DNA into a tiny nucleus. This mixture of DNA and histone proteins is called chromatin. Large-scale regulation of DNA expression has to do with modifying chromatin structure in large segments of a chromosome. Modification of the chromatin structure is necessary because RNA polymerase can’t transcribe the genes on a segment of DNA that is wrapped around histones; the genes are essentially turned off. Luckily the DNA can unspool and unwrap whenever RNA polymerase needs access to certain genes.
There are clever ways for a cell to control whether a segment of a chromosome is being used or kept quiet. For example, if the cell adds these little chemicals called methyl groups to certain bases in the DNA, the genes in that region will not be transcribed (and the genes in that area will remain “off”)!
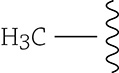
A methyl group attached to the DNA
If, on the other hand, these other chemicals called acetyl groups are added to the histone proteins, then the DNA is forced to unwind a bit and transcription can occur.
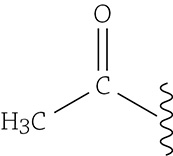
An acetyl group attached to the DNA
This is an interesting concept: a cell can control what genes are being expressed without actually changing the genetic sequence. It’s not changing the message, it’s just deciding whether the message is read. This ability to control the genome without changing the actual nucleotide sequence is called epigenetics. The word epigenetic literally means “in addition to changes in genetic sequence.” Interestingly enough, these epigenetic changes to chemical changes to your DNA or histones are heritable!
![]()
IRL
Epigenetic changes are a natural way for your cells to control gene expression. Epigenetic changes, however, have also been linked to a number of diseases, including some cancers.
Small-Scale Regulation
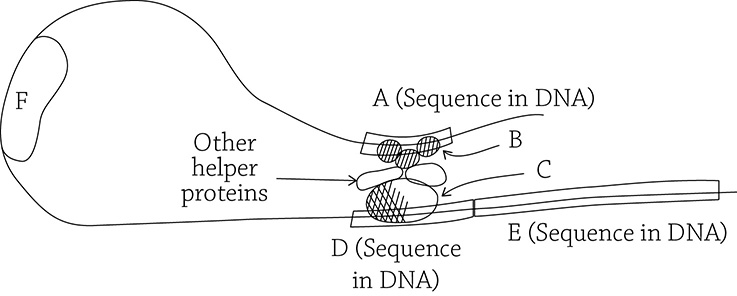
Even when there is a huge stretch of DNA exposed and ready to be expressed, the cell still picks particular genes to be transcribed. This is the small-scale (finely tuned) level of gene regulation, and it is all under the control of the specific transcription factors called activators we learned about earlier. In general, any transcription factor helps RNA polymerase to position itself correctly on the promoter. Some of these transcription factors aren’t picky about what genes they help RNA polymerase target; they are, therefore, called general transcription factors (A). Before RNA polymerase can begin the process of transcribing the gene into mRNA, these general transcription factors first land at a sequence within the promoter called a TATA box (B). These little proteins help RNA polymerase to align itself properly on the promoter (C).
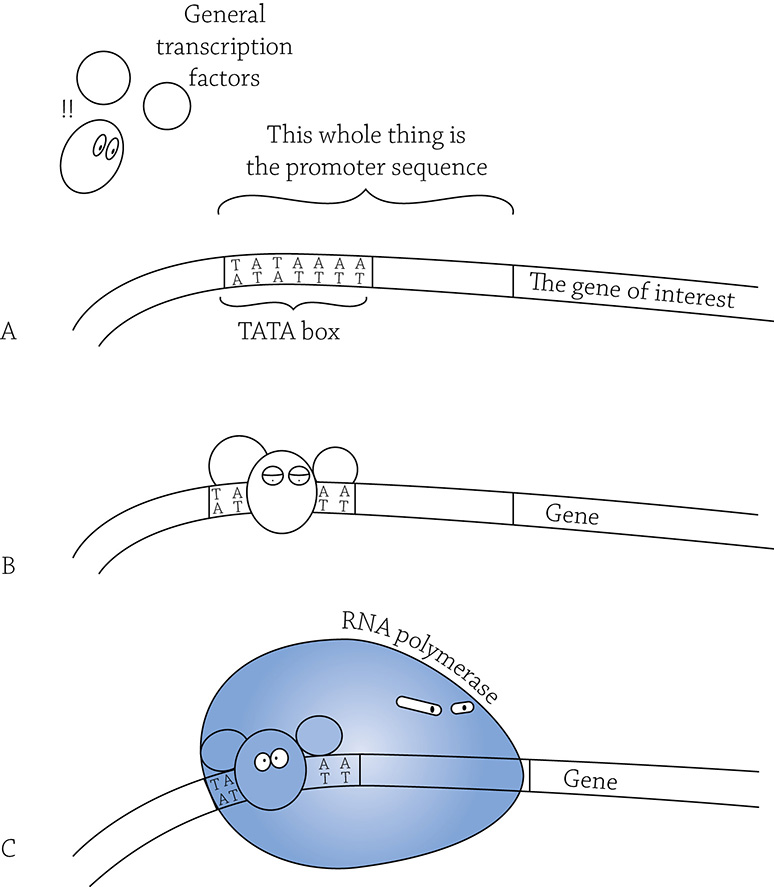
General transcription factors helping RNA polymerase to align itself on the promoter
If general transcription factors are involved in the low-level transcription of all genes, then specific transcription factors are involved in the substantial transcription of particular genes. This is a key step in the process of cell differentiation! In order for a cell to differentiate, it must begin to pick and choose which genes are important to its specific function. For example, a pancreatic cell needs to “switch on” the insulin gene, whereas a liver cell must switch on the gene for albumin. How does a particular cell know which genes it must express? This is possible with the help of the activators.
