Must Know High School Biology - Kellie Ploeger Cox 2019
PART ONE Chemistry for Biology
Macromolecules
MUST ![]() KNOW
KNOW
![]() Large macromolecules are created with dehydration reactions and broken apart by hydrolysis reactions.
Large macromolecules are created with dehydration reactions and broken apart by hydrolysis reactions.
![]() Glucose is the monomer used to create many large carbohydrate polymers.
Glucose is the monomer used to create many large carbohydrate polymers.
![]() Phospholipids are key to the formation of cell membranes (and all life).
Phospholipids are key to the formation of cell membranes (and all life).
![]() A protein’s structure is based on its sequence of amino acids.
A protein’s structure is based on its sequence of amino acids.
![]() The four different bases of DNA and RNA provide the variability for the genetic code.
The four different bases of DNA and RNA provide the variability for the genetic code.
Earth is populated by organic life-forms, meaning we are all composed of a bunch of carbon-based molecules (organic chemistry focuses on the study of carbon compounds). Even though the term life-form could mean a ton of wildly different things (a speck of lichen, a piece of kelp, a colony of E. coli), they all have the same basic building block: the cell. We will talk about the structural brick of life in detail when we get to Part Two (Cells), but for now, let’s take a closer look at some of the key categories of molecule that make up a cell: carbohydrates, lipids, proteins, and nucleic acids. It is a must know to recognize that each macromolecule performs a very specific function for the cell.
A molecule is defined as a group of atoms held together by covalent bonds. Water (H2O), glucose (C6H12O6), and caffeine (C8H10N4O2) are all molecules. Now, if I use the term macromolecule, hopefully it makes you think of something that’s big; many of biology’s important molecules are big macromolecules. Furthermore, if this gigantic macromolecule is created by covalently linking together smaller, repeating molecules, it’s referred to as a polymer (the repeating subunit of which is a monomer). If this all makes your head spin, I understand. I think it’s easier if I show you specific examples. First, however, let’s talk about the chemical reactions needed to create these big ol’ macromolecules. As the other must know states, the creation (and destruction) of these macromolecules all use the same reactions: dehydration and hydrolysis.
Dehydration and Hydrolysis Reactions
The process of creating macromolecules from smaller components relies on a type of reaction called a dehydration reaction. If you are dehydrated, it means you are low on water, and if you dehydrate foods, it means you remove water from them. It makes sense that a dehydration reaction involves the removal of water, specifically, the removal of a water molecule between the two monomers that are being connected. Hanging off of one monomer there is a hydrogen (-H), and on the other monomer there is a hydroxyl group (-OH). A specific enzyme catalyzes the removal of the water molecule and leaves in its place a brand-new covalent bond:
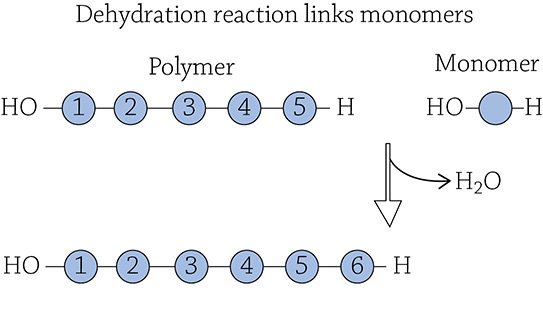
If you were to reverse the process, individual monomers would be cleaved from the larger polymer. Since a water molecule was removed to form the link, the cell needs to add a water molecule back to sever the link. Using water (hydro-) to break (-lysis) a covalent bond is called a hydrolysis reaction:
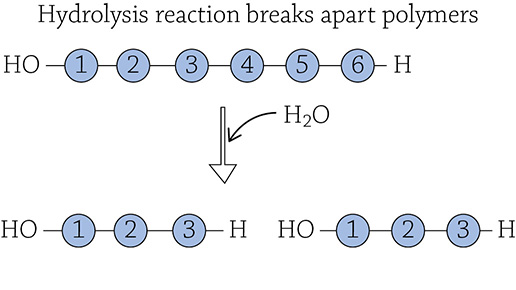
The reactions that occur in your digestive tract are mostly hydrolysis reactions, breaking up polymers in your food into individual monomers for your body to use!
Carbohydrates
The term carbohydrate may bring to mind pasta and bread and other starchy deliciousness. Indeed, you are correct—these foods are categorized as carbohydrates. In this case, you are using the term in the dietary sense. From a chemical point of view, a carbohydrate is a molecule containing carbon, hydrogen, and oxygen, usually in a 1:2:1 ratio. The most important carbohydrate we will be talking about is glucose (C6H12O6). It only contains carbon, hydrogen, and oxygen, and it adheres to the ratio of twice as many hydrogens as either carbons or oxygen. Please note that this → C6H12O6 is the molecular formula for glucose, and what you see below is the structural formula for glucose. Structural formulas show bonds and the spatial arrangement of atoms.
