Lippincott’s Illustrated Reviews: Biochemistr, Sixth Edition (2014)
UNIT VI: Storage and Expression of Genetic Information
Chapter 30. RNA Structure, Synthesis, and Processing
I. OVERVIEW
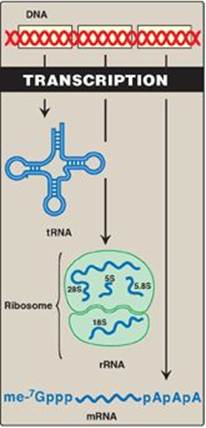
The genetic master plan of an organism is contained in the sequence of deoxyribonucleotides in its deoxyribonucleic acid (DNA). However, it is through the ribonucleic acid (RNA), the “working copies” of the DNA, that the master plan is expressed (Figure 30.1). The copying process, during which a DNA strand serves as a template for the synthesis of RNA, is called transcription. Transcription produces messenger RNAs (mRNAs) that are translated into sequences of amino acids (polypeptide chains or proteins) and ribosomal RNAs (rRNAs), transfer RNAs (tRNAs), and additional small RNA molecules that perform specialized structural, catalytic, and regulatory functions and are not translated. That is, they are noncoding RNAs (ncRNAs). [Note: Only about 2% of the genome codes for proteins.] The final product of gene expression, therefore, can be RNA or protein, depending upon the gene. A central feature of transcription is that it is highly selective. For example, many transcripts are made of some regions of the DNA. In other regions, few or no transcripts are made. This selectivity is due, at least in part, to signals embedded in the nucleotide sequence of the DNA. These signals instruct the RNA polymerase where to start, how often to start, and where to stop transcription. A variety of regulatory proteins is also involved in this selection process. The biochemical differentiation of an organism’s tissues is ultimately a result of the selectivity of the transcription process. [Note: This selectivity of transcription is in contrast to the “all-or-none” nature of genomic replication.] Another important feature of transcription is that many RNA transcripts that initially are faithful copies of one of the two DNA strands may undergo various modifications, such as terminal additions, base modifications, trimming, and internal segment removal, which convert the inactive primary transcript into a functional molecule.
Figure 30.1 Expression of genetic information by transcription. [Note: RNAs shown are eukaryotic.] tRNA = transfer RNA; rRNA = ribosomal RNA; mRNA = messenger RNA; me-7Gppp = 7-methylguanosine triphosphate “cap;” AAA = poly-A “tail,” each described on p. 418.
II. STRUCTURE OF RNA
There are three major types of RNA that participate in the process of protein synthesis: rRNA, tRNA, and mRNA. Like DNA, these three types of RNA are unbranched polymeric molecules composed of nucleoside monophosphates joined together by 3ʹ→5ʹ-phosphodiester bonds (see p. 396). However, they differ from DNA in several ways. For example, they are considerably smaller than DNA, contain ribose instead of deoxyribose and uracil instead of thymine, and exist as single strands that are capable of folding into complex structures. The three major types of RNA also differ from each other in size, function, and special structural modifications. [Note: In eukaryotes, additional small ncRNA molecules found in the nucleolus (snoRNAs), nucleus (snRNA), and cytoplasm (miRNA) perform specialized functions as described on pp. 425, 426, and 459.]
Figure 30.2 Prokaryotic and eukaryotic ribosomal RNAs (rRNAs). S = Svedberg unit.

A. Ribosomal RNA
rRNAs are found in association with several proteins as components of the ribosomes, the complex structures that serve as the sites for protein synthesis (see p. 436). There are three distinct size species of rRNA (23S, 16S, and 5S) in prokaryotic cells (Figure 30.2). In the eukaryotic cytosol, there are four rRNA species (28S, 18S, 5.8S, and 5S, where “S” is the Svedberg unit for sedimentation rate, which is determined by the size and shape of the particle.) Together, rRNAs make up about 80% of the total RNA in the cell. [Note: Some RNAs function as catalysts, for example, an rRNA in protein synthesis (see p. 439). RNA with catalytic activity is termed a “ribozyme.”]
B. Transfer RNA
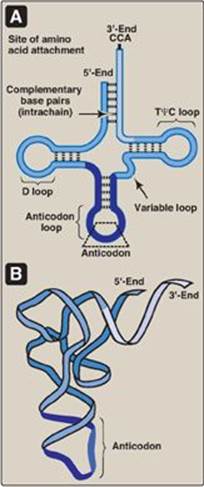
tRNAs are the smallest (4S) of the three major types of RNA molecules. There is at least one specific type of tRNA molecule for each of the 20 amino acids commonly found in proteins. Together, tRNAs make up about 15% of the total RNA in the cell. The tRNA molecules contain a high percentage of unusual bases, for example, dihydrouracil (see Figure 22.2, p. 292) and have extensive intrachain base-pairing (Figure 30.3) that leads to characteristic secondary and tertiary structure. Each tRNA serves as an “adaptor” molecule that carries its specific amino acid, covalently attached to its 3ʹ-end, to the site of protein synthesis. There it recognizes the genetic code sequence on an mRNA, which specifies the addition of its amino acid to the growing peptide chain (see p. 432).