![]()
Unlike general transcription factors, activators bind somewhere other than the promoter. Seems weird, right? How can activators help RNA polymerase bind at the promoter if they themselves bind somewhere else? Strangely enough, when activators bind, they bind way upstream (meaning before) of the gene and its promoter. When they do, they cause the entire piece of DNA to bend, and the activators grab onto RNA polymerase and help it land appropriately. We talked about this earlier in the chapter, in case you want to review how this actually happens.
So, each cell has a selection of activators, which are needed to unlock the specific genes that the cell wants to express. These activators bind to a region called the enhancer region. The enhancer region is made from a mix-and-match of little DNA sequences called distal control elements. Are you confused yet? I’m so sorry. Let me try and give you an analogy.
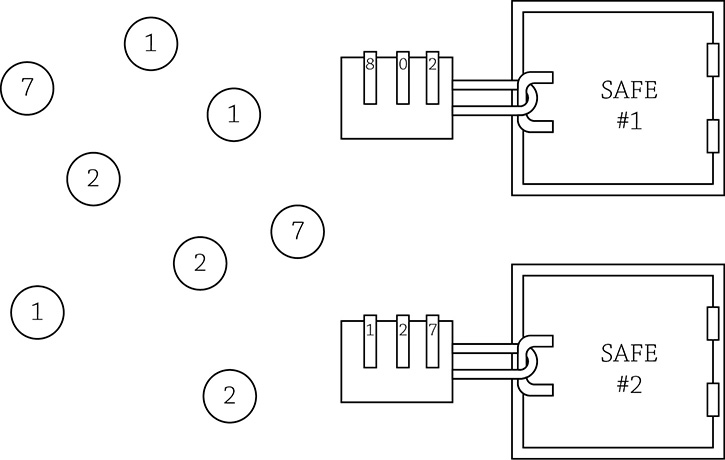
Activators and distal control elements analogy
Let’s pretend there are two safes, each containing a different set of blueprints for something cool. You are only allowed to build the really cool thing stored within the safe for which you have the correct keys. In the above example, which safe are you allowed to open? Yup, safe #2, because you have available to you the “number keys” one, two, and seven. Specific transcription factors work in the same way: the entire lock is the enhancer region, the specific numbers in the lock are the distal control elements, and the floaty number keys are the activators (a cell’s specific selection of transcription factors).