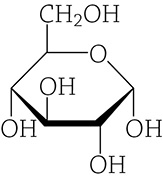
Structural formula of glucose
Glucose is extremely important because it is the fuel for all cells. When we learn about making energy for the cell, you will see that glucose is “burned” to create a molecule called ATP; this process is called cellular respiration, and we’ll talk about it more in Chapter 6. For now, this is the overall equation for cellular respiration:
C6H12O6 + 6O2 → 6CO2 + 6H2O + ATP
The molecule ATP is the true energy currency of all cells. It’s like a battery that powers all life-forms. Unfortunately, ATP isn’t very stable and a cell can’t stock up on ATP and expect it to stay “charged.” But guess what is super stable and can be easily stored? Glucose! The best way for a cell to store energy is to stockpile glucose, and then when it needs the useable form of energy (ATP), it sends the glucose through cellular respiration. Here’s another thing to consider—how does a cell efficiently store all that glucose? The answer is by covalently linking a bunch of glucose molecules together into a larger structure that can be tucked away for later use. The covalent link formed between glucose monomers is called a glycosidic link. Just like the must know concept suggested, the resulting large macromolecule was created by a dehydration reaction between adjacent simple sugar molecules.
If you are a plant, you store a huge amount of glucose as the polymer starch; if you are an animal, you store it as the polymer glycogen. To summarize, a cell stores the monomer glucose by covalently bonding thousands of them together using a dehydration reaction. The glucose-storage polymer for plants is starch, and for animals it is glycogen. Even though both of these carbohydrate polymers (also called polysaccharides) are made up of the same monomer (glucose), they have different structures when you look at the overall shape. Plants store their starch in organelles called amyloplasts; animals store their glycogen in their liver and muscle cells.
![]()
The root word “glyco-” means sugar! Also, the term saccharine refers to something sweet.
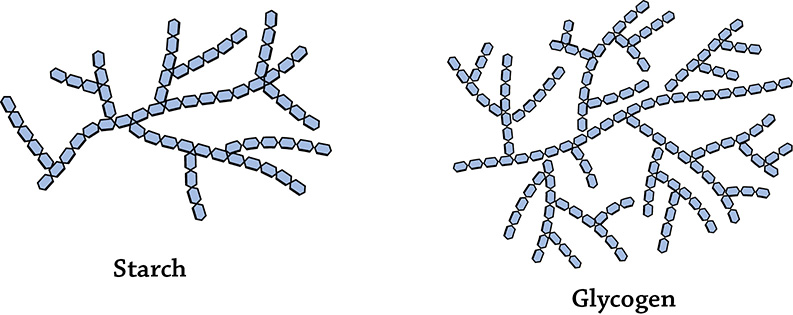
Overall structures of starch and glycogen. Each individual hexagon is a single glucose monomer.
We eat plants and pillage their storage of starch. Referring back to our must know concept, recall that a hydrolysis reaction is going to break up a polymer into individual monomers. Animals have an enzyme called amylase to hydrolyze the glycosidic bonds between the glucose monomers of both starch and glycogen. One thing to note that we’ll talk about later: the specific type of glycosidic bond found in starch is called an alpha-glycosidic link. Once the starch polymer is broken down and glucose is freed by our digestive system, the glucose jumps into our circulatory system and is transported throughout the body to be used in cellular respiration to make ATP. But what if after eating (and digesting) a huge starchy meal, we end up with extra glucose? Do we then re-form the polymer starch and store it in our own bodies? Nope. Animals eat starch, but we don’t store starch. Instead we have the enzymes for dehydration reactions to covalently link the glucose monomers into glycogen, our own energy storage polymer! The glycogen can then be hydrolyzed to release its glucose whenever we need a boost of energy. Whether we are referring to plants’ starch or animals’ glycogen, they both perform the same must know function for the cell of energy storage polymer.
Interestingly enough, there is another polymer of glucose called cellulose. Unlike starch and glycogen, its function is NOT to store glucose to use for energy. The must know function of cellulose is instead for structure and support, and it is found in plant cell walls. Cellulose, unlike starch and glycogen, forms straight chain structures that stack one on top of another and hydrogen-bond together to form a nice, strong layer:
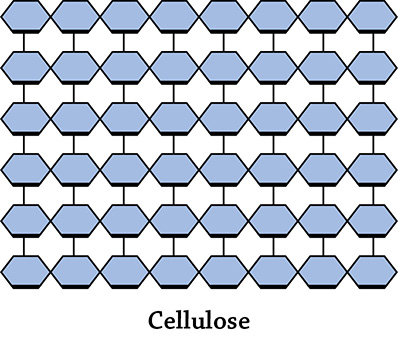
Cellulose. Once again, each small hexagon is a glucose monomer.
Just like starch, the glucose monomers in cellulose are linked together by dehydration reactions. However, the resulting bond is a beta-glycosidic link (unlike starch’s alpha-glycosidic link). This is significant! The only reason we can’t use cellulose as a source of glucose in our diet is because we lack the specific hydrolytic enzymes to break the beta-glycosidic link. Our amylase enzymes (produced in our salivary glands and by our pancreas) target starch’s alpha links, but can’t do a thing with those silly beta links. That means we can’t digest the cellulose in the plants we eat. That’s doesn’t mean it’s bad … on the contrary, dietary cellulose (also called fiber) is important for your health. A high-fiber diet helps regulate your blood glucose levels, makes you feel full, and keeps you “regular” because the fiber travels intact (and quickly) through your digestive system!
There’s another carbohydrate polymer that, like cellulose, is important for structure. It is called chitin (pronounced KI’-tin) and it is the structural polymer for the exoskeletons of arthropods (insects and crustaceans) and the cell walls of fungi (mushrooms and mold). It is a little weird because it is the only carbohydrate to contain something other than carbon, hydrogen, and oxygen … can you see what element is also found in chitin?
