MCAT Organic Chemistry Review: For MCAT 2015 (Graduate School Test Preparation) - P.J. Alaimo, Ph.D. 2015
Biologically Important Molecules
INTRODUCTION
As you begin reading and working through this chapter of the text, you will notice that it is a little different than the other chapters. Up to now, this book has presented you with lots of information, then offered you practice questions and passages to help you test yourself. But this book’s real purpose is not to just stuff you with detail—it is to make you think. Thus, this chapter is written in a style intended to do just that.
This chapter offers you grillage; that is, it puts you “on the grill” by asking you questions on the material you’re reading and studying. In other words, the approach is Socratic. The grillage takes the form of questions between paragraphs, but also rears its head as queries that interrupt the flow of text. Some of the questions test factual knowledge that has already been presented. Others ask you to speculate, based on new information. Others force you to integrate factual knowledge and speculation. The idea is to wake you up and remind you that you’re not supposed to be memorizing, but rather thinking about the information flowing past your eyes, speculating about it, integrating it with what you know, what you’d like to know, and what you’d like to do with all that knowledge (help sick people).
It is crucial that you take advantage of the grillage. How? When the book asks you a question, you’ll usually find the answer in a footnote on the same page. DON’T READ THE FOOTNOTE UNTIL YOU’VE ANSWERED THE QUESTION! Some of the answers are as simple as “C” or “No,” and others are complex conceptual explanations. In any case, take the time to formulate a thorough answer before you go to the footnote. If you think you’re too rushed to “waste” time doing this, we’ve got news for you: You are studying the wrong way. The real waste of time is doing nothing but memorizing details. The profitable time is spent pondering concepts, as you’ll do on the day of the MCAT. Though you shouldn’t read the footnotes too soon, do be sure to read them, as sometimes they contain important information or vocabulary not given in the main body of the text.
7.1 AMINO ACIDS
Proteins are biological macromolecules that act as enzymes, hormones, receptors, antibodies, and support structures inside and outside cells. Proteins are composed of twenty different amino acids linked together in polymers. The composition and sequence of amino acids in the polypeptide chain is what makes each protein unique and enables it to fulfill its special role in the cell. In this section of Chapter 7, we will start with amino acids, the building blocks of proteins, and work our way up to three-dimensional protein structure and function.
Amino Acid Structure and Nomenclature
Understanding the structure of amino acids is key to understanding both their chemistry and the chemistry of proteins. The generic formula for all twenty amino acids is shown below.
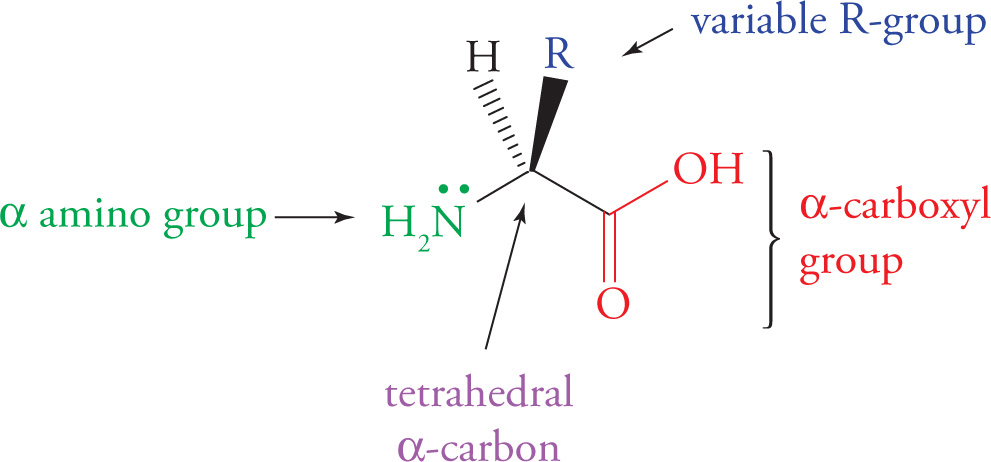
Generic Amino Acid Structure
All twenty amino acids share the same nitrogen-carbon-carbon backbone. The unique feature of each amino acid is its side chain (variable R-group), which gives it the physical and chemical properties that distinguish it from the other nineteen. Note that the α-carbon of each of the twenty amino acids is a stereocenter (has four different groups), except in the case of glycine, whose α-carbon is bonded to two hydrogen atoms. This means that all of the amino acids are chiral except for glycine.
L- and D-Amino Acids
Chemists often draw chiral molecules in their Fischer projection to illustrate stereochemistry. Let’s review how Fischer projections denote the absolute stereochemistry of molecules. The conformation of a molecule that is shown in a Fischer projection happens to be the least stable, fully eclipsed form of the molecule. In Fischer projections the most oxidized carbon is at the top, and the structure is extended vertically until the final carbon atom is reached. This leaves the substituents on each carbon atom to occupy the horizontal positions of each carbon atom in the chain. This is illustrated below.

In the Fischer projection, it’s understood that all horizontal lines are projecting from the plane of the page toward the viewer, and all vertical lines are projecting into the plane of the page, away from the viewer.
All animal amino acids are of the L-configuration, with the amino group drawn on the Left in Fischer notation. Some D-amino acids, with the amino group on the right, occur in a few specialized structures, such as bacterial cell walls. The L and D classification system can be a source of great confusion. For the MCAT, it is most important to remember that all animal amino acids have the L configuration and that all naturally occurring carbohydrates have the D configuration. (Carbohydrates are discussed in a later section of this chapter.) For completeness, though, we’ll take the time to discuss the meaning of D and L now.
Assigning the Configuration to a Chiral Center
L- and D-amino acids and L- and D-carbohydrates are enantiomeric stereoisomers. The simplest (smallest) carbohydrate has only three carbons and only one chiral center. It is called glyceraldehyde. Since it has one chiral center, this molecule can exist in one of two enantiomeric forms, (+)-glyceraldehyde and (−)-glyceraldehyde. In reactions occurring in living organisms, CHOH groups are added to carbon #1 of glyceraldehyde to form larger carbohydrate molecules with more than one chiral center. In this synthetic process the configuration at the original glyceraldehyde chiral carbon (#2) is not changed. So, if you start with (−)-glyceraldehyde and build a longer carbohydrate chain, that carbohydrate chain will have a penultimate (second-to-last) carbon atom with the same configuration as (−)-glyceraldehyde. So why not just call the new, larger carbohydrate “(−)”? You cannot refer to the new carbohydrate as (−) because you have added several new chiral centers, and now if you put the new molecule in solution and measure its optical rotation with a polarimeter, the optical activity may in fact be (+). What is needed is a way to name a carbohydrate that would specify that it had been built up from (−)- or (+)-glyceraldehyde without worrying about its actual optical activity.

The solution is to nickname (−)-glyceraldehyde as “L-glyceraldehyde,” and to likewise refer to (+)-glyceraldehyde as “D-glyceraldehyde.” Now we can refer to all carbohydrates built up from (−)-glyceraldehyde as “L” carbohydrates, without specifying whether they rotate plane-polarized light to the left (−) or to the right (+). All we have to do is look at the last chiral carbon in the chain and decide whether it looks like C2 from L- or D-glyceraldehyde.
Once again, the important thing to remember is that all animal amino acids are derived from L-glyceraldehyde (because they share the same basic structure at the penultimate carbon). Hence, they all have the L configuration. Animal carbohydrates are chemically derived from D-glyceraldehyde, and are thus all D.
As we discussed in Chapter 3, there is another classification system, in which chiral centers are denoted either R or S. This system describes the absolute configuration of the chiral center; it refers to the actual three-dimensional arrangement of groups, as in a model or drawing; it says nothing about what the molecule will do to plane-polarized light.
In summary, you can see that three classification systems are used to organize amino acids and carbohydrates:
1. (+) and (−) describe optical activity, and mean the same thing as d and l, respectively;
2. R and S describe actual structure or absolute configuration; and
3. D and L tell us the basic precursor of a molecule (D- or L-glyceraldehyde).
You can also see that the three different classification systems don’t describe each other in any way. A molecule that has the R configuration of its only stereocenter might rotate plane-polarized light either clockwise or counterclockwise, and hence be either (+) or (−). And a molecule that is experimentally determined to be (+) might be either D or L. However, two of the three classification systems go together for certain molecules. All D-sugars have the R configuration at the penultimate carbon atom because they are all derived from D-glyceraldehyde. Similarly, all L-sugars have the S configuration at the penultimate carbon atom. This is true only because carbohydrates are named according to the configuration of the last chiral center in the chain (which, remember, is synthetically derived from glyceraldehyde). By the same rationale, all L-amino acids are S, and all D-amino acids are R. (Note that the only exception is for cysteine, because the R group (CH2SH) of this amino acid has a higher priority than the COOH group.)
1) You crash-land on Mars without any food but notice that Mars is loaded with edible-looking plants. Martian life has evolved with all L-carbohydrates. Can you metabolize carbohydrates from Mars?1
Classification of Amino Acids
Each of the twenty amino acids is unique because of its side chain. Each amino acid has a three-letter abbreviation and a one-letter abbreviation, which you do not need to memorize. Though they are all unique, many of them are similar in their chemical properties. It is not necessary to memorize all 20 side chains, but it is important to understand the chemical properties that characterize them. The important properties of the side chains include their varying shape, charge, ability to hydrogen bond, and ability to act as acids or bases. These side group properties are important in the structure of proteins.
We now consider the 20 amino acids, organizing them into broad categories.