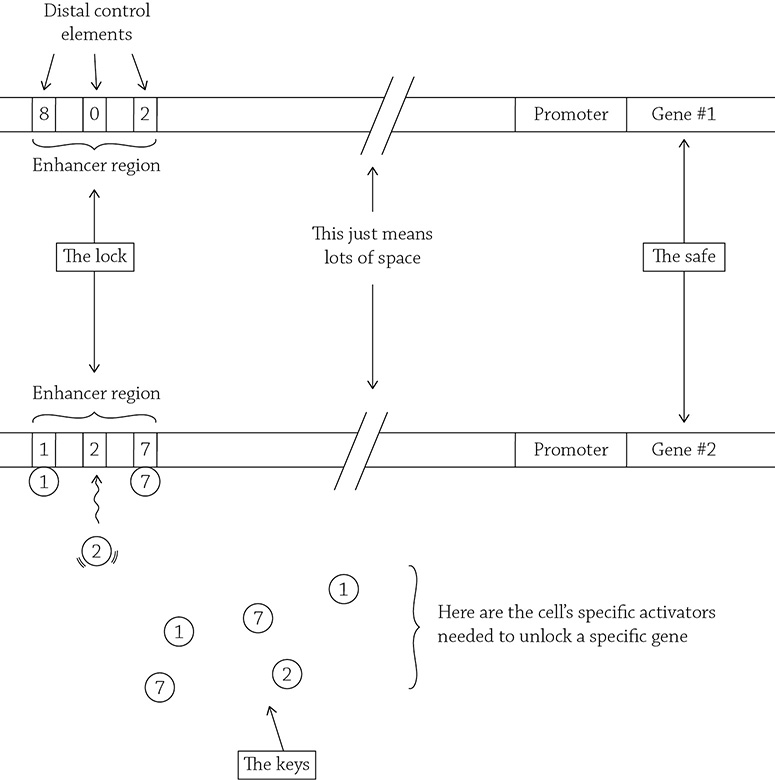
Activators and distal control elements
Please recall our must know concept, that the proteins created by a cell depend not only on what genes are present, but whether a certain gene is allowed to be expressed. A cell knows if it is supposed to express a gene if it has the correct activators that bind the combination of distal control elements in the enhancer region associated with that specific gene. A pancreatic cell will have the correct activators that match the enhancer region associated with the insulin gene; a liver cell will NOT have the correct combination of enhancers associated with the insulin gene (why would a liver cell want to produce insulin??) Instead, the liver cell will have a different combination of activators that will instead bind to the enhancer region linked to the albumin gene, a protein that liver does indeed want to make!
Operons: Regulation of Gene Expression in Prokaryotes
Prokaryotic cells (or more informally, our friends the bacteria) do not have nuclei nor organelles. But all cells must have DNA, and bacteria do indeed have DNA: a single, circular piece that is composed of approximately 1,500 genes (give or take, depending on the species). Even though the number of genes is relatively small compared to us huge, complex, and (arguably) advanced eukaryotes, bacteria still must finesse their way around their genome and only express those genes that are needed and necessary at any given moment. Prokaryotes have evolved a very clever system to control the expression of multiple genes simultaneously: the operon.
![]()
Keep in mind that the term “expression” here means RNA polymerase is landing at a gene’s particular promoter and creating a complementary bit of mRNA that will then be translated by a ribosome into the final protein product. When a gene is expressed, the protein encoded for by that gene is going to be produced by the cell.
Oftentimes, it behooves a cell to express a handful of genes, or not bother with expressing any of these genes. This usually applies to biochemical pathways that have multiple steps that all work together toward a common goal:
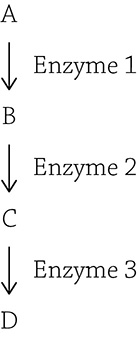
Biochemical pathway to create the compound D from the starting compound A
The figure above shows a multistep biochemical pathway, and each of the three steps are catalyzed by a specific enzyme. This example could model the synthesis of a compound (D) from a starting compound (A), or it could model the digestion of a compound (A) that needs to be broken down in three stages before the cell gets the final product needed (D). The point here is that both of these examples require multiple enzymes to get the job done, and stopping halfway through wouldn’t necessarily do the cell any good. That is why operons are so helpful: it puts the expression of multiple genes under the control of a single promoter. In our example, the genes of the operon are coding for the enzymes (enzymes 1, 2, and 3) needed to complete the biochemical pathway. In order for the suite of genes to be expressed in appropriate conditions, the operon needs other components in order to control whether RNA polymerase will land at the promoter or not. An operon has a total of four components, each needed for this expression finessing.

The figure below shows the general structure of a bacterial operon. In this diagram, the regulatory gene has been transcribed and translated, producing a repressor protein (which may or may not bind to the operator within the promoter). RNA polymerase is poised to transcribe the structural genes. If the repressor is unable to bind the operator, RNA polymerase can do its job; if the repressor protein binds the operator, RNA polymerase will be blocked (and the structural genes will not be expressed as proteins).