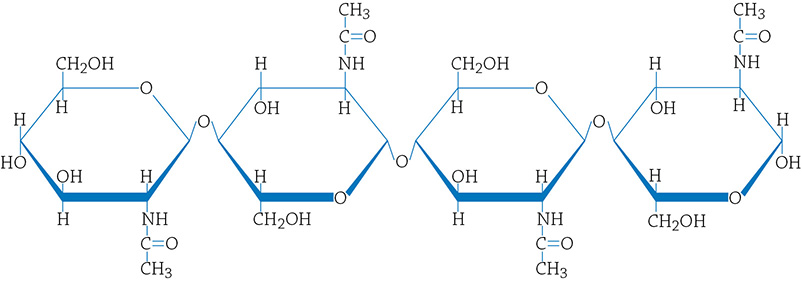
Structural formula for chitin. Notice that there is nitrogen in this carbohydrate (which is not found in any of the others).
Lipids
The next class of macromolecules we’ll talk about is the lipids. These are indeed big molecules, but don’t expect to see the repeating-monomer-structure of the other large carbohydrates: lipids are not polymers. They are, however, big molecules with significant structural components. They are also created using dehydration reactions. The three types of lipids that we’ll cover are steroids, fats, and phospholipids. Generally speaking, all lipids are hydrophobic, meaning they hate water. You may already know that if you’ve ever poured some olive oil into water—the blob of oil just sits there and doesn’t mix well. This is because molecules that contain mostly carbon and hydrogen are nonpolar; nonpolar molecules are hydrophobic.
Steroids
The general structure of a steroid is a four-ringed molecule, like this:
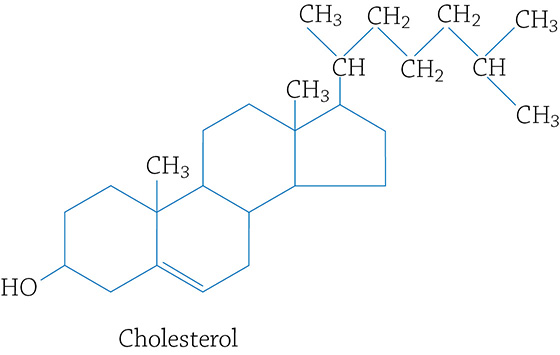
Cholesterol (a type of steroid)
Though cholesterol gets a bad rap because many folks have high levels in their blood (which isn’t healthy) and we should avoid foods with high cholesterol, it is also a must know concept that cholesterol plays a very important role in the formation of cell membranes.
Fats
In your daily life, if you mention “fats” you are most likely referring to food. Fat is, indeed, the stuff in your diet like butter, cooking oil, lard, and the like. A fat molecule is composed of two components: one glycerol molecule with three fatty acids attached to it:
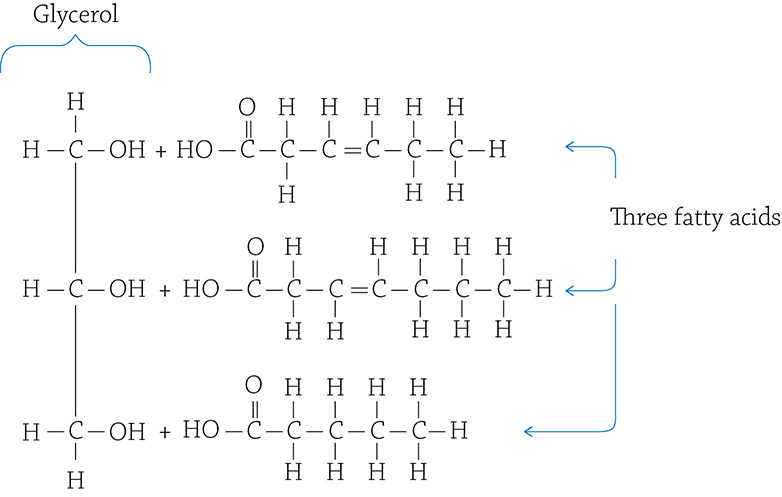
One glycerol and three fatty acids
Each fatty acid molecule is attached to the glycerol through—you guessed it—a dehydration reaction! The resulting bond is called an ester linkage, and the final fat molecule looks like this:
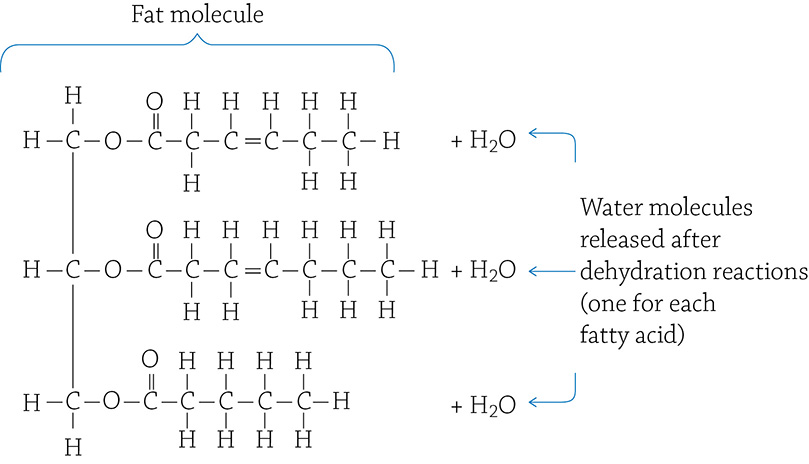
An unsaturated fat molecule
There are different kinds of fats, depending on the types of fatty acids attached to the glycerol. More than 20 kinds of fatty acids are found in foods, but it is not important for you to know them. You do, however, need to pay attention to whether or not a fatty acid has a double bond between two carbons. If there is a double bond, that is an “unsaturated” fatty acid. If there are only single bonds between carbons, it is a “saturated” fatty acid.
