THE LIVING WORLD
Unit Three. The Continuity of Life
12.3. Translation
The essence of Mendelian genetics is that information determining hereditary traits, traits passed from parent to child, is encoded information. The information is written within the chromosomes in blocks called genes. Genes affect Mendelian traits by directing the production of particular proteins. The essence of gene expression, of using your genes, is reading the information encoded within DNA and using that information to produce proteins.
To correctly read a gene, a cell must translate the information encoded in DNA into the language of proteins— that is, it must convert the order of the gene’s nucleotides into the order of amino acids in a polypeptide, a process called translation. The rules that govern this translation are called the genetic code.
The mRNA is transcribed from a gene in a linear sequence, one nucleotide following another, beginning at the promoter. There, RNA polymerase binds to the DNA and begins its assembly of the mRNA. Transcription ends when the RNA polymerase reaches a certain nucleotide sequence that signals it to stop.
However, the mRNA is not translated in this same way. The mRNA is “read” by a ribosome in three-nucleotide units. Each three-nucleotide sequence of the mRNA is called a codon. Each codon, with the exception of three, codes for a particular amino acid. Biologists worked out which codon corresponds to which amino acid by trial-and-error experiments carried out in test tubes. In these experiments, investigators used artificial mRNAs to direct the synthesis of polypeptides in the tube, and then looked to see the sequence of amino acids in the newly formed polypeptides. An mRNA that was a string of UUUUUU . . . , for example, produced a polypeptide that was a string of phenylalanine (Phe) amino acids, telling investigators that the codon UUU corresponded to the amino acid Phe. The entire genetic code dictionary is presented in figure 12.4. The first letters of the codon are positioned down the left side, the second across the top, and the third down the right side. To determine the amino acid encoded by a codon, say AGC, go to “A” on the left, follow the row over to the “G” column, and go down to the C on the right. As you discover, AGC encodes the amino acid serine. Because at each position of a three-letter codon, any of the four different nucleotides (U, C, A, G) may be used, there are 64 different possible three-letter codons (4 x 4 x 4 = 64) in the genetic code.
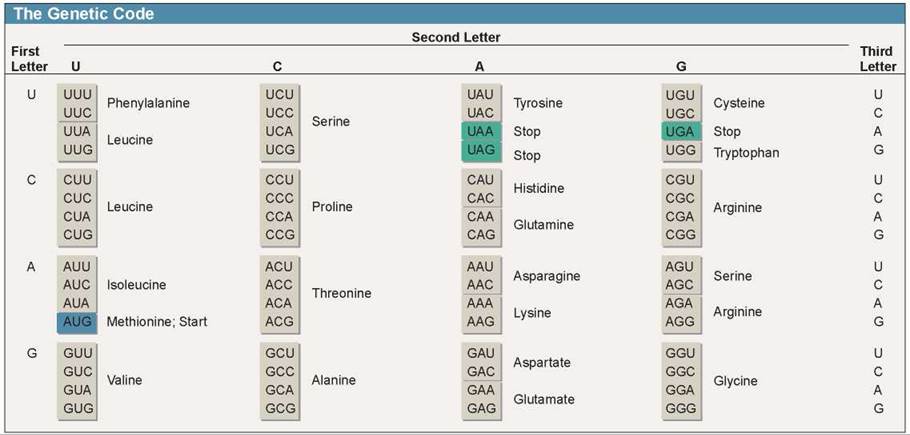
Figure 12.4. The genetic code (RNA codons).
A codon consists of three nucleotides read in sequence. For example, ACU codes for threonine. The first letter, A, is in the First Letter column; the second letter, C, is in the Second Letter row; and the third letter, U, is in the Third Letter column. Most amino acids are specified by more than one codon. For example, threonine is specified by four codons, which differ only in the third nucleotide (ACU, ACC, ACA, and ACG).
The genetic code is universal, the same in practically all organisms. GUC codes for valine in bacteria, in fruit flies, in eagles, and in your own cells. The only exception biologists have ever found to this rule is in the way in which cell organelles that contain DNA (mitochondria and chloroplasts) and a few microscopic protists read the “stop” codons. In every other instance, the same genetic code is employed by all living things.