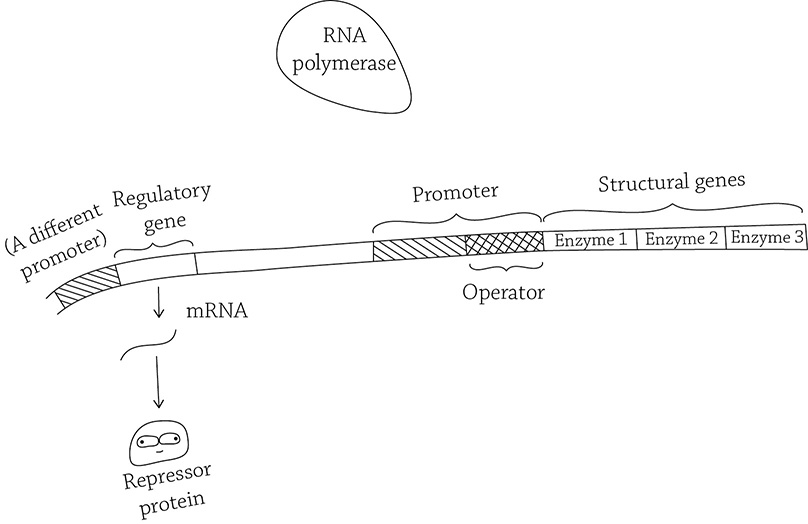
The general structure of a bacterial operon
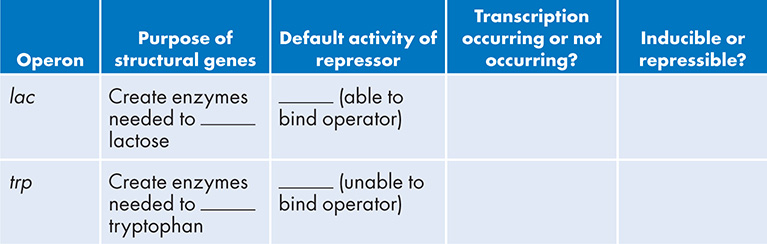
We will talk about two different operons, both found in E. coli bacteria: the lactose (lac) operon, and the tryptophan (trp) operon. I’ll start with the lac operon.
lac Operon
I mentioned earlier that the structural genes of an operon can create enzymes to either digest or synthesize a particular compound. The lac operon creates enzymes necessary for the digestion of the sugar lactose.
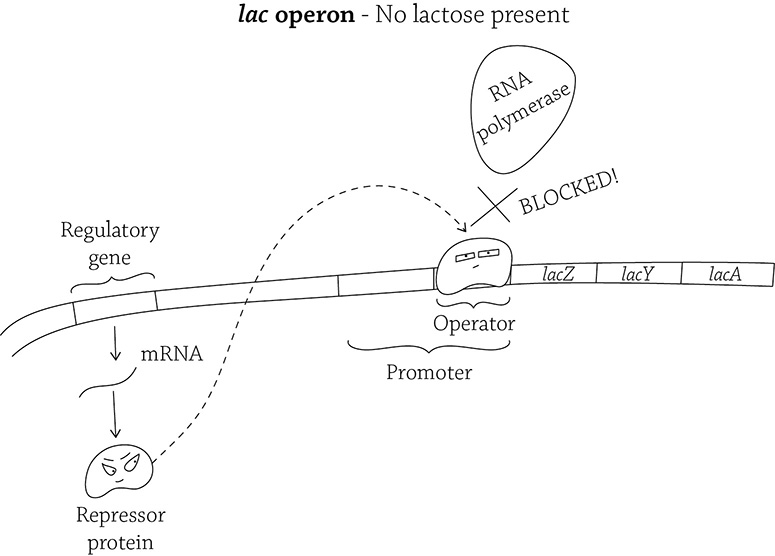
The lac operon (in the absence of lactose)
This figure depicts the “default” setting of the lac operon: the regulatory gene produces a repressor protein that immediately binds to the operator, effectively blocking RNA polymerase from transcribing (expressing) the structural genes.
The structural proteins of the lac operon are normally not being transcribed. Because their expression will only occur if the operon is somehow activated, the lac operon is said to be inducible. What would be a logical signal from the environment that E. coli should allow the operon to begin creating the enzymes to digest lactose? … Lactose! If lactose is present, it will bind to the repressor and inactivate it! The inactive repressor is unable to bind to the operator, and therefore RNA polymerase is able to bind the promoter and transcribe the structural genes.