C. Messenger RNA
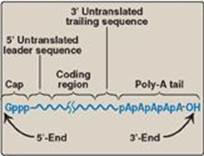
mRNA comprises only about 5% of the RNA in the cell, yet is by far the most heterogeneous type of RNA in size and base sequence. mRNA carries genetic information from DNA for use in protein synthesis. In eukaryotes, this involves transfer of mRNA out of the nucleus and into the cytosol. If the mRNA carries information from more than one gene, it is said to be polycistronic (cistron = gene). Polycistronic mRNA is characteristic of prokaryotes. If the mRNA carries information from just one gene, it is said to be monocistronic and is characteristic of eukaryotes. In addition to the protein-coding regions that can be translated, mRNA contains untranslated regions at its 5ʹ- and 3ʹ-ends (Figure 30.4). Special structural characteristics of eukaryotic (but not prokaryotic) mRNA include a long sequence of adenine nucleotides (a poly-A “tail”) on the 3ʹ-end of the RNA chain, plus a “cap” on the 5ʹ-end consisting of a molecule of 7-methylguanosine attached through an unusual (5ʹ→5ʹ) triphosphate linkage. The mechanisms for modifying mRNA to create these special structural characteristics are discussed on p. 425.
Figure 30.3 A. Characteristic transfer RNA (tRNA) secondary structure (cloverleaf). B. Folded (tertiary) tRNA structure found in cells. D = dihydrouracil; Ψ = pseudouracil; T = thymine; C = cytosine; A = adenine.
III. TRANSCRIPTION OF PROKARYOTIC GENES
The structure of RNA polymerase (RNA pol), the signals that control transcription, and the varieties of modification that RNA transcripts can undergo differ among organisms, and particularly from prokaryotes to eukaryotes. Therefore, the discussions of prokaryotic and eukaryotic transcription are presented separately.
Figure 30.4 Structure of eukaryotic messenger RNA.
A. Properties of prokaryotic RNA polymerase
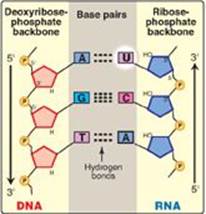
In bacteria, one species of RNA pol synthesizes all of the RNA except for the short RNA primers needed for DNA replication [Note: RNA primers are synthesized by a specialized enzyme, primase (see p. 402).] RNA pol is a multisubunit enzyme that recognizes a nucleotide sequence (the promoter region) at the beginning of a length of DNA that is to be transcribed. It next makes a complementary RNA copy of the DNA template strand, and then recognizes the end of the DNA sequence to be transcribed (the termination region). RNA is synthesized from its 5ʹ-end to its 3ʹ-end, antiparallel to its DNA template strand (see p. 397). The template is copied as it is in DNA synthesis, in which a guanine (G) on the DNA specifies a cytosine (C) in the RNA, a C specifies a G, a thymine (T) specifies an adenine (A), but an A specifies a uracil (U) instead of a T (Figure 30.5). The RNA, then, is complementary to the DNA template (antisense, minus) strand and identical to the coding (sense, plus) strand, with U replacing T. Within the DNA molecule, regions of both strands can serve as templates for transcription. For a given gene, however, only one of the two DNA strands can be the template. Which strand is used is determined by the location of the promoter for that gene. Transcription by RNA pol involves a core enzyme and several auxiliary proteins:
Figure 30.5 Antiparallel, complementary base pairs between DNA and RNA. T= thymine; A = adenine; C = cytosine; G = guanine; U = uracil.
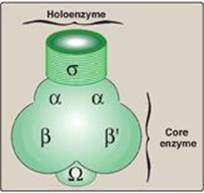
1. Core enzyme: Five of the enzyme’s peptide subunits, 2α, 1β, 1βʹ, and 1Ω, are required for enzyme assembly (α, Ω) template binding (βʹ), and the 5ʹ→3ʹ RNA polymerase activity (β), and are referred to as the core enzyme (Figure 30.6). However, this enzyme lacks specificity (that is, it cannot recognize the promoter region on the DNA template).
2. Holoenzyme: The s subunit (“sigma factor”) enables RNA pol to recognize promoter regions on the DNA. The s subunit plus the core enzyme make up the holoenzyme. [Note: Different s factors recognize different groups of genes.]
B. Steps in RNA synthesis
The process of transcription of a typical gene of Escherichia coli (E. coli) can be divided into three phases: initiation, elongation, and termination. A transcription unit extends from the promoter to the termination region, and the initial product of transcription by RNA pol is termed the primary transcript.
Figure 30.6 Components of prokaryotic RNA polymerase.
1. Initiation: Transcription begins with the binding of the RNA pol holoenzyme to a region of the DNA known as the promoter, which is not transcribed. The prokaryotic promoter contains characteristic consensus sequences (Figure 30.7). [Note: Consensus sequences are idealized sequences in which the base shown at each position is the base most frequently (but not necessarily always) encountered at that position.] Those that are recognized by prokaryotic RNA polymerase s factors include:
Figure 30.7 Structure of the prokaryotic promoter region. T = thymine; G = guanine; A = adenine; C = cytosine.