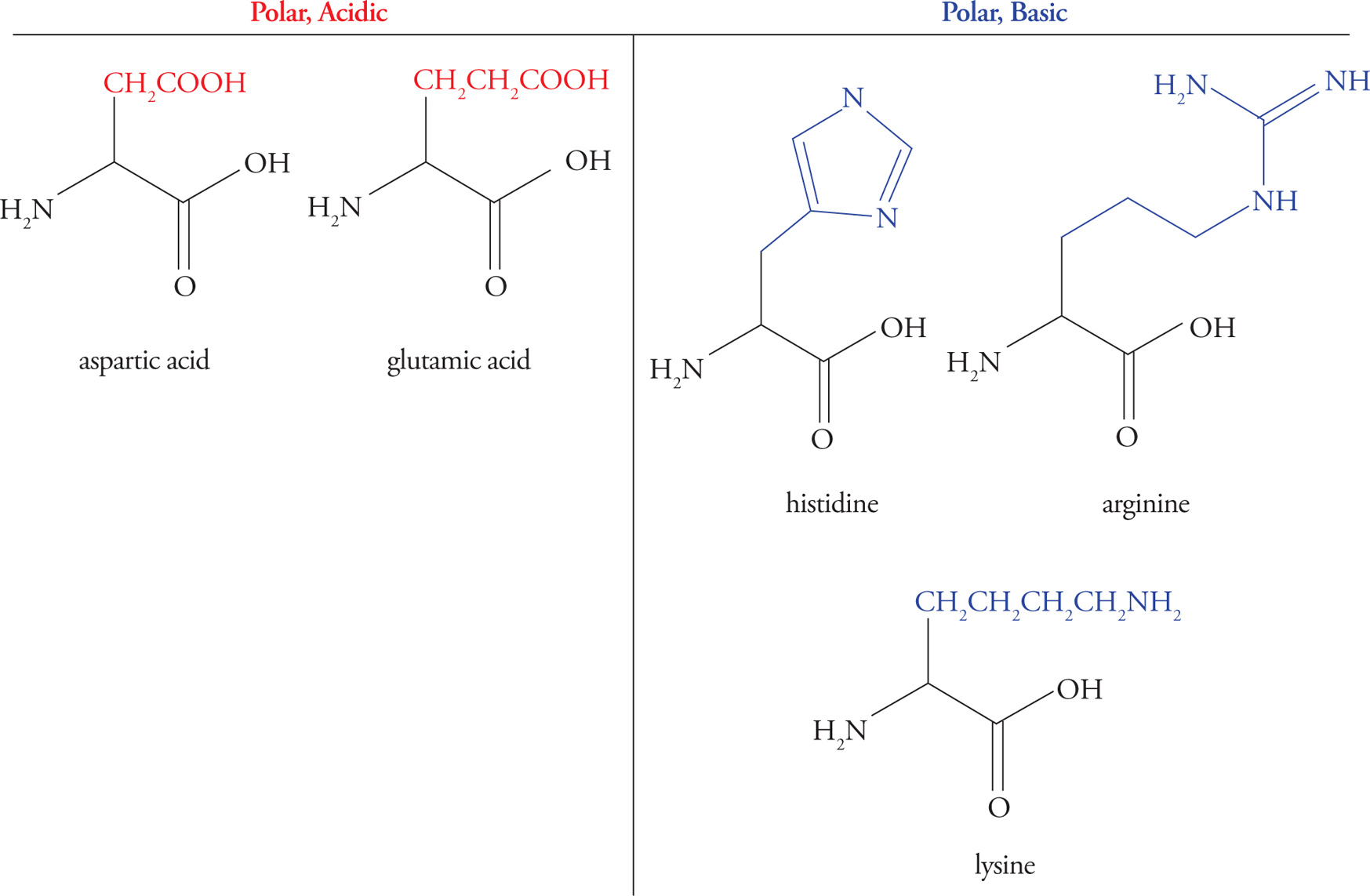
Acidic Amino Acids
Glutamic acid and aspartic acid are the only amino acids with carboxylic acid functional groups (pKa ≈ 4) in their side chains, thereby making the side chains acidic. Thus, there are three functional groups in these amino acids that may act as acids or bases—the two backbone groups and the R-group. You may hear the terms glutamate and aspartate—these simply refer to the anionic (unprotonated) form of the molecule.
Basic Amino Acids
Lysine, arginine, and histidine have basic R-group side chains. The pKas for the side chains in these amino acids are 10 for Lys, 12 for Arg, and 6.5 for His. Histidine is unique in having a side chain with a pKa so close to physiological pH. At pH 7.4 histidine may be either protonated or deprotonated—we put it in the basic category, but it often acts as an acid, too. This makes it a readily available proton acceptor or donor, explaining its prevalence at protein active sites (discussed below). A mnemonic is “His goes both ways.” This contrasts with amino acids containing −COOH or −NH2 side chains, which are always anionic (RCOO−) or cationic (RNH3+) at physiological pH. (By the way, histamine is a small molecule that has to do with allergic responses, itching, inflammation, and other processes. (You’ve heard of antihistamine drugs.) It is not an amino acid; don’t confuse it with histidine.)
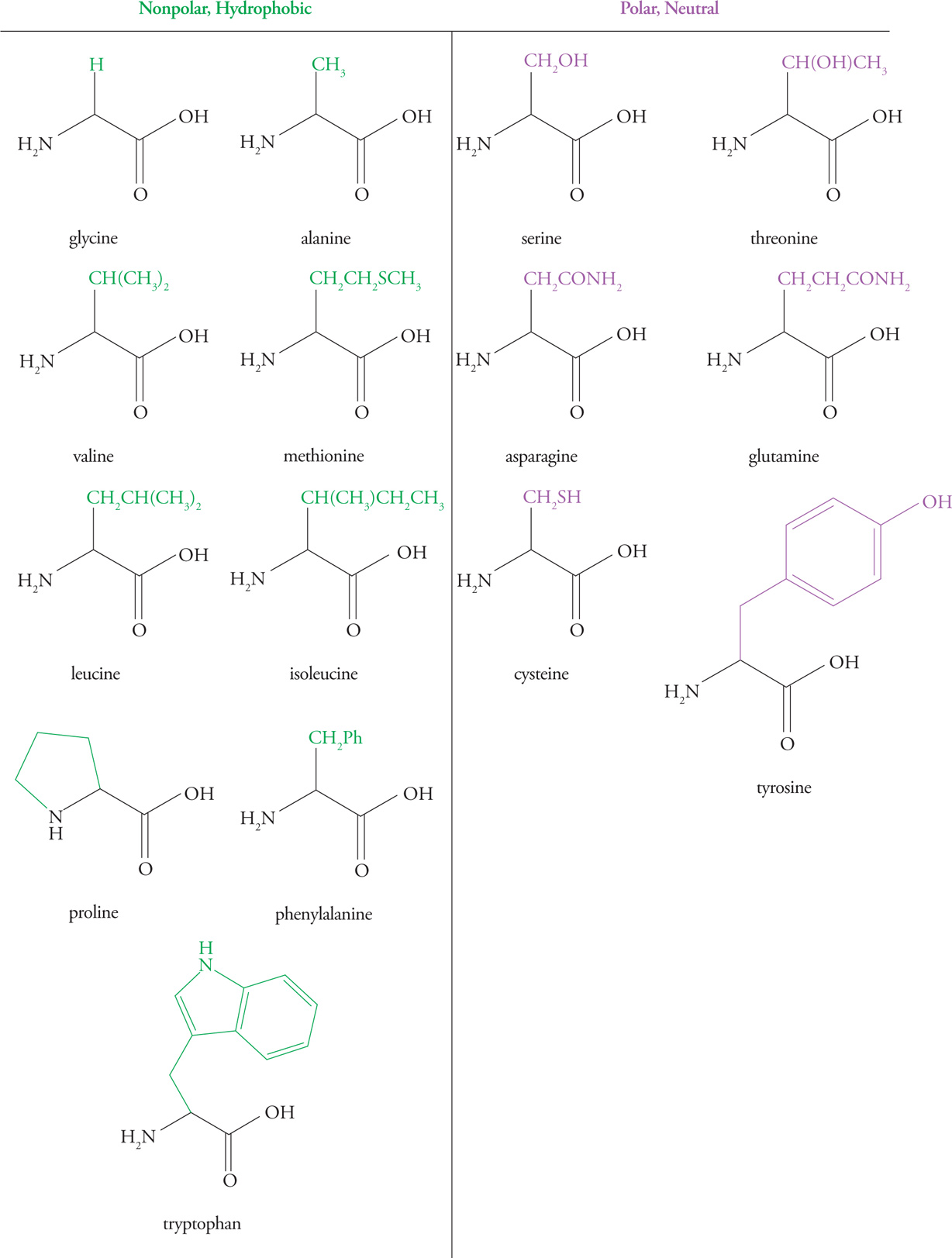
Hydrophobic (Nonpolar) Amino Acids
Hydrophobic amino acids have either aliphatic (alkyl) or aromatic side chains. Amino acids with aliphatic side chains include glycine, alanine, valine, leucine, and isoleucine. Amino acids with aromatic side chains include phenylalanine, tyrosine, and tryptophan. Hydrophobic residues tend to associate with each other rather than with water, and therefore are found on the interior of folded globular proteins, away from water. The larger the hydrophobic group, the greater the hydrophobic force repelling it from water.
Polar Amino Acids
These amino acids are characterized by an R-group that is polar enough to form hydrogen bonds with water but not polar enough to act as an acid or base. This means they are hydrophilic and will interact with water whenever possible.
The hydroxyl groups of serine, threonine, and tyrosine residues are often modified by the attachment of a phosphate group by a regulatory enzyme called a kinase. The result is a change in structure due to the very hydrophilic phosphate group. This modification is an important means of regulating protein activity.
Sulfur-Containing Amino Acids
Amino acids with sulfur-containing side chains include cysteine and methionine. Cysteine, which contains a thiol (also called a sulfhydryl—like an alcohol that has an S atom instead of an O atom), is actually fairly polar, and methionine, which contains a thioether (like an ether that has an S atom instead of an O atom) is fairly nonpolar.
Proline
Proline is unique among the amino acids in that its amino group is bound covalently to a part of the side chain, creating a secondary α-amino group and a distinctive ring structure. This unique feature of proline has important consequences for protein folding (see Section 7.2).