Translating the RNA Message into Proteins
The final result of the transcription process is the production of an mRNA copy of a gene. Like a photocopy, the mRNA can be used without damage or wear and tear on the original. After transcription of a gene is finished, the mRNA passes out of the nucleus (in eukaryotes) and into the cytoplasm through pores in the nuclear membrane. There, translation of the genetic message occurs. In translation, organelles called ribosomes use the mRNA produced by transcription to direct the synthesis of a polypeptide following the genetic code.
The Protein-Making Factory. Ribosomes are the polypeptidemaking factories of the cell. Each is very complex, containing over 50 different proteins and several segments of ribosomal RNA (rRNA). Ribosomes use mRNA, the “blueprint” copies of nuclear genes, to direct the assembly of polypeptides, which are then combined into proteins.
Ribosomes are composed of two pieces, or subunits, one nested into the other like a fist in the palm of your hand. The “fist” is the smaller of the two subunits, the pink structure in figure 12.5. Its rRNA has a short nucleotide sequence exposed on the surface of the subunit. This exposed sequence is identical to a sequence called the leader region that occurs at the beginning of all genes. Because of this, an mRNA molecule binds to the exposed rRNA of the small subunit like a fly sticking to flypaper.
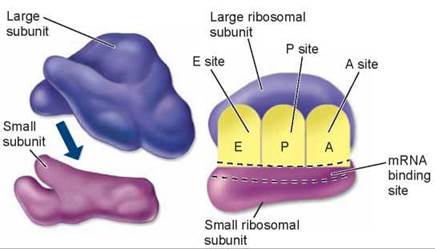
Figure 12.5. A ribosome is composed of two subunits.
The smaller subunit fits into a depression on the surface of the larger one. The A, P, and E sites on the ribosome play key roles in protein synthesis.
The Key Role of tRNA. Directly adjacent to the exposed rRNA sequence are three small pockets or dents, called the A, P, and E sites, in the surface of the ribosome (shown in figure 12.5 and discussed shortly). These sites have just the right shape to bind yet a third kind of RNA molecule, transfer RNA (tRNA). It is tRNA molecules that bring amino acids to the ribosome used in making proteins. The tRNA molecules are chains about 80 nucleotides long. The string of nucleotides folds back on itself, forming a three-looped structure shown in figure 12.6a. The looped structure further folds into a compact shape shown in figure 12.6b, with a three-nucleotide sequence at one end (the pink loop) and an amino acid attachment site on the other end (the 3’ end).

Figure 12.6. The structure of tRNA.
tRNA, like mRNA, is a long strand of nucleotides. However, unlike mRNA, hydrogen bonding occurs between its nucleotides, causing the strand to form hairpin loops, as seen in (a). The loops then fold up on each other to create the compact, three-dimensional shape seen in (b). Amino acids attach to the free, single-stranded —OH end of a tRNA molecule. A three-nucleotide sequence called the anticodon in the lower loop of tRNA interacts with a complementary codon on the mRNA.
The three-nucleotide sequence, called the anticodon, is very important: It is the complementary sequence to 1 of the 64 codons of the genetic code! Special enzymes, called activating enzymes, match amino acids in the cytoplasm with their proper tRNAs. The anticodon determines which amino acid will attach to a particular tRNA.
Because the first dent in the ribosome, called the A site (the attachment site where amino-acid-bearing tRNAs will bind) is directly adjacent to where the mRNA binds to the rRNA, three nucleotides of the mRNA are positioned directly facing the anticodon of the tRNA. Like the address on a letter, the anticodon ensures that an amino acid is delivered to its correct “address” on the mRNA where the ribosome is assembling the polypeptide.