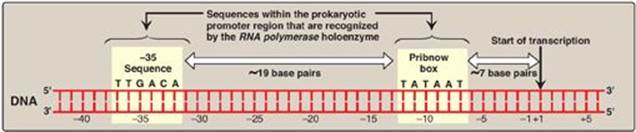
a. –35 Sequence: A consensus sequence (5-TTGACA-3), centered about 35 bases to the left of the transcription start site (see Figure 30.7), is the initial point of contact for the holoenzyme, and a closed complex is formed. [Note: The regulatory sequences that control transcription are, by convention, designated by the 5→3 nucleotide sequence on the coding strand. A base in the promoter region is assigned a negative number if it occurs prior to (to the left of, toward the 5ʹ-end of, or “upstream” of) the transcription start site. Therefore, the TTGACA sequence is centered at approximately base –35. The first base at the transcription start site is assigned a position of +1. There is no base designated “0”.]
b. Pribnow box: The holoenzyme moves and covers a second consensus sequence (5ʹ-TATAAT-3ʹ), centered at about –10 (see Figure 30.7), which is the site of initial DNA melting (unwinding). Melting of a short stretch (about 14 bases) converts the closed complex to an open complex known as a transcription bubble. [Note: A mutation in either the –10 or the –35 sequence can affect the transcription of the gene controlled by the mutant promoter.]
Figure 30.8 Local unwinding of DNA caused by RNA polymerase and formation of an open initiation complex.
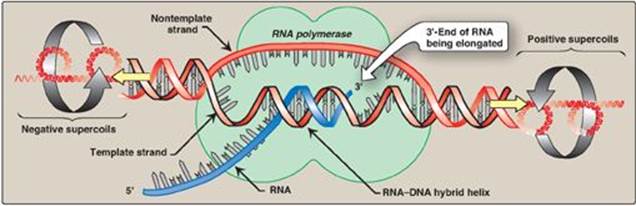
2. Elongation: Once the promoter region has been recognized and bound by the holoenzyme, local unwinding of the DNA helix continues (Figure 30.8), mediated by the polymerase. [Note: Unwinding generates supercoils in the DNA that can be relieved by DNA topoisomerases (see p. 401.] RNA pol begins to synthesize a transcript of the DNA sequence, and several short pieces of RNA are made and discarded. The elongation phase is said to begin when the transcript (typically starting with a purine) exceeds ten nucleotides in length. Sigma is then released, and the core enzyme is able to leave (“clear”) the promoter and move along the template strand in a processive manner, serving as its own sliding clamp. During transcription, a short DNA–RNA hybrid helix is formed (see Figure 30.8). Like DNA pol, RNA pol uses nucleoside triphosphates as substrates and releases pyrophosphate each time a nucleoside monophosphate is added to the growing chain. As with replication, transcription is always in the 5ʹ→3ʹ direction. In contrast to DNA pol, RNA pol does not require a primer and does not appear to have 3ʹ→5ʹ exonuclease (proofreading) activity.
3. Termination: The elongation of the single-stranded RNA chain continues until a termination signal is reached. Termination can be intrinsic (spontaneous) or dependent upon the participation of a protein known as the ρ (rho) factor.
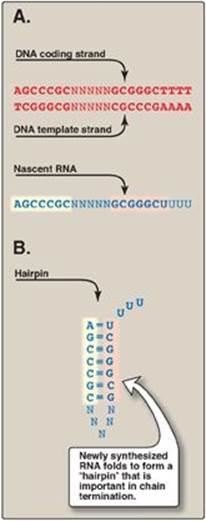
a. ρ-Independent termination: Seen with most prokaryotic genes, this requires that a sequence in the DNA template generates a sequence in the nascent (newly made) RNA that is self-complementary (Figure 30.9). This allows the RNA to fold back on itself, forming a GC-rich stem (stabilized by hydrogen bonds) plus a loop. This structure is known as a “hairpin.” Additionally, just beyond the hairpin, the RNA transcript contains a string of Us at the 3ʹ-end. The bonding of these Us to the complementary As of the DNA template is weak. This facilitates the separation of the newly synthesized RNA from its DNA template, as the double helix “zips up” behind the RNA polymerase.
b. r-Dependent termination: This requires the participation of an additional protein, rho (r), which is a hexameric ATPase with helicase activity. Rho binds a C-rich “rho recognition site” near the 5ʹ-end of the nascent RNA and, using its ATPase activity, moves along the RNA until it reaches the RNA pol paused at the termination site. The ATP-dependent helicase activity of r separates the RNA–DNA hybrid helix, causing the release of the RNA.
Figure 30.9 Rho-independent termination of prokaryotic transcription. A. DNA template sequence generates a self-complementary sequence in the nascent RNA. B. Hairpin structure formed by the RNA. “N” represents a noncomplementary base; A = adenine, T = thymine; G = guanine; C = cytosine; U = uracil. [Note: Termination of eukaryotic transcription is not well understood.]