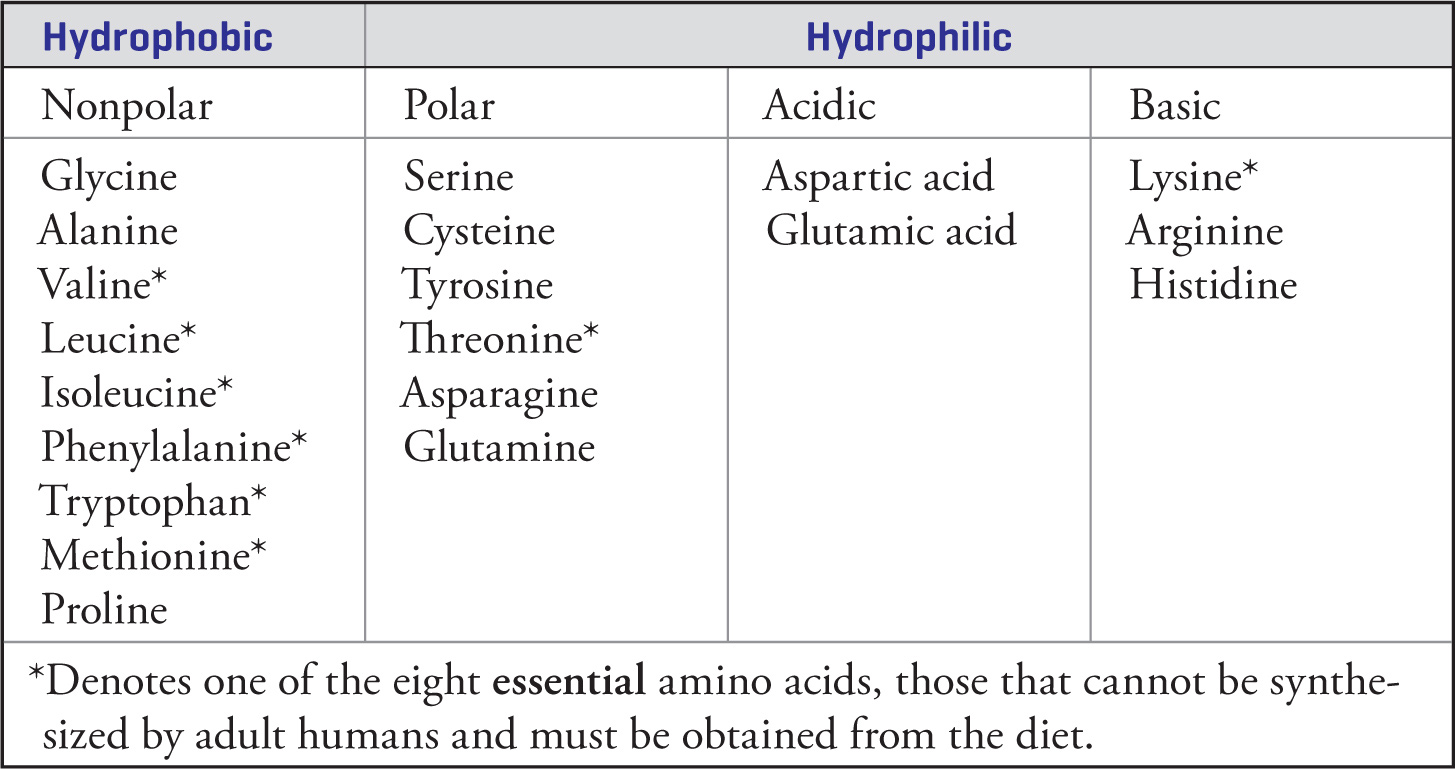
Summary Table of Amino Acids
Synthesis of Amino Acids
Nature has developed complicated mechanisms for the syntheses of the amino acids it uses to build proteins. In the laboratory, synthetic chemists have developed their own set of tools with which to make these essential building blocks available. Two important synthetic methods for the production of amino acids are the Strecker and Gabriel syntheses.
Strecker Synthesis
The Strecker synthesis utilizes ammonium and cyanide salts to transform aldehydes into α-amino acids. While naturally occurring amino acids are stereochemically pure (L-enantiomers), those produced via this process are racemic. Despite this drawback, a variety of both naturally-occurring and non-natural amino acids may be easily synthesized, depending on the substitution of the aldehyde. An example of the Strecker synthesis applied to the production of (D,L)-valine is shown below:
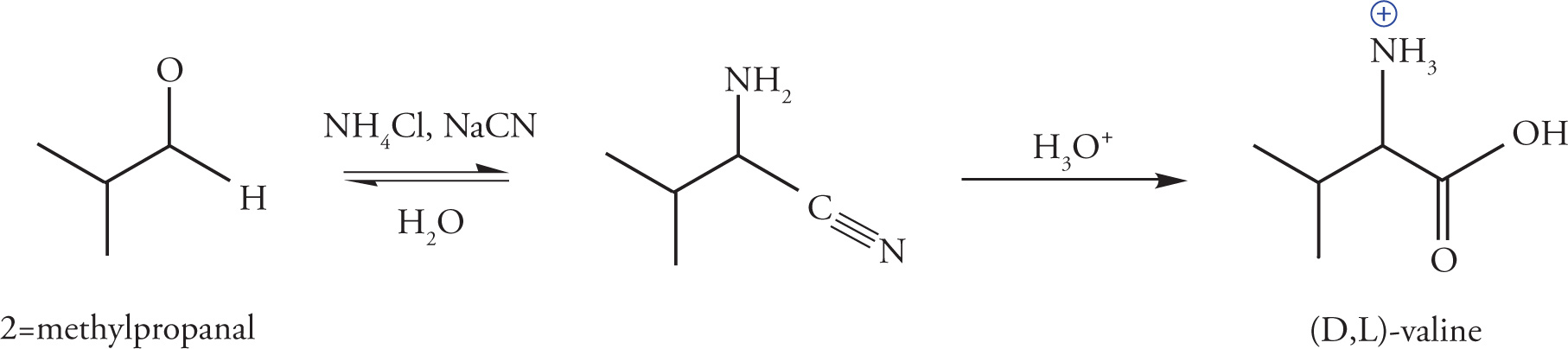
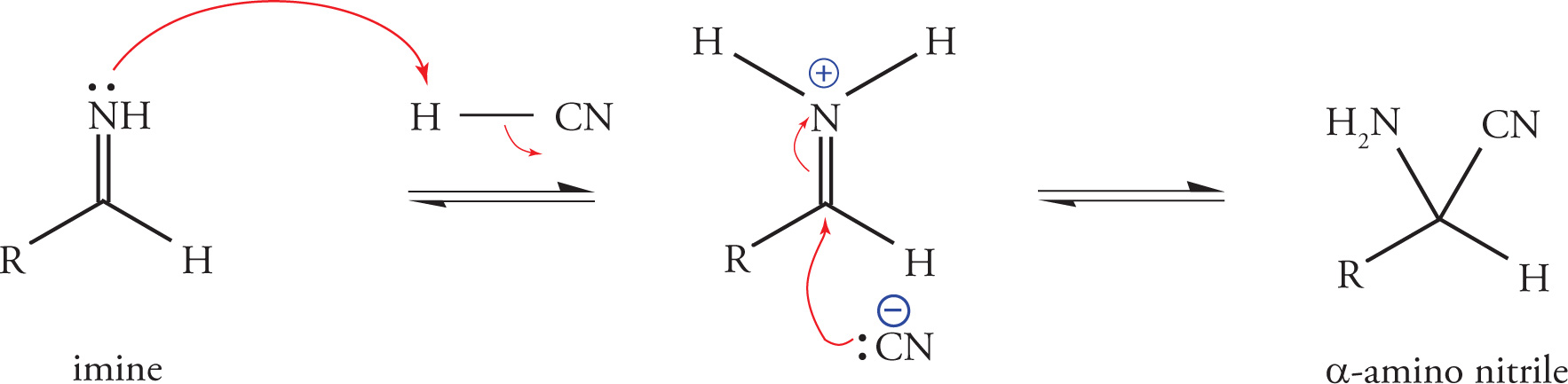
The combination of an ammonium halide and alkali cyanide results in the formation of alkali halide salts and the in situ production of the active species, NH3 and HCN. In the first step of the reaction, the aldehyde reacts with ammonia to yield an imine as described previously in Section 6.1.

When protonated by HCN, the imine becomes more electrophilic, enabling attack by the remaining cyanide ion on the imine-carbon and concomitant formation of an α-amino nitrile. This attack by cyanide on an unsaturated carbon electrophile resembles the mechanism previously described for the formation of cyanohydrins. The difference is that the Strecker synthesis utilizes an imine (rather than a carbonyl) as substrate for the attack.
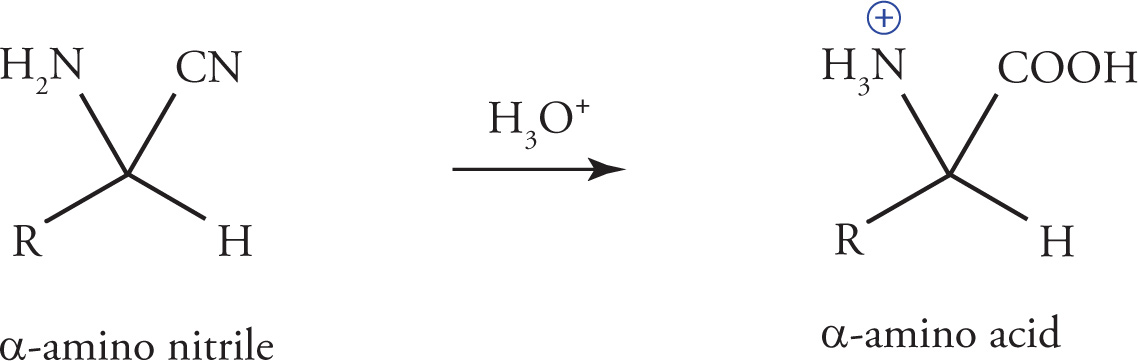
In a subsequent step, acid catalyzed hydrolysis of the α-amino nitrile gives the α-amino acid.
Gabriel-Malonic Ester Synthesis
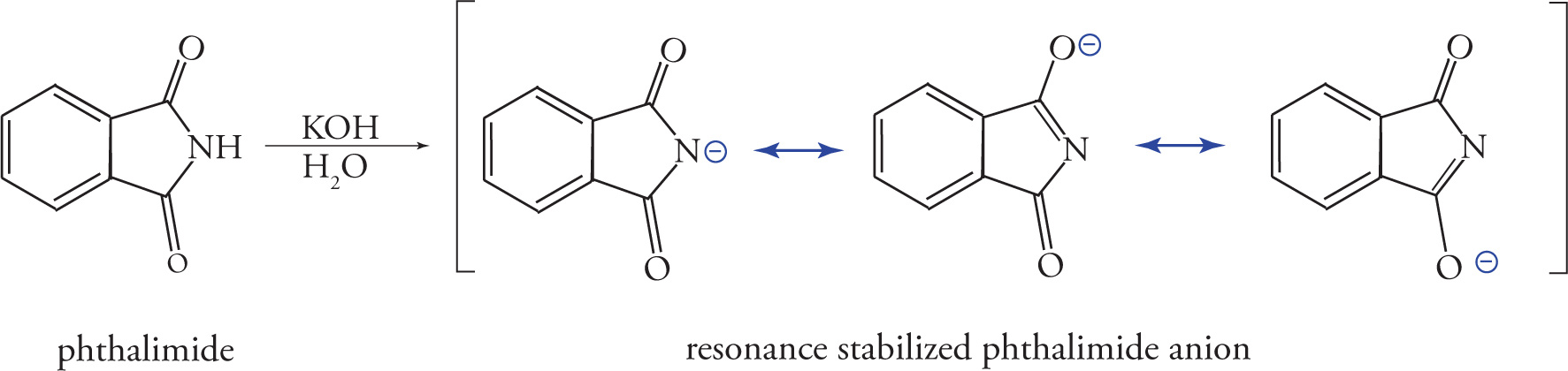
The Gabriel-malonic ester synthesis is another useful method for the production of α-amino acids. Over the course of the reaction, the nitrogen in a molecule of phthalimide is converted into a primary amine. To begin, phthalimide is deprotonated with potassium hydroxide (KOH) to give the resonance-stabilized phthalimide anion, as shown below:
The phthalimide anion is a strong nucleophile, and when treated with α-bromomalonic ester, it displaces bromide from the central carbon, yielding an N-phthalimidomalonic ester.