![]()
For my students, it helps if I explain why, exactly, a fatty acid is described using the terms saturated and unsaturated. It has to do with the fact that carbons like to form four covalent bonds. If a carbon in the fatty acid chain has two hydrogens stuck on to it, that’s as many as it could possibly hold (the last carbon in the chain doesn’t count). Therefore, it is “saturated” with hydrogens. If, instead, there’s a carbon-carbon double bond, each of those carbons can only afford to have one hydrogen attached (because each carbon can only have four total covalent bonds). That is why it is referred to as “unsaturated” … it isn’t saturated with the maximum number of hydrogens!
The reason this is important is because the double bonds in an unsaturated fatty acid make a kink in the carbon chain. A weird-shaped fatty acid means that the fat molecules cannot pack tightly together. There are three main states of matter, right? Solid, liquid, and gas. If molecules of a fat can’t pack super-close, it is going to be a liquid at room temperature, such as olive oil and canola oil.
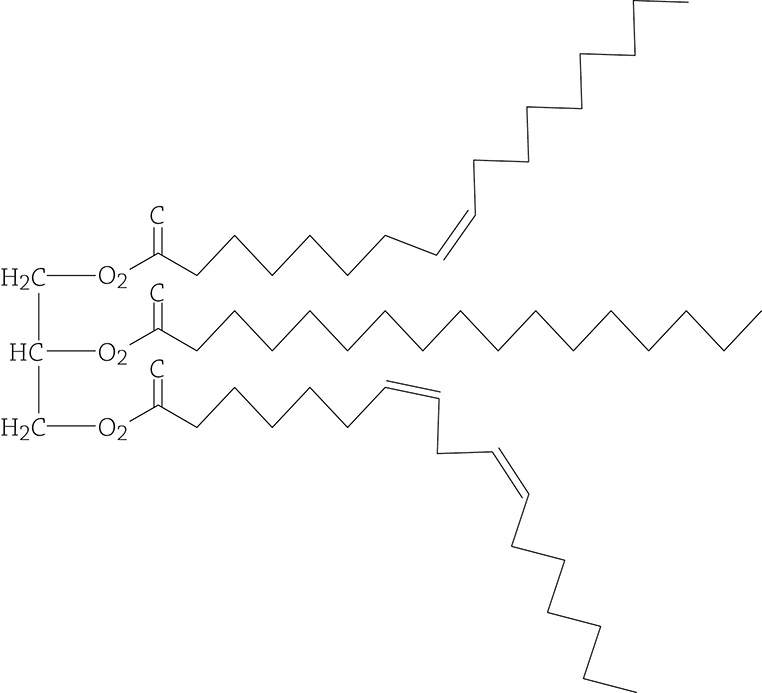
Unsaturated fat molecule. The double bond within the fatty acid tails make an irregular “kink” in the chain.
If, instead, each of the three fatty acids attached to the glycerol are saturated, there are only single bonds and the chains lie relatively flat. These saturated fats can pack tightly together, creating a solid at room temperature—butter and lard, for example.
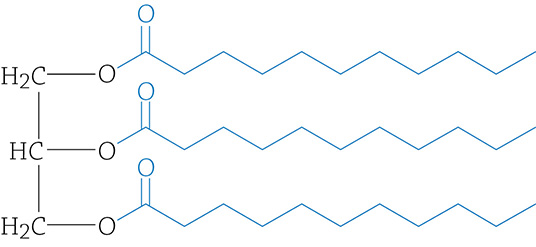
Saturated fat molecule. Since there are no double bonds within the fatty acid tails, they are straight and can pack tightly together
![]()
IRL
A good rule of thumb: Healthier fats are liquid at room temperature and tend to come from vegetables, nuts, and fish. Saturated fats are not that good for you, and come from sources such as red meat, cheese, and coconut oil.
Phospholipids
Now we will discuss possibly the most important lipid in the subject of biology. Indeed, if it wasn’t for phospholipids, life would not exist! The basic building block of life is the cell, and a cell is made of a cell membrane that separates the surrounding environment from the inside of the cell. The major component of all cell membranes is the phospholipid:
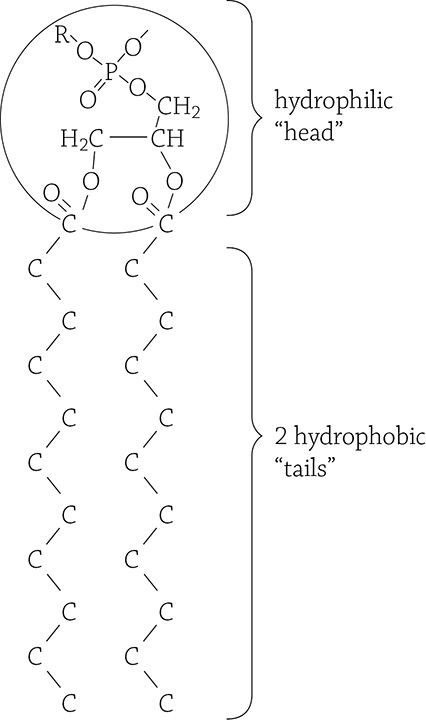
Phospholipid molecule. This is a simplified structural formula because the hydrogens on the two fatty acid tails have been omitted.
Notice that a phospholipid looks very similar to a fat: there is a glycerol backbone onto which two fatty acids are attached by a dehydration reaction. The major difference, however, is instead of a third fatty acid, there is a phosphate group. This is super significant! Look closely and you will notice that the phosphate group is charged. Any sort of positive or negative charge makes that part of the molecule polar, and polar things love water. The two nonpolar fatty acid chains remain hateful of water. So, unlike the fat molecule that is entirely hydrophobic, this molecule is half hydrophobic (the long carbon tails) and half hydrophilic (the phosphate group). The dual-nature of phospholipids is referred to as amphipathic. Something cool happens when a ton of these amphipathic molecules are dumped into water—they spontaneously arrange themselves in such a way that both parts of the molecule are happy!
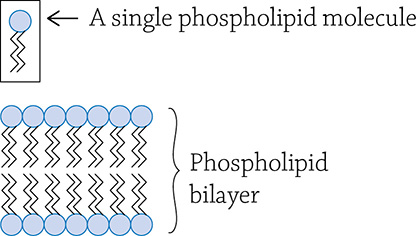
Cell membrane; also called a phospholipid bilayer
This allowed the formation of cell membranes, the must know major and important function of phospholipids. You will learn much more about phospholipid bilayers in Part Two (Cells).
Proteins
Proteins are important. Not too surprising, considering the genes in your DNA code for proteins. Proteins perform many must know functions for the cell, including the examples provided below:
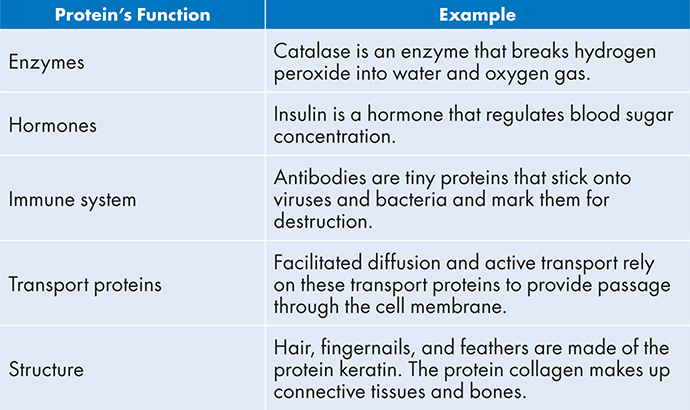
Proteins (also called polypeptides) are polymers made of amino acids (the monomer). Each amino acid is attached to a growing chain of protein by the lovely dehydration reaction we keep referring to. The resulting covalent bond between amino acid monomers is called a peptide bond:
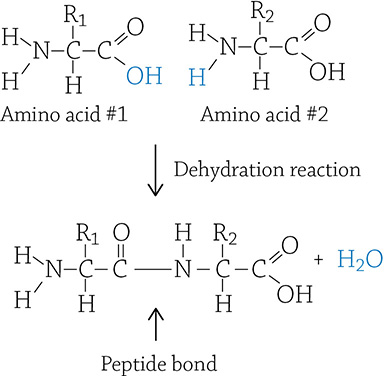
Two amino acid monomers being linked through a dehydration reaction
If you look at the image above, you can see the basic structure of an amino acid. The “R” means the “rest” of the molecule, which can be one of 20 different things (there are 20 different amino acids). Each amino acid’s R group determines its chemical properties, such as polar, nonpolar, or charged. This matters because the properties of the amino acid have an impact on the protein’s overall function.
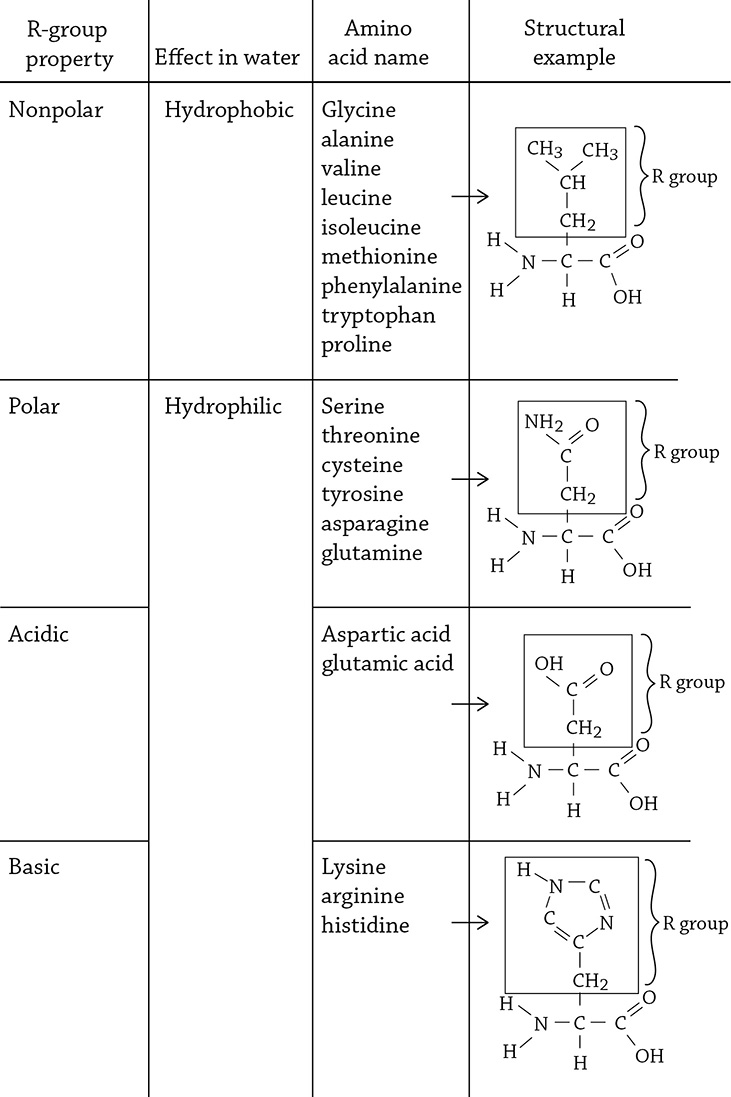
Amino acids categorized by the property of their side chain (R group)
The sequence of amino acids that makes up a protein is the protein’s primary structure. The human muscle protein titin, for example, holds the crown for longest primary structure: titin is composed of a whopping 30,000 amino acids (give or take a few thousand).
A long protein doesn’t remain a boring straight chain of amino acids, however—instead, the repeating amino acid backbones (not the R groups) hydrogen-bond to one another in a repeated, regular fashion. A protein’s secondary structure can be, for example, a helix:
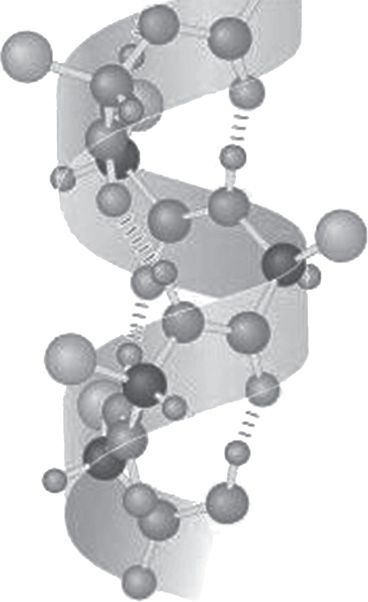
Protein secondary structure (a helix). The dashed lines indicate hydrogen bonds occurring between an oxygen atom and a hydrogen hanging off of a nitrogen atom.
Author: National Institutes of Health. https://commons.wikimedia.org/wiki/File:AlphaHelixProtein.jpg
It gets interesting at the tertiary structure level. Here, those individual amino acid R groups really start to matter. The protein will fold into a seemingly random blob dictated by interactions between R groups. For example, if there’s a number of nonpolar amino acids in the protein, they will cluster together at the core of the protein to try and “hide” from water that surrounds the protein. The 3D structure of a protein is extremely important to its function—just consider an enzyme. Enzymes are proteins that catalyze (speed up) reactions by grabbing onto other molecules (the enzyme’s substrate). An enzyme has a specific location called an active site that perfectly fits its substrate like a key fits a lock, and this shape is dictated by the amino acids that are part of the protein’s primary structure. The figure below is the large, blobby, tertiary shape of the bacterial enzyme isocitrate dehydrogenase:
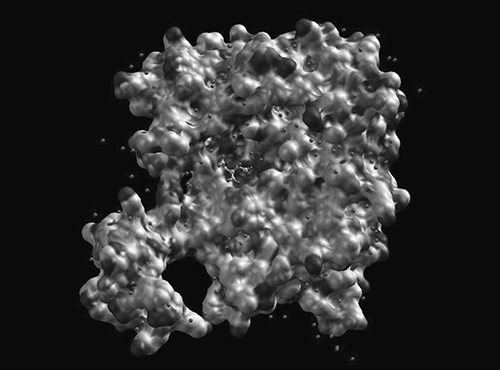
Isocitrate dehydrogenase from E. coli. Each small sphere indicates an individual amino acid.
Author: Haynathart. https://commons.wikimedia.org/w/index.php?search=enzyme+structure&title=Special%3ASearch&profile=default&fulltext=1#/media/File:Ecoli_IDH_with_surface_pocket.jpg
My favorite example for the levels (and significance) of protein structure is the protein hemoglobin, responsible for carrying oxygen in red blood cells. Hemoglobin forms a quaternary structure, meaning there are two or more individual proteins that come together to form the functional unit. Hemoglobin consists of two alpha subunits and two beta subunits, and they fit together in happy functional harmony:
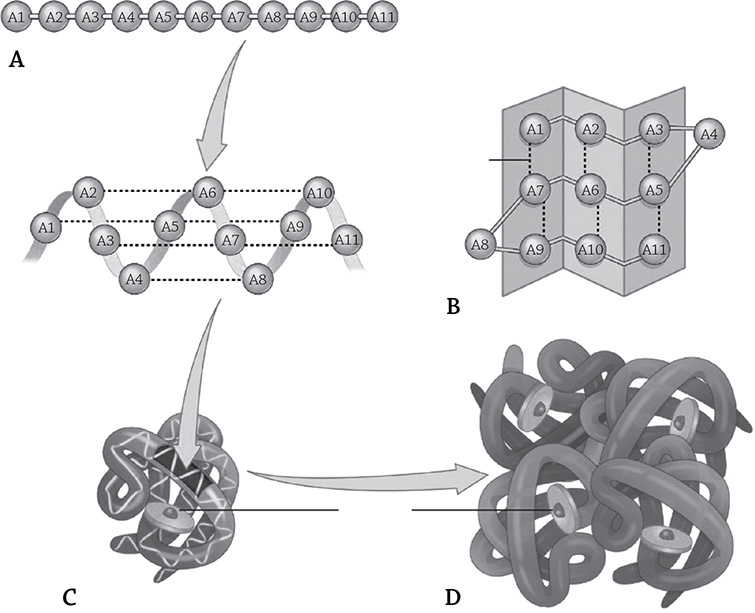
The four levels of hemoglobin structure. The primary level (A) indicates the sequence of amino acids that make up the protein, which then folds into a regulated, repeated folding pattern (second structure, B). The protein forms a particular 3D shape (tertiary structure, C), based on the amino acids’ R groups. Finally, four individual proteins come together to create hemoglobin’s large quaternary structure (D).
Author: OpenStax. https://commons.wikimedia.org/w/index.php?search=hemoglobin+quaternary+structure&title=Special:Search&profile=default&fulltext=1#/media/File:225_Peptide_Bond-01_labeled.jpg
To really stress the importance of primary structure, consider the seemingly insignificant difference between a healthy hemoglobin molecule, and one that leads to the disease sickle cell anemia. A mutation occurs that effects only one amino acid: a glutamic acid is changed into a valine. Think back to those different categories of amino acids: valine is hydrophobic, whereas the original glutamic acid is hydrophilic. This minor change in the primary sequence doesn’t have any effect on the secondary structure, because the regular folding doesn’t have a thing to do with the different side chains. But now in the tertiary structure, there’s a new hydrophobic region that’s uncomfortably exposed to the water surrounding the protein. Get a bunch of these mutated and misfolded hemoglobin molecules into a red blood cell, and then you really have a problem. The hemoglobin molecules clump together in order to hide those hydrophobic bits, and the protein ends up crystallizing into a fiber that not only cannot carry oxygen very well, but it also causes the red blood cells to become deformed and sickle-shaped. These unfortunately shaped little cells clog tiny arteries and cause big circulation problems.
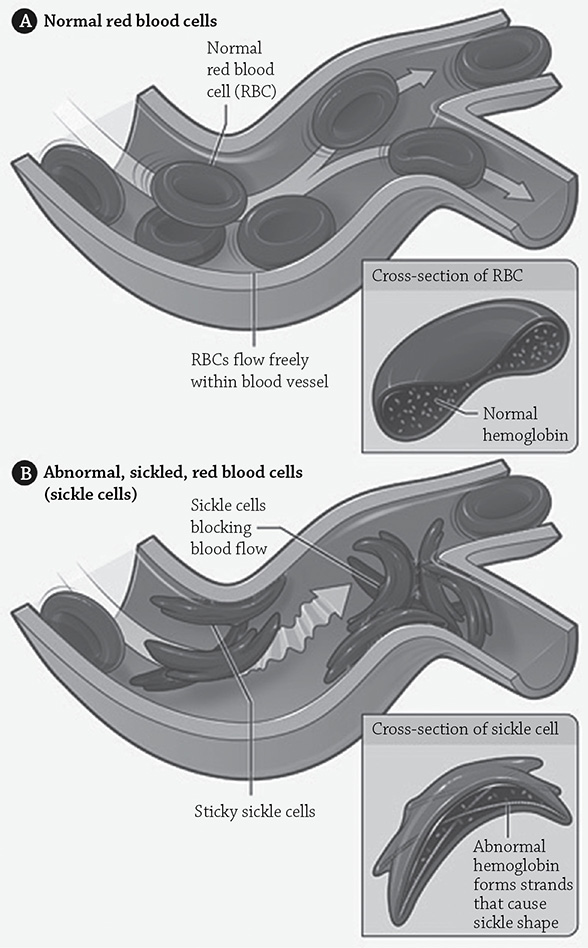
Sickled, red blood cells
Author: The National Heart, Lung, and Blood Institute (NHLBI). https://commons.wikimedia.org/w/index.php?search=hemoglobin+sickle+cell&title=Special:Search&profile=default&fulltext=1#/media/File:Sickle_cell_01.jpg
All of these structural issues in the complex tertiary and quaternary structures of hemoglobin were because of a single amino acid change in the protein’s primary structure!
Nucleic Acids
The final large macromolecule we will talk about is arguably the most important, because it is the “brains” of any cell: nucleic acid. There are two kinds of nucleic acid: deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). All nucleic acids are polymers composed of individual monomers called nucleotides:
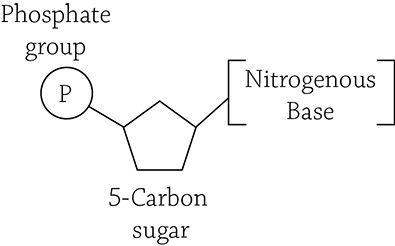
Simplified structure of a nucleotide
Each nucleotide has three parts to it: a phosphate group, a sugar, and a nitrogen-containing base. These nucleotides are glued together through dehydration reactions that create strong covalent bonds between alternating sugar and phosphate groups. This forms the “backbone” of the nucleic acid polymer. However, the part of the monomer that matters the most is the nitrogenous (nitrogen-containing) base. DNA has four different kinds of bases: adenine, thymine, guanine, and cytosine. RNA has three of the same, except instead of thymine it has uracil. All of these bases fit into one of two categories: purines or pyrimidines. Purines are double-ringed structures and include adenine and guanine, whereas pyrimidines are single-ringed structures and include thymine, cytosine, and uracil. You will learn more detail about this later, when we study genetics.
There are different types of RNA and they perform different tasks for the cell. Messenger RNA (mRNA), for example, carries the directions to make a protein from the nuclear-imprisoned genes to the protein-building ribosomes in the cytoplasm. Some RNA molecules play an important role in regulating gene expression, such as little micro RNAs or small interfering RNAs. Others carry amino acids over to the ribosome for protein synthesis (transfer RNA), and help the ribosome synthesize the final protein product (ribosomal RNA). Each of these interesting RNAs will be discussed later.
In general, all RNA nucleotides contain a sugar called ribose and are single-stranded molecules, unlike their chemical cousin, DNA, a large double-stranded molecule constructed with the sugar deoxyribose. The double-stranded nature of DNA is extremely important, something we will discuss later. For now, notice that the two strands of a DNA molecule are complementary to one another. They are both composed of nucleotides, the upright portion of which is made of alternating sugar-phosphate groups bonded strongly together by covalent bonds. The nitrogenous base portion points toward the middle of the two strands, and is the source of the hydrogen bonding that holds the two strands together. If one strand has an adenine nucleotide, it must pair with a thymine nucleotide on the complementary strand; a guanine nucleotide pairs with a cytosine nucleotide. Furthermore, these two strands are called antiparallel because they run in opposite directions. The end with the free phosphate group is referred to as the 5′ (five-prime) end, and the free hydroxyl (-OH) group is the 3′ (three-prime) end. These numbers indicate which carbon of the sugar the phosphate or hydroxyl group is hanging off of:
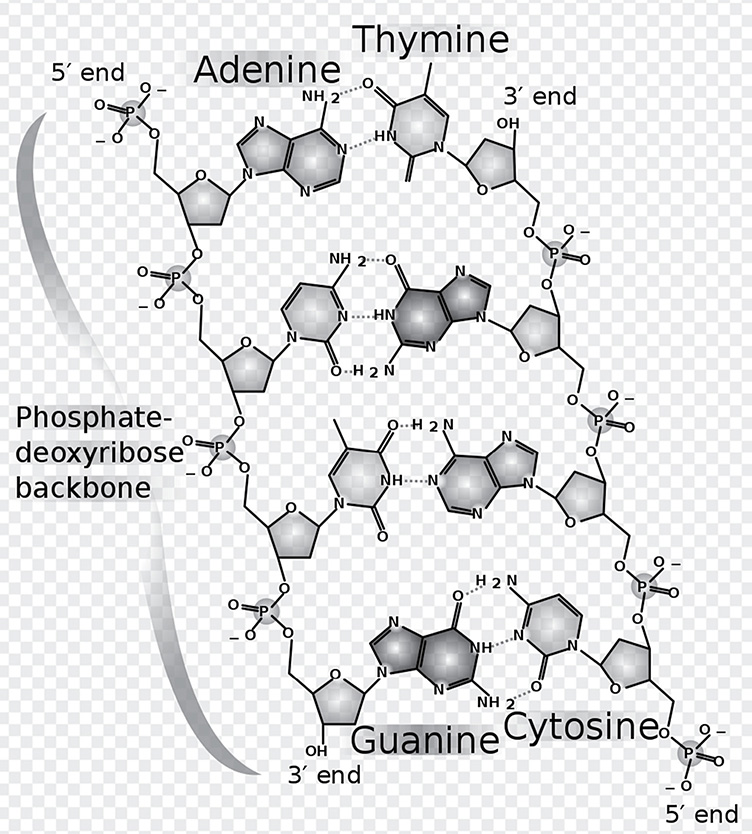
Chemical structure of DNA, with colored label identifying the four bases as well as the phosphate and deoxyribose components of the backbone
Author: Madeleine Price Ball. https://commons.wikimedia.org/wiki/File:DNA_chemical_structure.svg
All of these macromolecules work together in different ways to create the both the structure of the cell and to perform its various functions. As we progress through the book, proteins, nucleic acids, lipids, and carbohydrates will be mentioned time and time again in their various roles and functions.
REVIEW QUESTIONS
1. Fill in the blanks: A polymer is a large _________________ (term for large molecule) that is composed of repeating subunits called _________________.
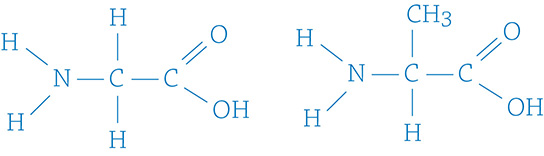
2. Given these two amino acid monomers, show the resulting peptide bond that would form after a dehydration reaction.
3. Match the macromolecule with its function:

4. List three differences between DNA and RNA.
5. Explain why the base-pairing rules exist. Why, exactly, must adenine base-pair with thymine, and guanine base-pair with cytosine?
6. Match the macromolecule with its function:

7. Choose the correct term: If a protein’s primary sequence had a bunch of hydrophilic amino acids, you would expect them to hide from/face toward water.
8. Choose the correct term: When you digest starch, dehydration/hydrolysis enzymes work at breaking up the starch polymer.
9. Hemoglobin is the protein in red blood cells that carries oxygen throughout the circulatory system. The hemoglobin molecule is made up of four total protein chains (four subunits) clumped together. Two of the protein chains (the alpha subunits) are made of 141 amino acids each. The other two proteins (the beta subunits) are made of 146 amino acids each. Based on this information, which of the four levels of protein structure is described?