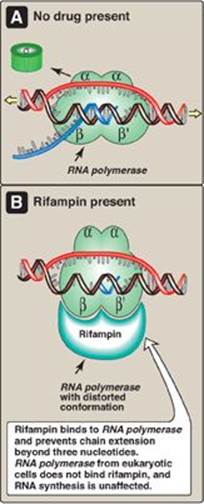
4. Action of antibiotics: Some antibiotics prevent bacterial cell growth by inhibiting RNA synthesis. For example, rifampin (rifampicin) inhibits transcription by binding to the β subunit of prokaryotic RNA pol, and preventing chain extension beyond three nucleotides (Figure 30.10). Rifampin is important in the treatment of tuberculosis. Dactinomycin (known to biochemists as actinomycin D) was the first antibiotic to find therapeutic application in tumor chemotherapy. It binds to the DNA template and interferes with the movement of RNA pol along the DNA.
IV. TRANSCRIPTION OF EUKARYOTIC GENES
The transcription of eukaryotic genes is a far more complicated process than transcription in prokaryotes. Eukaryotic transcription involves separate polymerases for the synthesis of rRNA, tRNA, and mRNA. In addition, a large number of proteins called transcription factors (TFs) are involved. TFs bind to distinct sites on the DNA either within the core promoter region, close (proximal) to it, or some distance away (distal). They are required both for the assembly of a transcription complex at the promoter and the determination of which genes are to be transcribed. [Note: Each eukaryotic RNA pol has its own promoters and TFs that bind core promoter sequences.] For TFs to recognize and bind to their specific DNA sequences, the chromatin structure in that region must be altered (relaxed) to allow access to the DNA. The role of transcription in the regulation of gene expression is discussed in Chapter 32.
A. Chromatin structure and gene expression
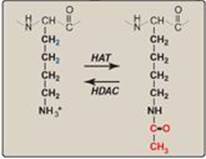
The association of DNA with histones to form nucleosomes (see p. 409) affects the ability of the transcription machinery to access the DNA to be transcribed. Most actively transcribed genes are found in a relatively relaxed form of chromatin called euchromatin, whereas most inactive segments of DNA are found in highly condensed heterochromatin. [Note: The interconversion of these forms is called chromatin remodeling.] A major component of chromatin remodeling is the covalent modification of histones (for example, the acetylation of lysine residues at the amino terminus of histone proteins) as shown in Figure 30.11. Acetylation, mediated by histone acetyltransferases (HATs), eliminates the positive charge on the lysine, thereby decreasing the interaction of the histone with the negatively charged DNA. Removal of the acetyl group by histone deacetylases (HDACs) restores the positive charge and fosters stronger interactions between histones and DNA. [Note: The ATP-dependent repositioning of nucleosomes is also required to access DNA.]
Figure 30.10 Inhibition of prokaryotic RNA polymerase by rifampin.
B. Nuclear RNA polymerases of eukaryotic cells
There are three distinct classes of RNA pol in the nucleus of eukaryotic cells. All are large enzymes with multiple subunits. Each class of RNA pol recognizes particular types of genes.
Figure 30.11 Acetylation/deacetylation of a lysine residue in a histone protein. HAT = histone acetyltransferase; HDAC = histone deacetylase.
1. RNA polymerase I: This enzyme synthesizes the precursor of the 28S, 18S, and 5.8S rRNA in the nucleolus.
2. RNA polymerase II: This enzyme synthesizes the nuclear precursors of mRNA that are subsequently translated to produce proteins. RNA pol II also synthesizes certain small ncRNAs, such as snoRNA (see p. 425), snRNA (see p. 426) and miRNA (see p. 459).
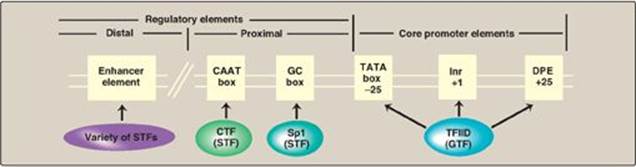
a. Promoters for RNA polymerase II: In some genes transcribed by RNA pol II, a sequence of nucleotides (TATAAA) that is nearly identical to that of the Pribnow box (see p. 420) is found centered about 25 nucleotides upstream of the transcription start site. This core promoter consensus sequence is called the TATA, or Hogness, box. In the majority of genes, however, no TATA box is present. Instead, different core promoter elements such as Inr (initiator) or DPE (downstream promoter element) are present (Figure 30.12). [Note: No one consensus sequence is found in all core promoters.] Because these sequences are on the same molecule of DNA as the gene being transcribed, they are cis-acting. The sequences serve as binding sites for proteins known as general transcription factors (GTFs), which in turn interact with each other and with RNA pol II.
Figure 30.12 Eukaryotic gene cis-acting promoter and regulatory elements and their trans-acting general and specific transcription factors (GTF and STF, respectively). Inr = initiator; DPE = downstream promoter element.