![]()
Okay, based on the lac operon’s default setting, you can make a logical guess about whether or not the sugar lactose is normally available in E. coli’s environment. You should deduce that lactose is normally NOT a food source for E. coli, because that regulatory gene produces an active repressor that immediately blocks RNA polymerase from expressing the genes. And what do those genes code for? Enzymes that DIGEST LACTOSE. So, it makes sense that if there is no lactose, don’t bother creating the genes to break it down.
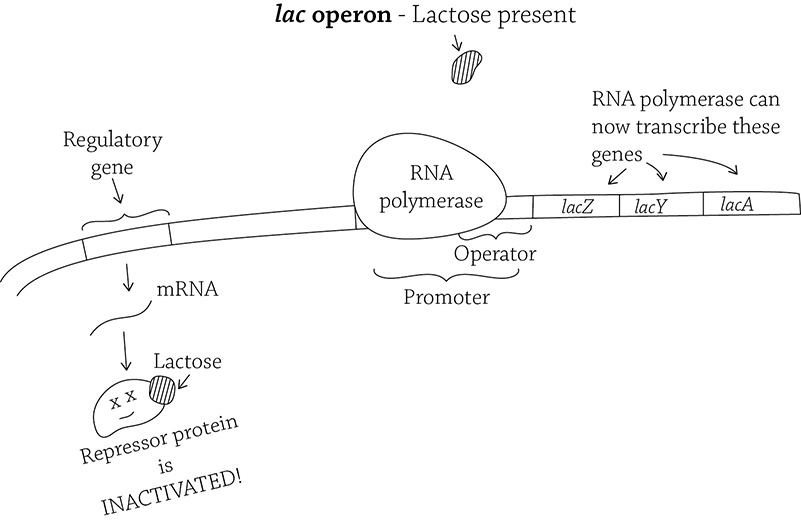
The lac operon (in the presence of lactose)
What do you think would happen if all the lactose is then digested? The repressor would no longer be inactivated, so it would once again stop the transcription of the enzymes needed to digest lactose (which is no longer available!).
trp Operon
Here is our second operon example, the trp operon. “Trp” is the abbreviation for tryptophan, an essential amino acid that E. coli needs to live. The structural genes in the trp operon code for five different enzymes. These enzymes work together in the multi-step synthesis of the amino acid, tryptophan. As we said before, it’s an all-or-nothing situation: in order to create tryptophan, the cell must go through five steps, and each step requires a specific enzyme; those enzymes are created by the genes trpA through trpE.
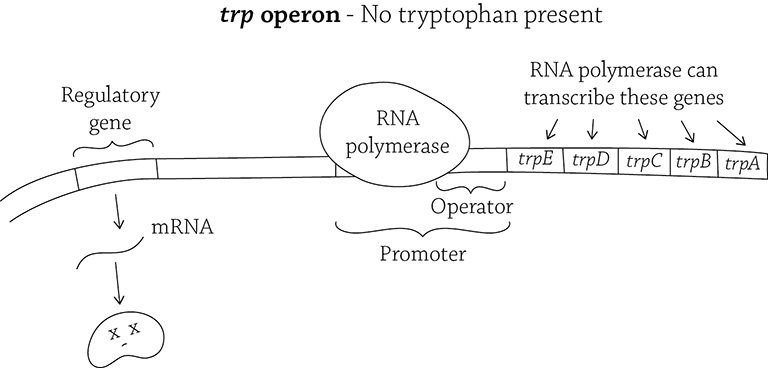
The trp operon (in the absence of tryptophan)
Unlike the lac operon, the trp operon’s regulatory gene produces a repressor that is inactive. The inactive repressor is not able to bind to the operator and block RNA polymerase. Therefore, the cell is usually producing the genes needed to synthesize tryptophan. This means the trp operon is repressible (because it’s normally expressing the structural genes and must be told to stop doing so). Now, when would the cell NOT want to create these genes? Yes, exactly! When tryptophan is freely present in the environment! Why could E. coli waste the time and energy to make the amino acid if it’s already there?