Making the Polypeptide. Once an mRNA molecule has bound to the small ribosomal subunit, the other larger ribo- somal subunit binds as well, forming a complete ribosome. The ribosome then begins the process of translation, illustrated in the panels of the Key Biological Process illustration on the next page. Panel 1 shows how the mRNA begins to thread through the ribosome like a string passing through the hole in a doughnut. The mRNA passes through in short spurts, three nucleotides at a time, and at each burst of movement a new three-nucleotide codon on the mRNA is positioned opposite the A site in the ribosome, where a tRNA molecule first binds, as shown in panel 2.
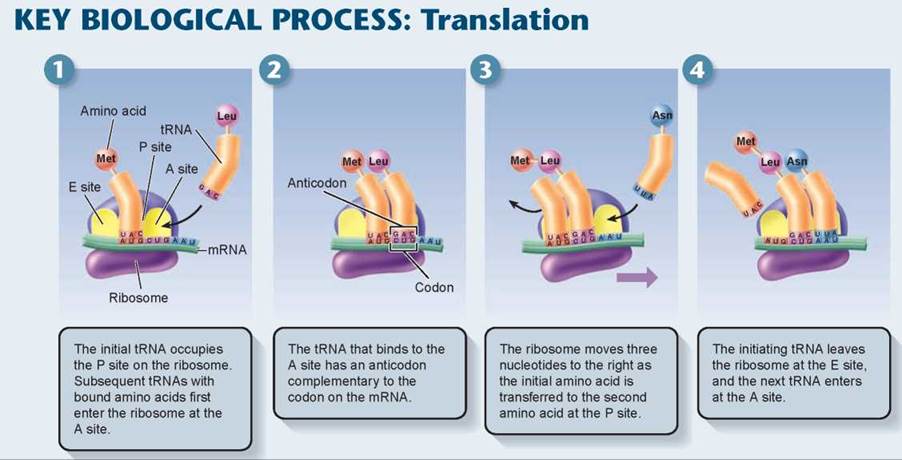
As each new tRNA brings in an amino acid to each new codon presented at the A site, the old tRNA paired with the previous codon is passed over to the P site where peptide bonds form between the incoming amino acid and the growing polypeptide chain. The tRNA in the P site eventually shifts to the E site (the exit site), as shown in panel 3, and the amino acid it carried is attached to the end of a growing amino acid chain. The tRNA is then released (panel 4). So as the ribosome proceeds down the mRNA, one tRNA after another is selected to match the sequence of mRNA codons. In figure 12.7 you can see the ribosome traveling along the length of the mRNA, the tRNAs bringing the amino acids into the ribosome and the growing polypeptide chain extending out from the ribosome. Translation continues until a “stop” codon is encountered, which signals the end of the polypeptide. The ribosome complex falls apart, and the newly made polypeptide is released into the cell.
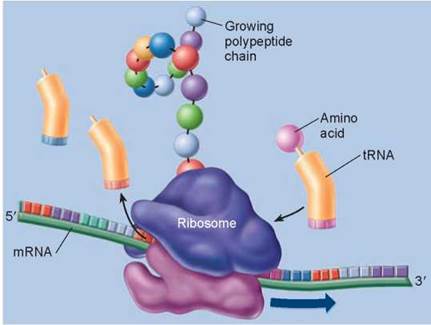
Figure 12.7. Ribosomes guide the translation process.
tRNA binds to an amino acid as determined by the anticodon sequence. Ribosomes bind the loaded tRNAs to their complementary sequences on the strand of mRNA. tRNA adds its amino acid to the growing polypeptide chain, which is released as the completed protein.
As explained earlier, the overall flow of genetic information, the so-called “Central Dogma,” is from DNA to mRNA to protein. For example, the polypeptide that is being formed in the Key Biological Process illustration above began with the DNA nucleotide sequence TACGACTTA, which is first transcribed into the mRNA sequence AUGCUGAAU. This sequence is then translated by the tRNAs into a polypeptide composed of the amino acids methionine—leucine—asparagine.
Key Learning Outcome 12.3. The genetic code dictates how a particular nucleotide sequence specifies a particular amino acid sequence. A gene is transcribed into mRNA, which is then translated into a polypeptide. The sequence of mRNA codons dictates the corresponding sequence of amino acids in a growing polypeptide chain.