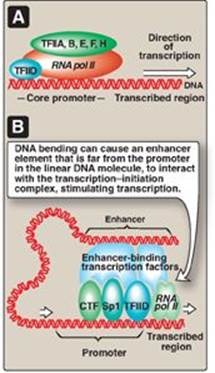
b. General transcription factors: These are the minimal requirements for recognition of the promoter, recruitment of RNA pol II to the promoter, and initiation of transcription at a basal level (Figure 30.13A). GTFs are encoded by different genes, synthesized in the cytosol, and transit to their sites of action, and so are trans-acting. [Note: In contrast to the prokaryotic holoenzyme, eukaryotic RNA pol II does not itself recognize and bind the promoter. Instead, TFIID, a GTF containing TATA-binding protein and TATA-associated factors, recognizes and binds the TATA box (and other core promoter elements). TFIIF, another GTF, brings the polymerase to the promoter. The helicase activity of TFIIH melts the DNA, and its kinase activity phosphorylates polymerase, allowing it to clear the promoter.]
c. Regulatory elements and transcriptional activators: Upstream of the core promoter are additional consensus sequences (see Figure 30.12). Those close to the core promoter (within 200 nucleotides) are the proximal regulatory elements, such as the CAAT and GC boxes. Those farther away are the distal regulatory elements such as enhancers (see p. 424). Proteins known as transcriptional activators or specific transcription factors (STFs) bind these regulatory elements. STFs bind to promoter proximal elements to regulate the frequency of transcription initiation, and to distal elements to mediate the response to signals such as hormones (see p. 456) and regulate which genes are expressed at a given point in time. A typical protein-coding eukaryotic gene has binding sites for many such factors. [Note: STFs have two binding domains. One is a DNA-binding domain, the other is a transcription activation domain that recruits the GTFs to the core promoter as well as “coactivator” proteins such as the HAT enzymes involved in chromatin modification.]
Figure 30.13 A. Association of the general transcription factors (TFIIs) and RNA polymerase II (RNA pol II) at the core promoters. [Note: The Roman numeral II denotes the TFs for RNA pol II.] B. Enhancer stimulation of transcription. CTF = CAAT box transcription factor; Sp1 = specificity factor-1.
Transcriptional activators bind DNA through a variety of motifs, such as the helix-loop-helix, zinc finger, and leucine zipper (see p. 18).
Figure 30.14 Some possible locations of enhancer sequences.
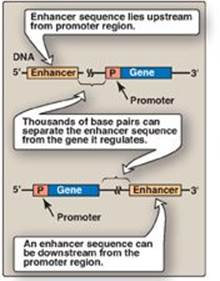
d. Role of enhancers in eukaryotic gene regulation: Enhancers are special DNA sequences that increase the rate of initiation of transcription by RNA pol II. Enhancers are typically on the same chromosome as the gene whose transcription they stimulate (Figure 30.13B). However, they can 1) be located upstream (to the 5ʹ-side) or downstream (to the 3ʹ-side) of the transcription start site, 2) be close to or thousands of base pairs away from the promoter (Figure 30.14), and 3) occur on either strand of the DNA. Enhancers contain DNA sequences called “response elements” that bind STFs (transcriptional activators). By bending or looping the DNA, these enhancer-binding proteins can interact with other transcription factors bound to a promoter and with RNA pol II, thereby stimulating transcription (see Figure 30.13B). [Note: Although silencers are similar to enhancers in that they also can act over long distances, they reduce gene expression.]
e. Inhibitors of RNA polymerase II: α-Amanitin, a potent toxin produced by the poisonous mushroom Amanita phalloides (sometimes called “the death cap”), forms a tight complex with RNA pol II, thereby inhibiting mRNA synthesis.
3. RNA polymerase III: This enzyme synthesizes tRNA, 5S rRNA, and some snRNA and snoRNA.
C. Mitochondrial RNA polymerase
Mitochondria contain a single RNA pol that more closely resembles bacterial RNA pol than the eukaryotic nuclear enzymes.
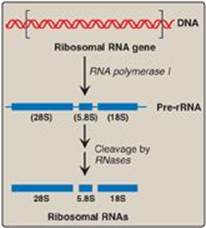
Figure 30.15 Posttranscriptional processing of eukaryotic ribosomal RNA by ribonucleases (RNases). S = Svedberg unit.
V. POSTTRANSCRIPTIONAL MODIFICATION OF RNA
A primary transcript is the initial, linear, RNA copy of a transcription unit (the segment of DNA between specific initiation and termination sequences). The primary transcripts of both prokaryotic and eukaryotic tRNA and rRNA are posttranscriptionally modified by cleavage of the original transcripts by ribonucleases. tRNAs are then further modified to help give each species its unique identity. In contrast, prokaryotic mRNA is generally identical to its primary transcript, whereas eukaryotic mRNA is extensively modified both co- and posttranscriptionally.
A. Ribosomal RNA
rRNAs of both prokaryotic and eukaryotic cells are generated from long precursor molecules called pre-rRNAs. The 23S, 16S, and 5S rRNA of prokaryotes are produced from a single pre-rRNA molecule, as are the 28S, 18S, and 5.8S rRNA of eukaryotes (Figure 30.15). [Note: Eukaryotic 5S rRNA is synthesized by RNA pol III and modified separately.] The pre-rRNAs are cleaved by ribonucleases to yield intermediate-sized pieces of rRNA, which are further processed (trimmed by exonucleases and modified at some bases and riboses) to produce the required RNA species. [Note: In eukaryotes, rRNA genes are found in long, tandem arrays. rRNA synthesis and processing occur in the nucleolus, with base and sugar modifications facilitated by snoRNA. Some of the proteins destined to become components of the ribosome associate with pre-rRNA prior to and during its modification.]
B. Transfer RNA
Both eukaryotic and prokaryotic tRNAs are also made from longer precursor molecules that must be modified (Figure 30.16). Sequences at both ends of the molecule are removed, and, if present, an intron is removed from the anticodon loop by nucleases. Other posttranscriptional modifications include addition of a –CCA sequence by nucleotidyltransferase to the 3ʹ-terminal end of tRNA, and modification of bases at specific positions to produce the “unusual bases” characteristic of tRNA (see p. 292).
C. Eukaryotic mRNA
The collection of all the primary transcripts synthesized in the nucleus by RNA pol II is known as heterogeneous nuclear RNA (hnRNA). The pre-mRNA components of hnRNA undergo extensive co- and posttranscriptional modification in the nucleus. These modifications usually include the following.
1. 5ʹ “Capping”: This is the first of the processing reactions for pre-mRNA (Figure 30.17). The cap is a 7-methylguanosine attached to the 5ʹ-terminal end of the mRNA through an unusual 5ʹ→5ʹ triphosphate linkage that is resistant to most nucleases. Creation of the cap requires removal of the g phosphoryl group from the 5ʹ-triphosphate of the pre-mRNA, followed by addition of guanosine monophosphate (GMP) (from GTP) by the nuclear enzyme guanylyltransferase. Methylation of this terminal guanine occurs in the cytosol and is catalyzed by guanine-7-methyltransferase. S-adenosylmethionine is the source of the methyl group (see p. 263). Additional methylation steps may occur. The addition of this 7-methylguanosine cap helps stabilize the mRNA and permits efficient initiation of translation (see p. 439).
Figure 30.16 A. Primary transfer RNA (tRNA) transcript. B. Functional tRNA after posttranscriptional modification. Modified bases include D (dihydrouracil); Ψ (pseudouracil); and m, which means that the base has been methylated.
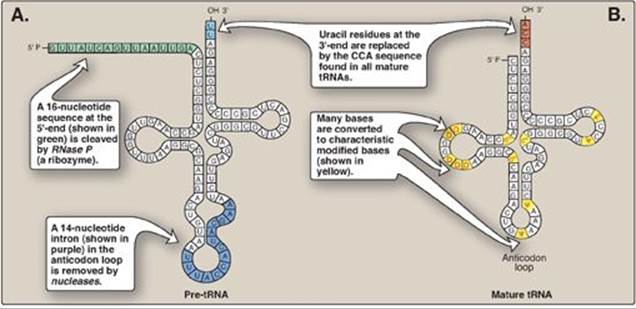
Figure 30.17 Posttranscriptional modification of messenger RNA (mRNA) showing the 7-methylguanosine cap and poly-A tail.
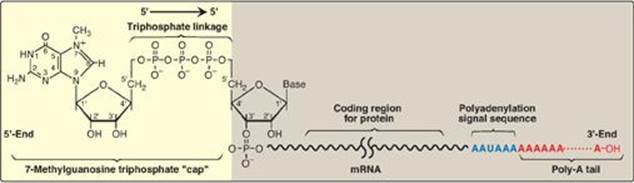
2. Addition of a poly-A tail: Most eukaryotic mRNA (with several notable exceptions, including those coding for the histones) have a chain of 40–250 adenine nucleotides attached to the 3ʹ-end (see Figure 30.17). This poly-A tail is not transcribed from the DNA, but rather is added after transcription by the nuclear enzyme, polyadenylate polymerase, using ATP as the substrate. The pre-mRNA is cleaved downstream of a consensus sequence, called the polyadenylation signal sequence (AAUAAA), found near the 3ʹ-end of the RNA, and the poly-A tail is added to the new 3ʹ-end. These tails help stabilize the mRNA, facilitate its exit from the nucleus, and aid in translation. After the mRNA enters the cytosol, the poly-A tail is gradually shortened.
3. Removal of introns: Maturation of eukaryotic mRNA usually involves removal from the primary transcript of RNA sequences (introns, or intervening sequences) that do not code for protein. The remaining coding (expressed) sequences, the exons, are joined together to form the mature mRNA. The process of removing introns and joining exons is called splicing. The molecular complex that accomplishes these tasks is known as the spliceosome. A few eukaryotic primary transcripts contain no introns (for example, those from histone genes). Others contain a few introns, whereas some, such as the primary transcripts for the a chains of collagen, contain more than 50 intervening sequences that must be removed before mature mRNA is ready for translation.
a. Role of small nuclear RNAs: In association with multiple proteins, uracil-rich snRNAs form small nuclear ribonucleoprotein particles (snRNPs, or “snurps,” designated as U1, U2, U4, U5, and U6) that mediate splicing. They facilitate the removal of introns by forming base pairs with the consensus sequences at each end of the intron (Figure 30.18). [Note: In systemic lupus erythematosus, an autoimmune disease, patients produce antibodies against their own nuclear proteins such as snRNPs.]
b. Mechanism of splicing: The binding of snRNPs brings the sequences of the neighboring exons into the correct alignment for splicing, allowing two transesterification reactions to occur. The 2ʹ-OH group of an adenine nucleotide (known as the branch site A) in the intron attacks the phosphate at the 5ʹ-end of the intron (splice donor site), forming an unusual 2ʹ→5ʹ phosphodiester bond and creating a “lariat” structure (see Figure 30.18). The newly freed 3ʹ-OH of exon 1 attacks the 5ʹ-phosphate at the splice acceptor site, forming a phosphodiester bond that joins exons 1 and 2. The excised intron is released as a lariat, which is typically degraded. [Note: The GU and AG sequences at the beginning and end, respectively, of introns are invariant.] After introns have been removed and exons joined, the mature mRNA molecules leave the nucleus and pass into the cytosol through pores in the nuclear membrane. [Note: The introns in tRNA (see Figure 30.16) are removed by a different mechanism.]
c. Effect of splice site mutations: Mutations at splice sites can lead to improper splicing and the production of aberrant proteins. It is estimated that over 15% of all genetic diseases are a result of mutations that affect RNA splicing. For example, mutations that cause the incorrect splicing of β-globin mRNA are responsible for some cases of β-thalassemia, a disease in which the production of the β-globin protein is defective (see p. 38). Splice site mutations can result in exons being skipped (removed) or introns retained. They can also activate cryptic splice sites, which are sites that contain the 5 or 3 consensus sequence but aren’t normally used.
4. Alternative splicing of mRNA molecules: The pre-mRNA molecules from over 50% of human genes can be spliced in alternative ways in different tissues. This produces multiple variations of the mRNA and, therefore, of its protein product (Figure 30.19), and thus is a mechanism for producing a large, diverse set of proteins from a limited set of genes. For example, in eukaryotic cells, the mRNA for tropomyosin, an actin filament–binding protein of the cytoskeleton (and of the contractile apparatus in muscle cells), undergoes extensive tissue-specific alternative splicing with production of multiple isoforms of the tropomyosin protein.
Figure 30.18 Splicing. snRNP = small nuclear ribonucleoprotein particle; mRNA = messenger RNA. [Note: U1 binds the 5ʹ donor site, U2 binds the branch A, and addition of U4-U6 completes the complex.]
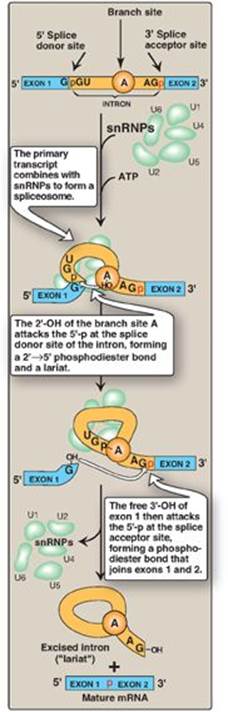
Figure 30.19 Alternative splicing patterns in eukaryotic messenger RNA.
VI. CHAPTER SUMMARY
There are three major types of RNA that participate in the process of protein synthesis: ribosomal RNA (rRNA), transfer RNA (tRNA), and messenger RNA (mRNA) (Figure 30.20). They are unbranched polymers of nucleotides but differ from DNA by containing ribose instead of deoxyribose and uracil instead of thymine. rRNA is a component of the ribosomes. tRNA serves as an “adaptor” molecule that carries a specific amino acid to the site of protein synthesis. mRNA carries genetic information from DNA for use in protein synthesis. The process of RNA synthesis is called transcription, and the substrates are ribonucleoside triphosphates. The enzyme that synthesizes RNA is RNA polymerase (RNA pol). In prokaryotic cells, the core enzyme has five subunits (2α, 1β, 1βʹ, and 1Ω) and possesses 5ʹ→3ʹ polymerase activity that elongates the growing RNA strand. This enzyme requires an additional subunit, sigma (s) factor, that recognizes the nucleotide sequence (promoter region) at the beginning of a length of DNA that is to be transcribed. This region contains consensus sequences that are highly conserved and include the TATA (Pribnow) box and the –35 sequence. Another protein—rho (r) factor—is required for termination of transcription of some genes. There are three distinct classes of RNA pol in the nucleus of eukaryotic cells. RNA pol I synthesizes the precursor of rRNAs in the nucleolus. In the nucleoplasm, RNA pol II synthesizes the precursors for mRNA and some noncoding RNAs, and RNA pol III produces the precursors of tRNA. In both prokaryotes and eukaryotes, RNA pol does not require a primer and has no 3ʹ→5ʹ exonuclease (proofreading) activity. Core promoters for genes transcribed by RNA pol II contain cis-acting consensus sequences, such as the TATA-like Hogness box, that serve as binding sites for trans-acting general transcription factors. Upstream of these are proximal regulatory elements, such as the CAAT and GC boxes, and distal regulatory elements such as enhancers. Transcriptional activators (specific transcription factors) bind these elements and regulate the frequency of transcription initiation, the response to signals such as hormones, and which genes are expressed at a given point in time. Eukaryotic transcription requires that the chromatin be accessible. A primary transcript is a linear copy of a transcription unit, the segment of DNA between specific initiation and termination sequences. The primary transcripts of both prokaryotic and eukaryotic tRNA and rRNA are posttranscriptionally modified by cleavage of the original transcripts by ribonucleases. rRNAs of both prokaryotic and eukaryotic cells are synthesized from long precursor molecules called pre-rRNA. These precursors are cleaved and trimmed by ribonucleases, producing the three largest rRNA, and bases and sugars are modified. Eukaryotic 5S rRNA is synthesized by RNA pol III and is modified separately. Prokaryotic mRNA is generally identical to its primary transcript, whereas eukaryotic mRNA is extensively modified co- and posttranscriptionally. For example, a 7-methylguanosine cap is attached to the 5ʹ-terminal end of the mRNA through a 5ʹ→5ʹ linkage. A long poly-A tail, not transcribed from the DNA, is attached to the 3ʹ-end of most mRNAs. Most eukaryotic mRNAs also contain intervening sequences (introns) that must be removed to make the mRNA functional. Their removal, as well as the joining of expressed sequences (exons), requires a spliceosome composed of small, nuclear ribonucleoprotein particles (snurps) that mediate the process of splicing. Eukaryotic mRNA is monocistronic, containing information from just one gene. Prokaryotic and eukaryotic tRNAs are also made from longer precursor molecules. If present, an intron is removed by nucleases, and both ends of the molecule are trimmed by ribonucleases. A 3ʹ-CCA sequence is added, and bases at specific positions are modified, producing “unusual” bases.
Figure 30.20 Key concept map for RNA structure and synthesis. rRNA = ribosomal RNA; tRNA = transfer RNA; mRNA = messenger RNA.
Study Questions
Choose the ONE correct answer.
30.1 An 8-month-old male with severe anemia is found to have β-thalassemia. Genetic analysis shows that one of his β-globin genes has a mutation that creates a new splice acceptor site 19 nucleotides upstream of the normal splice acceptor site of the first intron. Which of the following best describes the new messenger RNA molecule that can be produced from this mutant gene?
A. Exon 1 will be too short.
B. Exon 1 will be too long.
C. Exon 2 will be too short.
D. Exon 2 will be too long.
E. Exon 2 will be missing.
Correct answer = D. Because the mutation creates an additional splice acceptor site (the 3ʹ-end) upstream of the normal acceptor site of intron 1, the 19 nucleotides that are usually found at the 3ʹ-end of the excised intron 1 lariat can remain behind as part of exon 2. Exon 2 can, therefore, have these extra 19 nucleotides at its 5ʹ-end. The presence of these extra nucleotides in the coding region of the mutant messenger RNA (mRNA) molecule will prevent the ribosome from translating the message into a normal β-globin protein molecule. Those mRNAs for which the normal splice site is used to remove the first intron will be normal, and their translation will produce normal β-globin protein.
30.2 A 4-year-old child who easily tires and has trouble walking is diagnosed with Duchenne muscular dystrophy, an X-linked recessive disorder. Genetic analysis shows that the patient’s gene for the muscle protein dystrophin contains a mutation in its promoter region. Of the choices listed, which would be the most likely effect of this mutation?
A. Initiation of dystrophin transcription will be defective.
B. Termination of dystrophin transcription will be defective.
C. Capping of dystrophin messenger RNA will be defective.
D. Splicing of dystrophin messenger RNA will be defective.
E. Tailing of dystrophin messenger RNA will be defective.
Correct answer = A. Mutations in the promoter typically prevent formation of the RNA polymerase II transcription complex, resulting in a decrease in the initiation of messenger RNA (mRNA) synthesis. A deficiency of dystrophin mRNA will result in a deficiency in the production of the dystrophin protein. Capping, splicing, and tailing defects are not a consequence of promoter mutations. They can, however, result in mRNA with decreased stability (capping and tailing defects), or a mRNA in which too many or too few introns have been removed (splicing defects).
30.3 A mutation to this sequence in eukaryotic messenger RNA (RNA) will affect the process by which the 3ʹ-end poly-A tail is added to the mRNA.
A. AAUAAA
B. CAAT
C. CCA
D. GU… A … AG
E. TATAAA
Correct answer = A. An endonuclease cleaves messenger RNA just downstream of this polyadenylation signal, creating a new 3ʹ-end to which the poly A polymerase adds the poly-A tail using ATP as the substrate in a template-independent process. CAAT and TATAAA are sequences found in promoters for RNA polymerase II. CCA is added to the 3ʹ-end of transfer RNA by nucleotidyltransferase. GU…A…AG denotes an intron.
30.4. This protein factor identifies the promoter of protein-coding genes in eukaryotes.
A. Pribnow box
B. Rho
C. Sigma
D. TFIID
E. U1
Correct answer = D. The general transcription factor, TFIID, recognizes and binds core promoter elements such as the TATA-like box in eukaryotic protein-coding genes. These genes are transcribed by RNA polymerase II. The Pribnow box is a cis-acting element in prokaryotic promoters. Rho is involved in the termination of prokaryotic transcription. Sigma is the subunit of prokaryotic RNA polymerase that recognizes and binds the prokaryotic promoter. U1 is a ribonucleoprotein involved in splicing of eukaryotic pre-messenger RNA.
30.5 What is the sequence (conventionally written) of the RNA product of the DNA template sequence, GATCTAC?
Correct answer = 5ʹ-GUAGAUC-3ʹ. The RNA product has a sequence that is complementary to the template strand, with U replacing T.