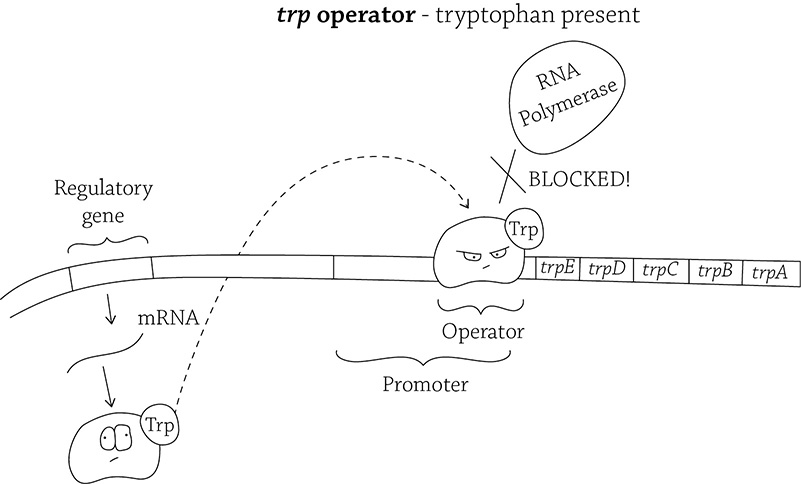
The trp operon (in the presence of tryptophan)
Cleverly, tryptophan acts as a corepressor for the operon. If tryptophan is available, it will bind to the inactive repressor and activate it! The repressor then binds to the operator, blocking RNA polymerase and the transcription of the tryptophan-synthesizing genes. Brilliant!
![]()
A thought experiment: Is the amino acid tryptophan usually present in E. coli’s environment? Without knowing anything about E. coli’s living conditions, you can answer this question by thinking about the trp operon. The default setting is to allow the transcription of the genes needed to create tryptophan; therefore, the amino acid tryptophan is normally NOT available since it needs to constantly make it itself!
As I tell my students, understanding the concept of how an operon works can be tricky. To make it even more challenging, there are these two specific examples that are both exactly the same (the components of an operon and how it functions), but also totally different:
Comparing lac and trp Operons
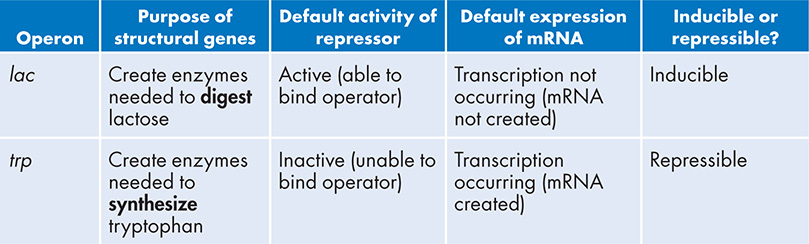
I love the logic behind how these regulatory sequences work. And once you get it, it really clicks in your brain. The must know concept stated that operons provide a way to express a collection of genes only if they are needed. The lac operon only creates the enzymes to digest lactose if lactose is present; the trp operon only creates the enzymes to synthesize tryptophan if there is no tryptophan available. An efficient and clever means to control gene expression.
REVIEW QUESTIONS
1. Fill in the blanks: The process of ___________________ is when an undifferentiated _______________ cell begins to selectively express certain genes and turns into a specific tissue type.
2. Why is a promoter important to transcription?
3. General transcription factors are small proteins that bind to the _______________ and help _______________ to land properly. If the cell needs to create a lot of mRNA, however, it needs the help of specific transcription factors called _______________. Unlike the general transcription factors, these specific transcription factors bind upstream of the promoter at sequences in the DNA called _______________ regions.
4. Choose the correct term from each pair of words: By adding methyl groups to DNA/histones gene transcription will be increased/decreased. If, instead, acetyl groups are added to DNA/histones gene transcription will be increased/decreased.
5. General transcription factors bind at the _______________ within the promoter, whereas specific transcription factors (activators) bind at a specific combination of _______________ in the _______________ region.
6. Is the trp operon an inducible or repressible operon? What does this mean regarding the availability of tryptophan in E. coli’s environment?
7. For each of the following, indicate whether the statement is true or false:
a. During transcription, the entire chromosome is unwound and unzipped.
b. The process of transcription involves the enzyme RNA polymerase moving down the entire chromosome and creating a piece of mRNA.
c. For a given gene, only one side of the DNA double helix contains the correct code for protein synthesis.
8. What is the role of general transcription factors in gene expression?
9. Label the following picture:
10. Transcribe and translate the following gene (top strand is the template strand):
GCTACTGATCGACCCCCATAATGAAAATCTTTT
CGATGACTAGCTGGGGGTATTACTTTTAGAAAA
11. Select the right term from the pair: The lac operon is a(n) inducible/repressible operon because it is normally not transcribing the genes for lactose digestion.
12. Fill in the following table about the lac and trp operons: