THE LIVING WORLD
Unit two. The Living Cell
3.3. Nucleic Acids
Very long polymers called nucleic acids serve as the information storage devices of cells, just as CDs or hard drives store the information that computers use. Nucleic acids are long polymers of repeating subunits called nucleotides. Each nucleotide is a complex organic molecule composed of three parts shown in figure 3.9a: a five-carbon sugar (in blue), a phosphate group (in yellow, PO4), and an organic nitrogen-containing base (in orange). In the formation of a nucleic acid, the individual sugars with their attached nitrogenous bases are linked in a line by the phosphate groups in very long polynucleotide chains (shown to the right).
How does the long, chainlike structure of a nucleic acid permit it to store the information necessary to specify what a human being is like? If nucleic acids were simply a monotonous repeating polymer, it could not encode the message of life. Imagine trying to write a story using only the letter E and no spaces or punctuation. All you could ever say is “EEEEEEE. . . ” You need more than one letter to communicate—the English alphabet uses 26 letters. Nucleic acids can encode information because they contain more than one kind of nucleotide. There are five different kinds of nucleotides: two larger ones that contain the nitrogenous bases adenine and guanine (shown in the top row of figure 3.9b), and three smaller ones that contain the nitrogenous bases cytosine, thymine, and uracil (in the bottom row). Nucleic acids encode information by varying the identity of the nucleotide at each position in the polymer.
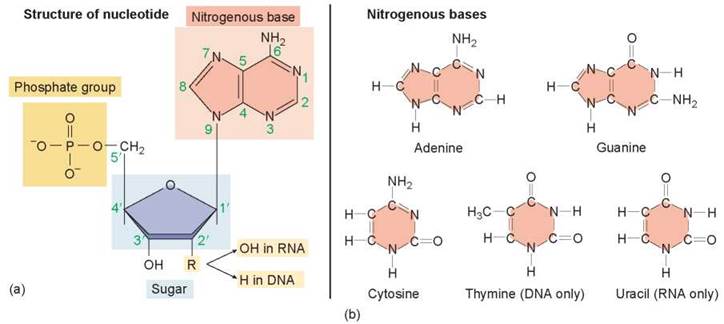
Figure 3.9. The structure of a nucleotide.
(a) Nucleotides are composed of three parts: a five-carbon sugar, a phosphate group, and an organic nitrogenous base. (b) The nitrogenous base can be one of five.
DNA and RNA
Nucleic acids come in two varieties, deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both polymers of nucleotides with some differences. RNA is similar to DNA, but with two major chemical differences. First, RNA molecules contain the sugar ribose, in which the 2' carbon (this is the carbon labeled 2' in figure 3.9a) is bonded to a hydroxyl group (—OH). In DNA, this hydroxyl group is replaced with a hydrogen atom. Second, RNA molecules do not contain the thymine nucleotide; they contain uracil instead. Structurally, RNA is also different. RNA is a long, single strand of nucleotides and is used by cells in making proteins using genetic instructions encoded within DNA. The sequence of nucleotides in DNA determines the order of amino acids in the primary structure of the protein. DNA consists of two polynucleotide chains wound around each other in a double helix, like strands of a pearl necklace twisted together. You can see this difference in structure by comparing the blue double-stranded DNA molecule in figure 3.10 with the green single-stranded RNA molecule.
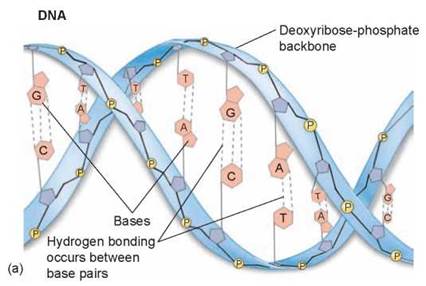
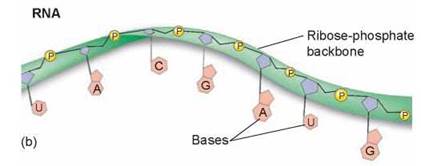
Figure 3.10. How DNA structure differs from RNA.
(a) DNA contains two polynucleotide strands wrapped around each other, while (b) RNA is single-stranded.
The Double Helix
Why is DNA a double helix? When scientists looked carefully at the structure of the DNA double helix, they found that the bases of each chain point inward toward the other (like the DNA strands shown in figure 3.11). The bases of the two chains are linked in the middle of the molecule by hydrogen bonds (the dotted lines between the two strands), like two columns of people holding hands across. The key to understanding why DNA is a double helix is revealed by looking at the bases: only two base pairs are possible. Because the distance between the two strands is consistent, this suggests that two big bases cannot pair together—the combination is simply too bulky to fit; similarly, two little ones cannot pair, as they pinch the helix inward too much. To form a double helix, it is necessary to pair a big base with a little one. In every DNA double helix, adenine (A) pairs with thymine (T) and guanine (G) pairs with cytosine (C). The reason A doesn’t pair with C and G doesn’t pair with T is that these base pairs cannot form proper hydrogen bonds—the electron-sharing atoms are not aligned with each other.
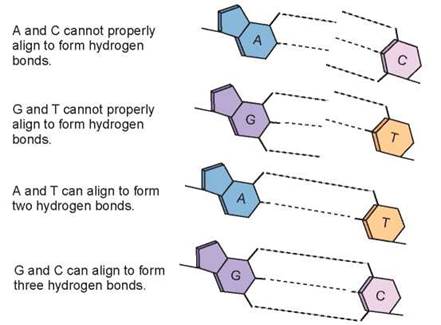
The simple A-T, G-C base pairs within the DNA double helix allow the cell to copy the information in a very simple way. It just unzips the helix and adds the complementary bases to each new strand! That is the great advantage of a double helix—it actually contains two copies of the information, one the mirror image of the other. If the sequence of one chain is ATTGCAT, the sequence of its partner in the double helix must be TAACGTA. The fidelity with which hereditary information is passed from one generation to the next is a direct result of this simple double-entry bookkeeping, which makes accurate copying of the genetic message possible.
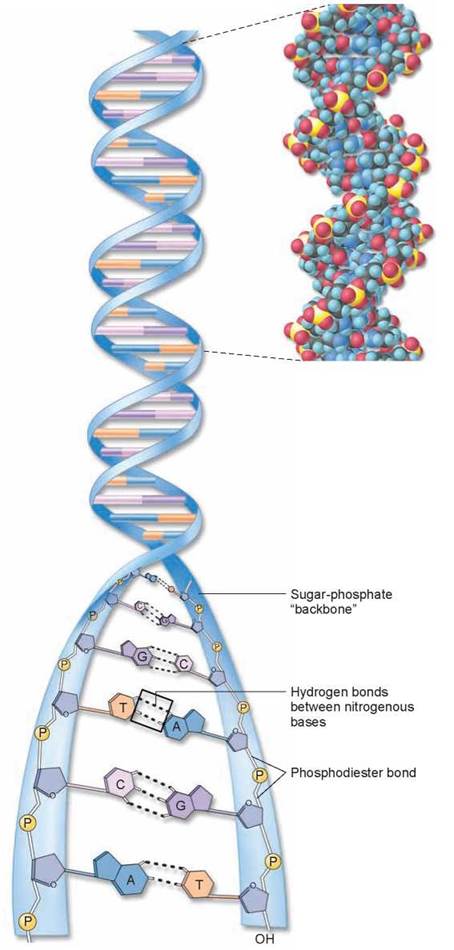
Figure 3.11. The DNA double helix.
The DNA molecule is composed of two polynucleotide chains twisted together to form a double helix. The two chains of the double helix are joined by hydrogen bonds between the A-T and G-C base pairs. The section of DNA on the upper right is a space-filling model of DNA, where atoms are indicated by colored balls.
Key Learning Outcome 3.3. Nucleic acids like DNA are composed of long chains of nucleotides. The sequence of the nucleotides specifies the amino acid sequence of proteins.
A Gloser Look
Discovering the Structure of DNA
By the middle of the last century, biologists were increasingly sure that DNA was the molecule that stored the hereditary information, but investigators were puzzled over how such a seemingly simple molecule could carry out such a complex function.
A key observation was made by chemist Erwin Chargaff shortly after the end of the Second World War. He noted that in DNA molecules, the amount of adenine, A, always equals the amount of thymine, T, and the amount of guanine, G, always equals the amount of cytosine, C. This observation (A=T, G=C), known as Chargaff's rule, strongly suggested that DNA has a regular structure, but did not reveal what it was.
The significance of the regularities pointed out by Chargaff were not immediately obvious, but they became clear when a young British chemist, Rosalind Franklin, carried out an X-ray diffraction analysis of DNA. In X-ray diffraction, a molecule is bombarded with a beam of X rays. When individual rays encounter atoms, their path is bent or diffracted, and the diffraction pattern is recorded on photographic film. The pattern that resulted using DNA resembled the ripples created by tossing a rock into a smooth lake. When carefully analyzed, a molecule's pattern can reveal information about the three-dimensional structure of the molecule.
X-ray diffraction works best on substances that can be prepared as perfectly regular crystalline arrays. However at the time of Franklin's analysis, it was impossible to obtain true crystals of natural DNA, so she had to use DNA in the form of fibers. Franklin worked in the same laboratory as Oxford biochemist Maurice Wilkins, who was able to prepare more uniformly oriented DNA fibers than anyone had previously. Using these fibers, Franklin succeeded in obtaining crude diffraction information on natural DNA. The diffraction patterns she obtained seemed to suggest that the DNA molecule had the shape of a coiled spring or corkscrew, a form called a helix.
Learning informally of Franklin's results before they were published in 1953, James Watson and Francis Crick, two young investigators at Cambridge University, quickly worked out a likely structure for the DNA molecule, which we now know was substantially correct. The key to their understanding the structure of DNA was Watson and Crick's insight that each DNA molecule is actually made up of two chains of nucleotides that are intertwined—a double helix.
In Watson and Crick's historic 1953 model (in the photograph, Watson is peering at the model as Crick points), each DNA molecule is composed of two complementary polynucleotide strands that form a double helix, with the bases extending into the interior of the helix. An analogy that is often made is to a spiral staircase where the two strands of the double helix are the handrails on the staircase.
What holds the two strands together? Watson and Crick proposed that the bases from opposite strands can form hydrogen bonds with each other to join the two complementary strands. Although each individual base pair is of low energy, the sum of many base pairs has enough energy that the molecule is very stable. To return to our spiral staircase analogy, where the backbone is the handrails, the base pairs are the stairs themselves.
Because of differences in size and position of particular atoms, only two hydrogen bonding pairs are possible in such a double helix: adenine (A) can form hydrogen bonds with thymine (T), and guanine (G) can form hydrogen bonds with cytosine (C). The Watson-Crick model thus, in a very direct and simple way, explained what had until then been one of the great mysteries of DNA, Chargaff's observation that adenine and thymine always occur in the same proportions in any DNA molecule, as do guanine and cytosine.
At the heart of the Watson-Crick model of DNA is a seemingly simple concept with some profound implications. Because only two base pairs are possible, if we know the sequence of one strand, we automatically know the sequence of the other strand; wherever there is an A in one strand, there must be a T in the other, and wherever there is a G in one strand, there must be a C in the other. This concept of a mirror-image relationship is called complementarity. You see the importance: If more than two base pairs were possible, then the sequence of one DNA strand would not allow us to know for sure the sequence of the other. It is this fundamental insight that has made Watson and Crick's discovery one of the most profound of the 20th century.
Watson and Crick continued on in the area of DNA research, but Franklin's career was cut short by her untimely death due to cancer at the age of 37.