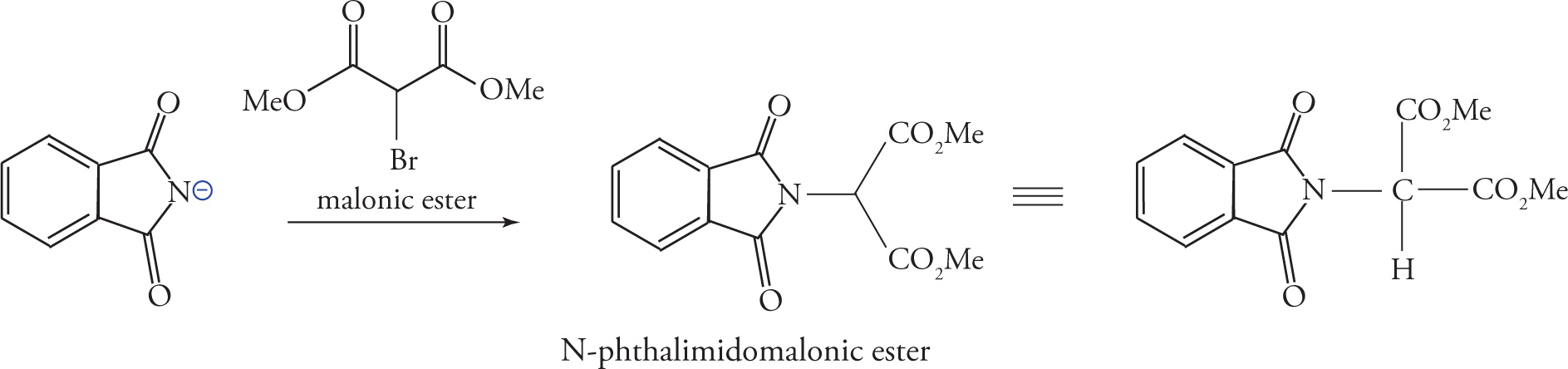
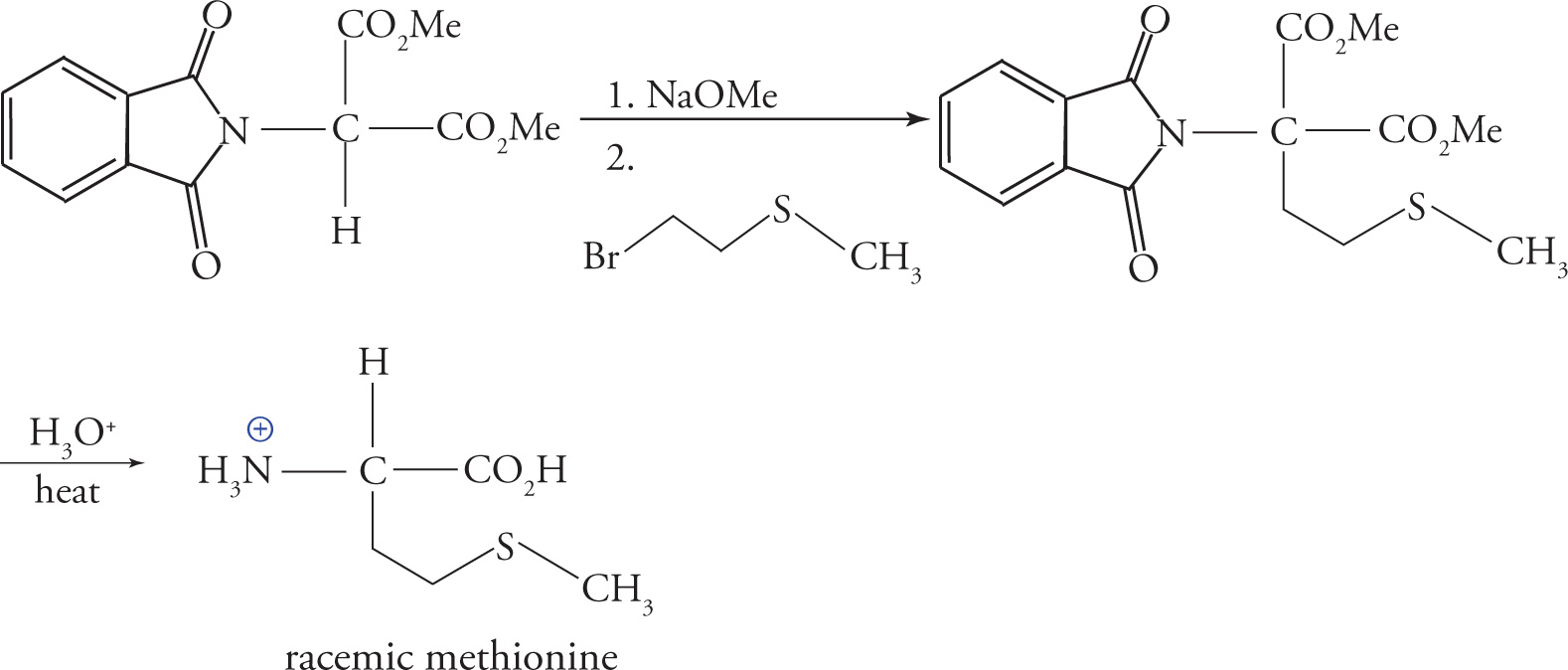
Enolization of the α-carbon with a strong base creates a nucleophilic carbon, which can be functionalized with the desired amino acid side-chain. The example below shows the reaction of the enolate with methyl-(2-bromoethyl)-sulfide to give a precursor of methionine. The phthalimido group and both esters are then subjected to acid hydrolysis, and after heat-induced decarboxylation, the racemic amino acid may be isolated.
Amino Acid Reactivity
Since amino acids are composed of an acidic group (the carboxylic acid) and a basic group (the amine), we must be sure to understand the acid/base chemistry of amino acids. Later, we will review amide bond formation by examining formation of the peptide bond in protein synthesis.
Reviewing the Fundamentals of Acid/Base Chemistry
Before we can discuss amino acids, we must be sure to understand the fundamentals of acid/base chemistry because each amino acid is amphoteric, which means it has both acidic and basic activity. This should make sense since an amino acid contains the acidic carboxylic acid group and the basic amino group.
Remember from general chemistry that acids can be defined as proton (H+) donors, and bases can be defined as proton acceptors. Thus, in the case of the equation below, H2A+ is a proton donor (acid), and A− is a proton acceptor (base); HA may act as either acid or base. The equations below also show how to calculate the equilibrium constant (K) for an acid dissociation reaction. The equilibrium constant for an acid dissociation reaction is given a special name: acid dissociation constant, abbreviated “Ka.” The equilibrium reactions for the first and second proton dissociation reactions are described by the equations for the acid dissociation constants Ka1 and Ka2.

The Acid Dissociation Reaction
2) In the equilibrium between H2A+, HA, and A− above, which statement is true?2
A. HA will act as a base by donating a proton.
B. HA will act as an acid by accepting a proton.
C. HA can act as either an acid or a base, depending on whether it accepts or donates a proton.
D. HA is in chemical equilibrium with H2A+ and A− and in that capacity cannot act as either an acid or a base.
Whether a molecule (or a functional group) is protonated depends on its affinity for protons, and the concentration of protons in solution that are available to it. Let’s discuss both and do a few practice problems.
The concentration of available protons is simply [H+] (moles/liter), but it is usually expressed as pH, defined as −log [H+]. If you’re wondering why pH is used instead of [H+], it has to do with the fact that [H+] values tend to be clumsy numbers, so a logarithmic scale reduces the amount of writing we have to do; we use the negative logarithm simply to avoid writing an extra minus sign. For example, instead of writing “[H+] = 10−3.46,” we can write “pH = 3.46.” The pH inside cells is 7.4. This is often referred to as physiological pH, and is carefully regulated by buffers in the blood because extremes of pH disrupt protein structure.
The affinity of a functional group (such as an amino or carboxyl group) for protons is given by the acid dissociation constant Ka for that functional group, which is simply the equilibrium constant for the dissociation of the acid form (HA) into a proton (H+) plus the conjugate base (A−). The equilibrium constant describes a reaction’s tendency to move right or left as it moves toward equilibrium from some starting point. This affinity can also be expressed as pKa, defined as −log Ka. Carboxyl groups of amino acids generally have a pKa of about 2 (stronger acid), while the ammonium groups generally have a pKa of 9 or 10 (weaker acid).
The mathematical formula that describes the relationship between pH, pKa, and the position of equilibrium in an acid-base reaction is known as the Henderson—Hasselbalch equation:
pH = pKa + log 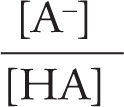 = pKa + log
= pKa + log 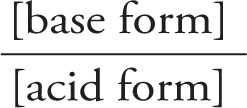
Given the pH and the pKa, we can calculate the ratio of the base and acid forms of a compound at equilibrium. Just remember these rules:
• Low pH means high [H+].
• Lower pKa (same as higher Ka) describes a stronger acid that can donate a proton even when there are already excess protons (high [H+], low pH).
3) The text above states that physiological pH is 7.4. Is this more or less acidic—and are there more or fewer extra protons—than in pure water?3
4) Pure water at 25°C has a balance of 10−7 M H+ and 10−7 M OH− resulting from the spontaneous breakdown of water itself. What pH does pure water have? 4
5) What is the pH of a solution of 0.1 M HCl (assuming the HCl dissociates fully)?5
6) Acetic acid (CH3COOH) has pKa = 4.7. Calculate the equilibrium ratio of [CH3COO−] to [CH3COOH] at pH 4.7.6
7) Which functional group on amino acids has a stronger tendency to donate protons: carboxyl groups (pKa = 2.0) or ammonium groups (pKa = 9)? Which group will donate protons at the lowest pH?7
Application of Fundamental Acid/Base Chemistry to Amino Acids
With that review of acids and bases, we are now prepared to discuss amino acid reactivity. The review is important because all amino acids contain an amino group that acts as a base and a carboxyl group (pKa ≈ 2) that acts as an acid. In its protonated, or acidic form, the amine is called an ammonium group, and has a pKa between 9-10. For example:
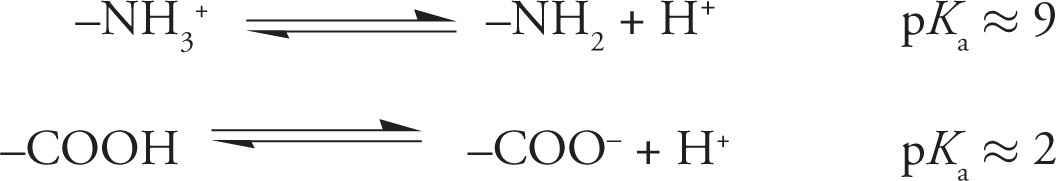
8) Assuming a pKa of 2, will a carboxylate group be protonated or deprotonated at pH 1.0?8
9) Will the amino group be protonated or deprotonated at pH 1.0?9
10) Glycine is the simplest amino acid, with only hydrogen as its R-group. Its only functional groups are the backbone groups discussed above (amino and carboxyl). What will be the net charge on a glycine molecule at pH 12?10
11) At pH 6.0, between the pKas of the ammonium and carboxyl groups, what will be the net charge on a molecule of glycine?11
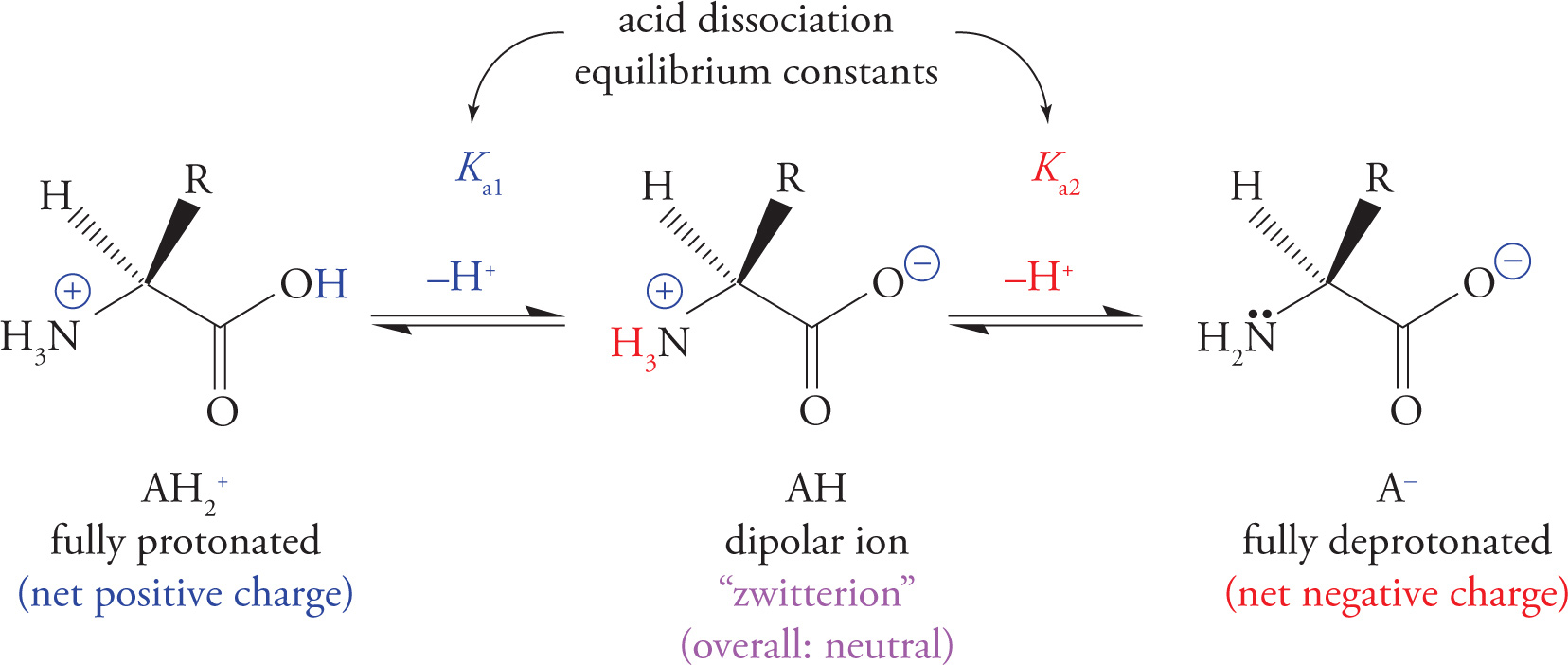
Important Amino Acid Conjugate Acid/Base Pairs
The Isoelectric Point of Amino Acids
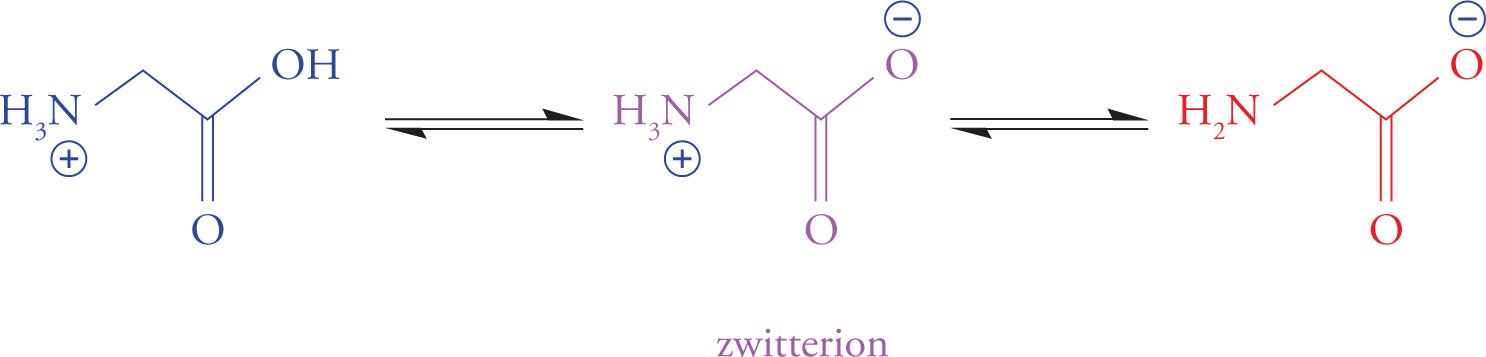
There is a pH for every amino acid at which it has no overall net charge (the positive and negative charges cancel). A molecule with positive and negative charges that balance is referred to as a dipolar ion or zwitterion. The pH at which a molecule is uncharged (zwitterionic) is referred to as its isoelectric point (pI). “Zwitter” is German for “hybrid”, implying that an amino acid at its pI has both (+) and (−) charges.
It is possible to calculate the pI of an amino acid—in other words, to figure out the pH value at which (+) and (−) charges balance (that’s the definition of pI). For a molecule with two functional groups, such as glycine, the calculation is simple: just average the pKas of the two functional groups. The pI of more complex molecules can also be calculated, but the math is complex. For the MCAT, you should know how to calculate the pI of a molecule with two functional groups (with no acidic or basic functional groups in the side chain). Another important thing to know for the MCAT is how to compare the pH of a solution to the pKa of a functional group of an amino acid and determine if a site is mostly protonated or deprotonated. If the pH is higher than the pKa, the site is mostly deprotonated; if the pH is lower than the pKa, the site is mostly protonated. This can be illustrated in the titration curve for glycine:
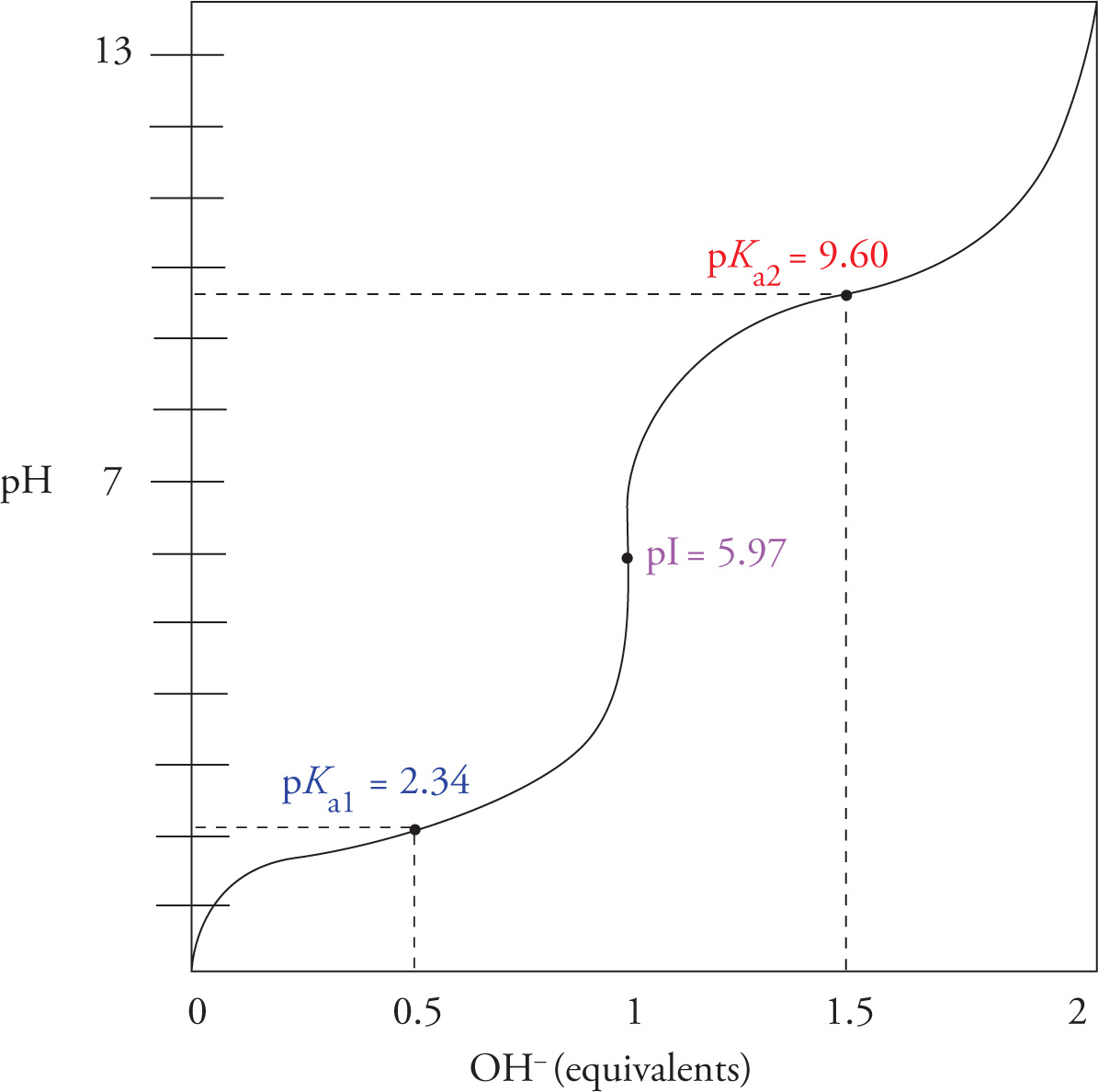
12) What is the pI of glycine?12
Amino Acid Separation—Gel Electrophoresis
Gel electrophoresis is a general separation technique that can be used to separate amino acids based on their charge. In general, when employing this technique, amino acids are loaded onto a gel that is held at a constant pH, then exposed to an electric field. When the pH of the gel is different than the pI of the amino acids, each amino acid will bear an overall charge because pI is specific to the unique structure of the side chain of each amino acid. The amino acids will therefore migrate through the gel based on their charge and the external electric field. The MCAT tends to ask about how specific amino acids will migrate relative to each other in these separation conditions. In order to answer these questions, an understanding of the relationship between pH, pKa, and pI (as discussed previously) is required. See the table below, which summarizes how pH will determine the direction of amino acid migration during an electrophoresis separation:

13) A sample of glycine is loaded on a gel in a pH = 6.0 solution with a (+) electrode at one end and a (−) electrode at the other end. Will the majority of the glycine migrate toward the negative terminal, migrate toward the positive terminal, or not migrate in either direction?13
14) The pKas for the three functional groups in aspartic acid are 9.8 for the amino group, 2.1 for the α−carboxyl, and 3.9 for the side chain carboxyl. What pole (− or +) will aspartic acid migrate toward in an electric field at physiological pH (7.4)?14
15) What pole (− or +) would aspartic acid migrate toward in an electric field in a pH 1.0 solution?15
16) Which of these amino acids is most likely to be found on the interior of a protein at pH 7.0?16
A. Alanine
B. Glutamic acid
C. Phenylalanine
D. Glycine
17) Which of the following amino acids is most likely to be found on the exterior of a protein at pH 7.0?17
A. Leucine
B. Alanine
C. Serine
D. Isoleucine
7.2 PROTEINS
There are two common types of covalent bonds between amino acids in proteins: the peptide bonds that link amino acids together into polypeptide chains and disulfide bridges between cysteine R-groups.
The Peptide Bond
Polypeptides are formed by linking amino acids together in peptide bonds. A peptide bond is formed between the carboxyl group of one amino acid and the α-amino group of another amino acid with the loss of water. This occurs by the same nucleophilic addition-elimination mechanism shown in Section 6.3 for formation of any one of the carboxylic acid derivatives from any other carboxylic acid derivative. Remember that a peptide bond is just an amide bond between two amino acids. The figure below shows the formation of a dipeptide from the amino acids glycine and alanine.
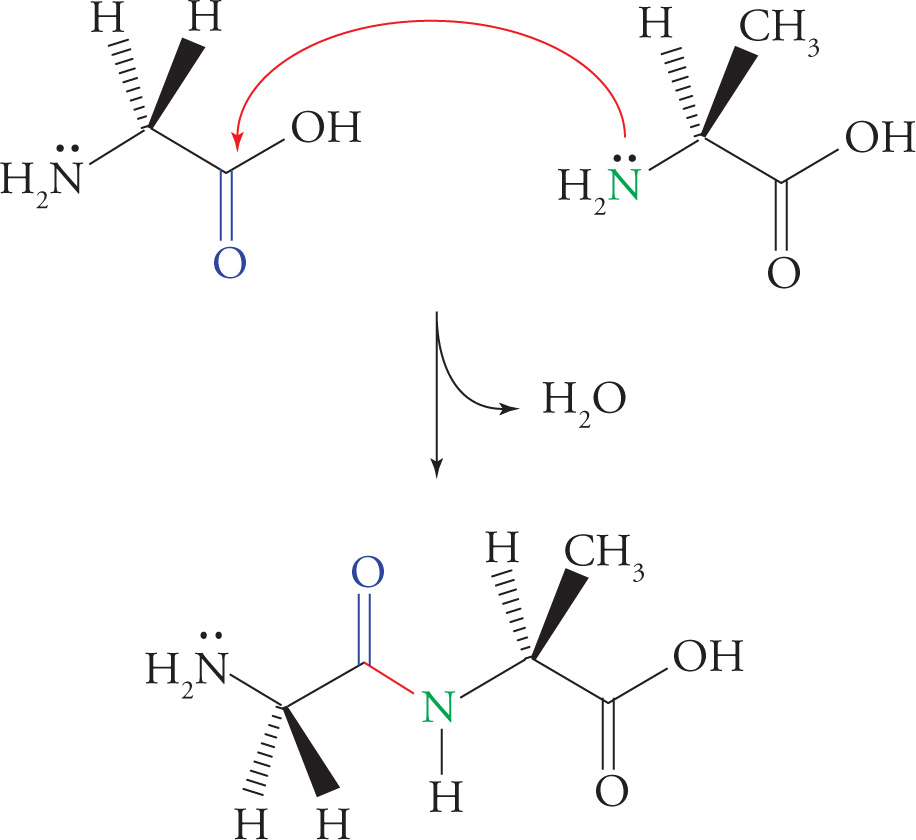
Peptide Bond (Amide Bond) Formation
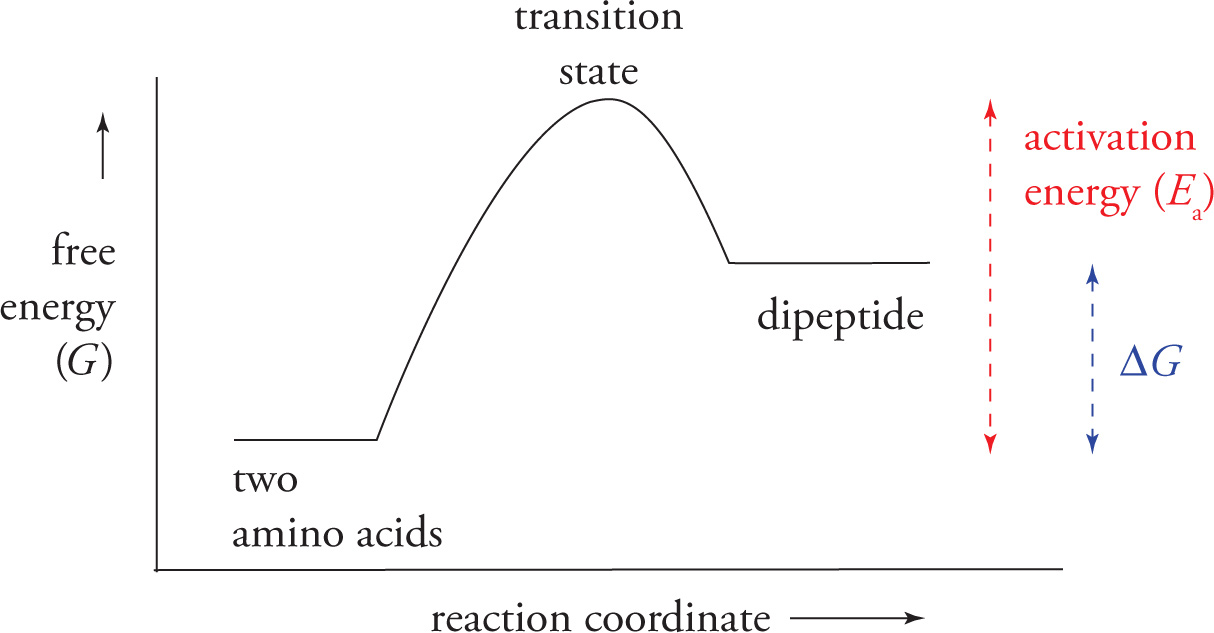
Note: The above diagram showing formation of a peptide bond via a simple condensation reaction is not entirely accurate. As seen in the following graph, the formation of a peptide bond with two amino acids is not thermodynamically favorable and requires energy. This naturally occurring reaction, which takes place during translation in cells, involves enzyme catalysis, is RNA directed, and co-factor mediated.
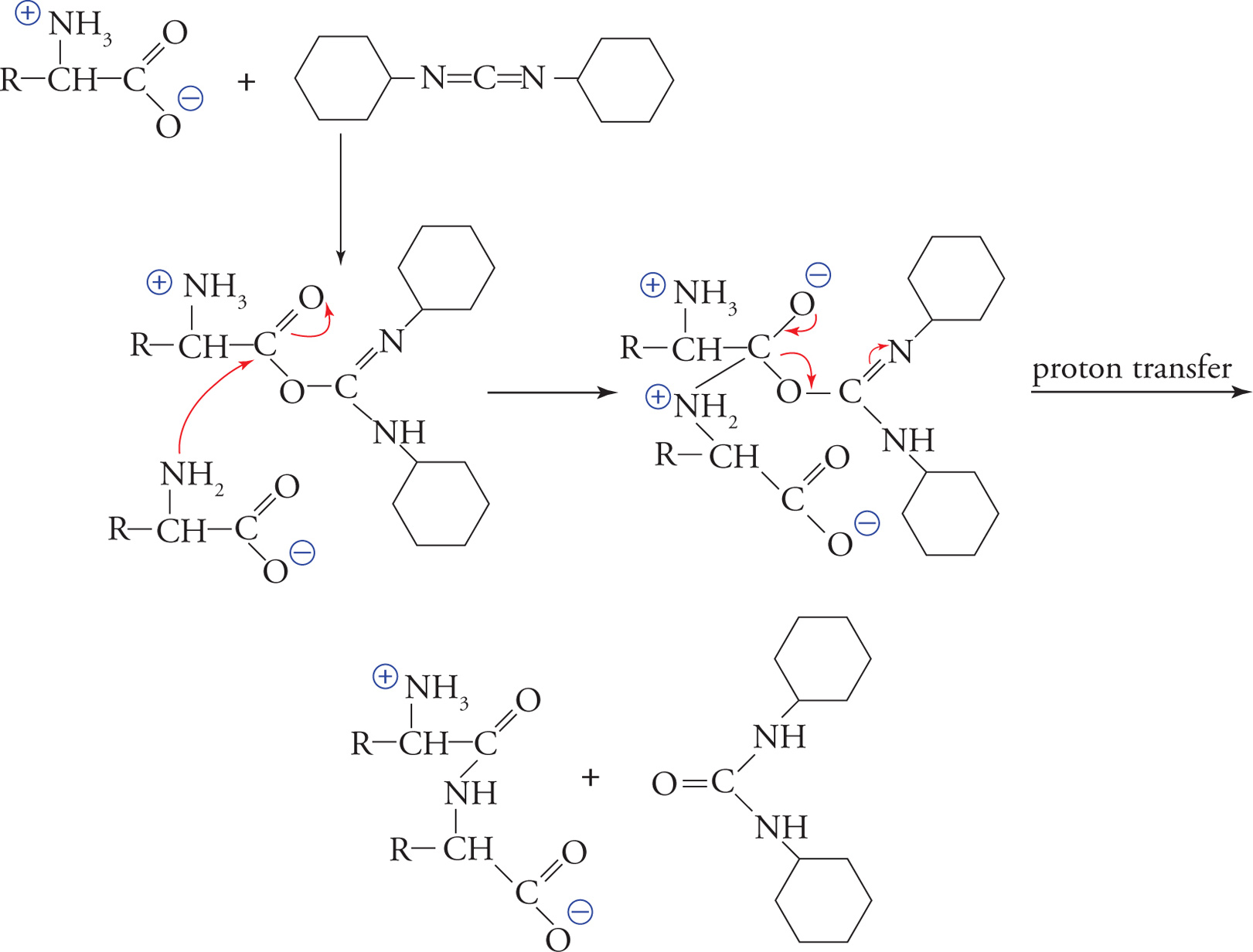
DCC Coupling
In order to synthesize peptides artificially in the laboratory, DCC coupling is used. In the first step of the coupling process, DCC, or dicyclohexyl carbodiimide, converts the OH of the caboxylate group in an amino acid into a good leaving group. In the next step, the amino group of a second amino acid attacks the carbonyl carbon of the “activated” amino acid. Finally, the DCC leaves with the oxygen to which it is bonded. To assure that amino acids are added in a unidirectional manner and in the proper order for the desired peptide, the reaction is run using protecting groups so that only one of the carboxyl groups and one of the amino groups are available to react. See the example reaction that follows.
In a polypeptide chain, the N−C−C−N−C−C pattern formed from the amino acids is known as the backbone of the polypeptide. An individual amino acid is termed a residue when it is part of a polypeptide chain. The amino terminus is the first end made during polypeptide synthesis, and the carboxy terminus is made last. Hence, by convention, the amino-terminal residue is also always written first.
18) In the oligopeptide Phe-Glu-Gly-Ser-Ala, state the number of acid and base functional groups, which residue has a free α-amino group, and which residue has a free α-carboxyl group. (Refer to the beginning of the chapter for structures.)18
19) Thermodynamics states that free energy must decrease for a reaction to proceed spontaneously and that such a reaction will spontaneously move toward equilibrium. The reaction coordinate diagram above shows the free energy changes during peptide bond formation. At equilibrium, which is thermodynamically favored: the dipeptide or the individual amino acids?19
20) In that case, how are peptide bonds formed and maintained inside cells?20
Planarity of the Peptide Bond
The peptide bond is planar and rigid because the resonance delocalization of the nitrogen’s electrons to the carbonyl oxygen gives substantial double bond character to the bond between the carbonyl carbon and the nitrogen, as shown below. Hence there can be no rotation around the peptide bond.
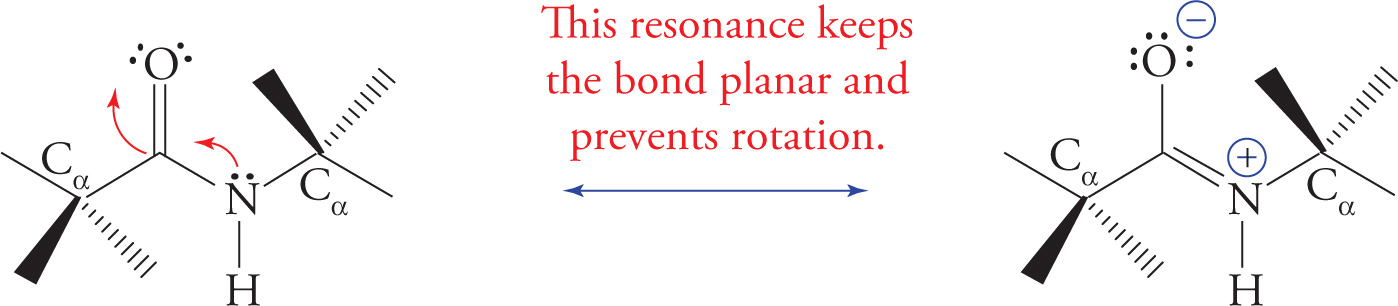
Resonance Structure of the Planar, Rigid Peptide Bond
21) If the peptide bond is rigid and planar, then is the entire polypeptide rigid and incapable of rotation?21
Hydrolysis of the Peptide Bond
Hydrolysis refers to any reaction in which water is inserted in a bond to cleave it. We have already discussed the details of hydrolysis reactions in Chapter 6, which covered the hydrolysis of an ester under both acidic and basic reaction conditions (see Section 6.3). Hydrolysis of the peptide bond (amide bond) to form a free amine and a carboxylic acid is thermodynamically favored (products have lower free energy), but kinetically slow. There are two common means of accelerating the rate of peptide bond hydrolysis (i.e., two common ways to destroy proteins): strong acids and proteolytic enzymes.
Acid hydrolysis is the cleaving of a protein into its constituent amino acids with strong acid and heat. This is a non-specific means of cleaving peptide bonds. The amount of each amino acid present after hydrolysis can then be quantified to determine the overall amino acid content of the protein.
22) If a tripeptide of Gly-Phe-Ala is subjected to acid hydrolysis, can the order of the residues in the tripeptide be determined afterward?22
Hydrolysis of a protein by another protein is called proteolysis or proteolytic cleavage, and the protein that does the cutting is known as a proteolytic enzyme or protease. Proteolytic cleavage is a specific means of cleaving peptide bonds. Many enzymes only cleave the peptide bond adjacent to a specific amino acid. For example, the protease trypsin cleaves on the carboxyl side of the positively charged (basic) residues arginine and lysine, while chymotrypsin cleaves adjacent to hydrophobic residues such as phenylalanine. (Do not memorize these examples.)
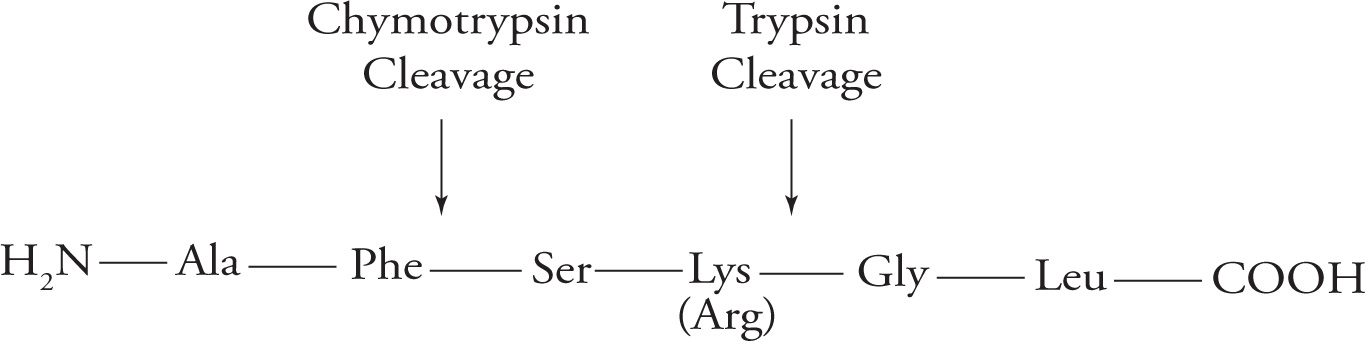
Specificity of Protease Cleavage
23) Based on the above, if the following peptide is cleaved by trypsin, what amino acid will be on the new N-terminus and how many fragments will result: Ala-Gly-Glu-Lys-Phe-Phe-Lys?23
The Disulfide Bond
Cysteine is an amino acid with a reactive thiol (sulfhydryl, SH) in its side chain. The thiol of one cysteine can react with the thiol of another cysteine to produce a covalent sulfur-sulfur bond known as a disulfide bond, as illustrated. The cysteines forming a disulfide bond may be located in the same or different polypeptide chain(s). The disulfide bridge plays an important role in stabilizing tertiary protein structure; this will be discussed in the section on protein folding. Once a cysteine residue becomes disulfide-bonded to another cysteine residue, it is called cystine instead of cysteine.
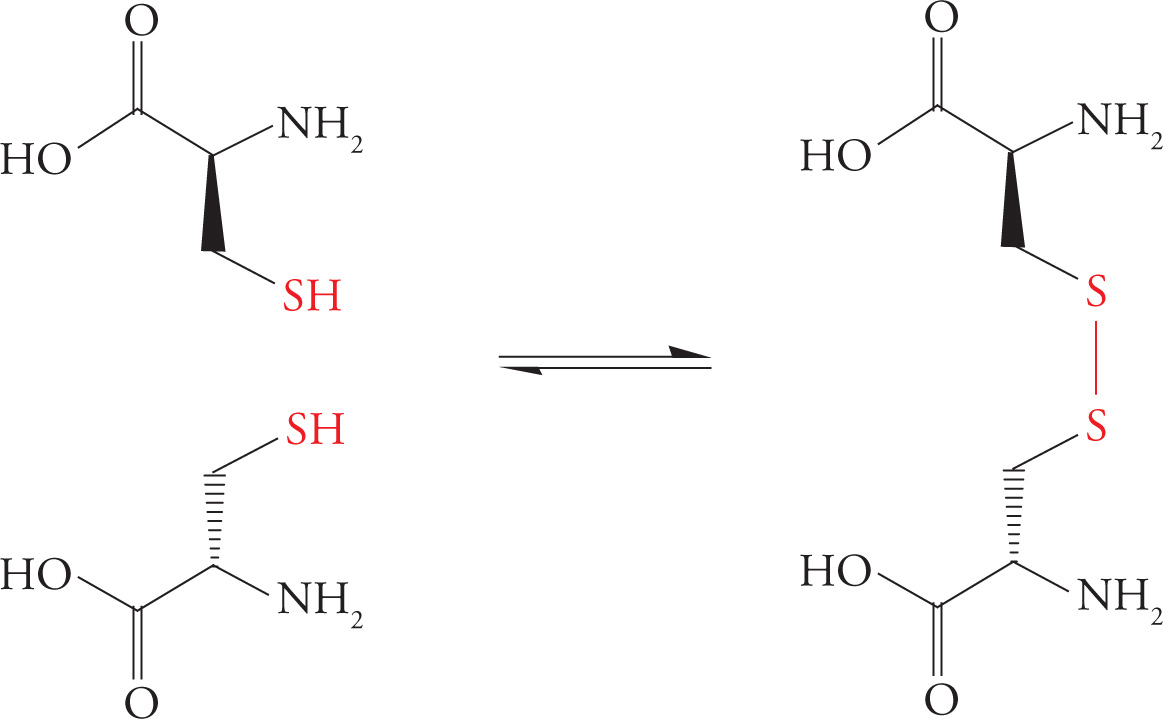
Formation of the Disulfide Bond
24) Which is more oxidized, the sulfur in cysteine or the sulfur in cystine?24
25) The inside of cells is known as a reducing environment because cells possess antioxidants (chemicals that prevent oxidation reactions). Where would disulfide bridges be more likely to be found, in extracellular proteins, under oxidizing conditions, or in the interior of cells, in a reducing environment?25
Protein Structure in Three Dimensions
Each protein folds into a unique three-dimensional structure that is required for that protein to function properly. Improperly folded, or denatured, proteins are non-functional. There are four levels of protein folding that contribute to their final three-dimensional structure. Each level of structure is dependent upon a particular type of bond, as discussed in the following sections.
Denaturation is an important concept. It refers to the disruption of a protein’s shape without breaking peptide bonds. Proteins are denatured by urea (which disrupts hydrogen bonding interactions), by extremes of pH, by extremes of temperature, and by changes in salt concentration (tonicity).
Primary (1o) Structure: The Amino Acid Sequence
The simplest level of protein structure is the order of amino acids bonded to each other in the polypeptide chain. This linear ordering of amino acid residues is known as primary structure. Primary structure is the same as sequence. The bond which determines 1ο structure is the peptide bond, simply because this is the bond that links one amino acid to the next in a polypeptide.
Secondary (2o) Structure: Hydrogen Bonds Between Backbone Groups
Secondary structure refers to the initial folding of a polypeptide chain into shapes stabilized by hydrogen bonds between backbone NH and CO groups. Certain motifs of secondary structure are found in most proteins. The two most common are the α-helix and the β-pleated sheet.
All α-helices have the same well-defined dimensions that are depicted below with the R-groups omitted for clarity. The α-helices of proteins are always right handed, 5 angstroms in width, with each subsequent amino acid rising 1.5 angstroms. There are 3.6 amino acid residues per turn with the α-carboxyl oxygen of one amino acid residue hydrogen-bonded to the α-amino proton of an amino acid three residues away. (Don’t memorize these numbers, but do try to visualize what they mean.)
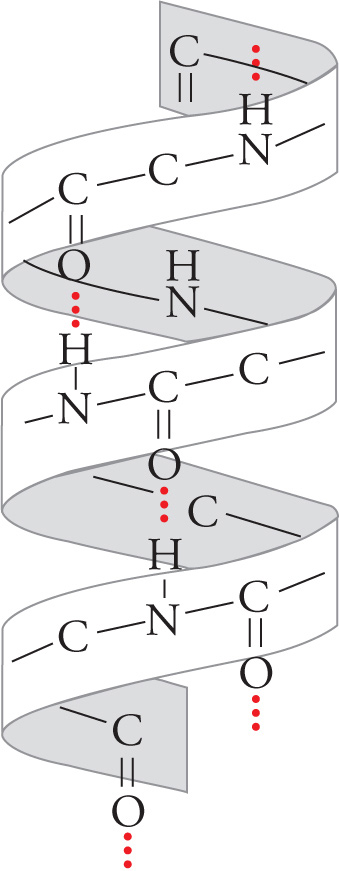
An α Helix
The unique structure of proline forces it to kink the polypeptide chain; hence proline residues never appear within the α-helix.
Proteins such as hormone receptors and ion channels are often found with α-helical transmembrane regions integrated into the hydrophobic membranes of cells. The α-helix is a favorable structure for a hydrophobic transmembrane region because all polar NH and CO groups in the backbone are hydrogen bonded to each other on the inside of the helix, and thus don’t interact with the hydrophobic membrane interior. α-Helical regions that span membranes also have hydrophobic R-groups, which radiate out from the helix, interacting with the hydrophobic interior of the membrane.
β-Pleated sheets are also stabilized by hydrogen bonding between NH and CO groups in the polypeptide backbone. In β-sheets, however, hydrogen bonding occurs between residues distant from each other in the chain or even on separate polypeptide chains. Also, the backbone of a β-sheet is extended, rather than coiled, with side groups directed above and below the plane of the β-sheet. There are two types of β-sheets, one with adjacent polypeptide strands running in the same direction (parallel β-pleated sheet) and another in which the polypeptide strands run in opposite directions (antiparallel β-pleated sheet).
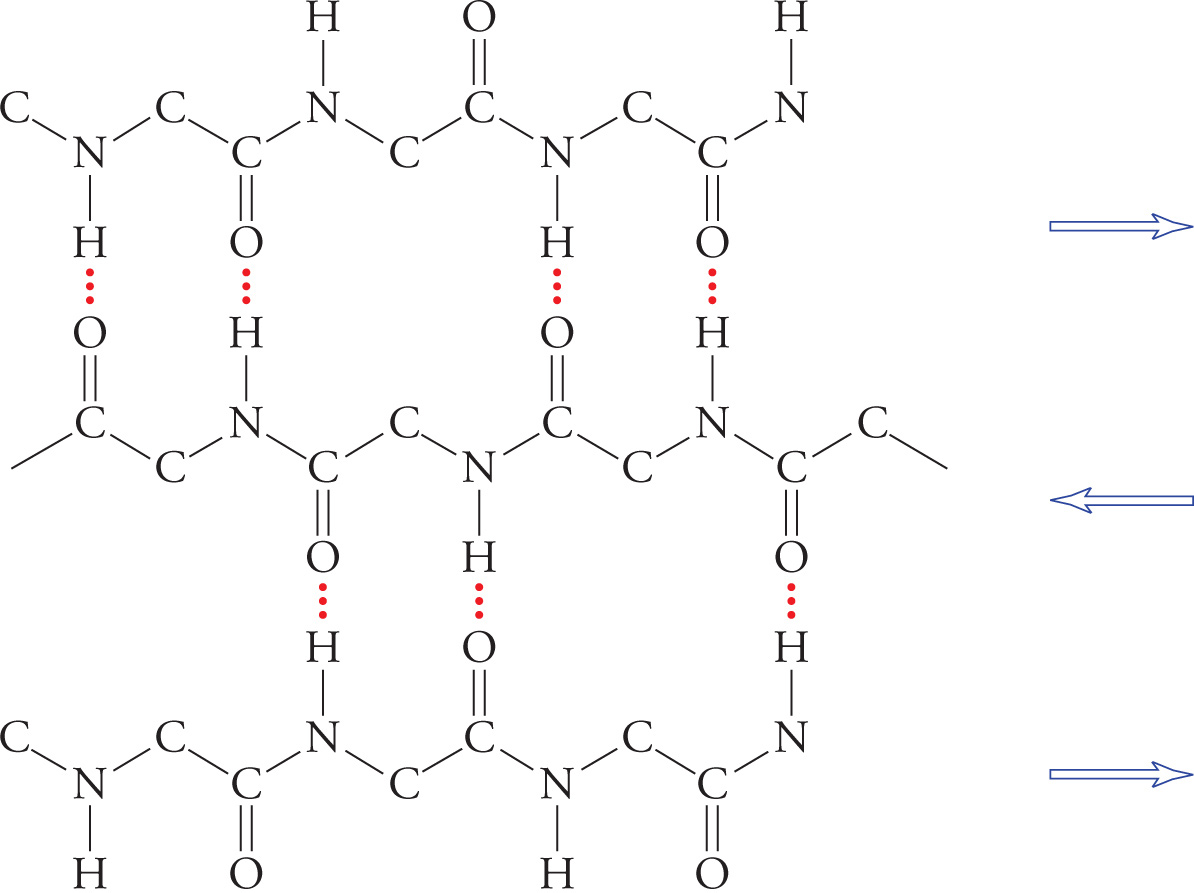
A β-Pleated Sheet
26) If a single polypeptide folds once and forms a β-pleated sheet with itself, would this be a parallel or antiparallel β-pleated sheet?26
27) What effect would a molecule that disrupts hydrogen bonding, e.g., urea, have on protein structure?27
Tertiary (3o) Structure: Hydrophobic/Hydrophilic Interactions
The next level of protein folding, tertiary structure, concerns interactions between amino acid residues located more distantly from each other in the polypeptide chain. The folding of secondary structures such as α-helices into higher order tertiary structures is driven by interactions of R-groups with each other and with the solvent (water). Hydrophobic R-groups tend to fold into the interior of the protein, away from the solvent, and hydrophilic R-groups tend to be exposed to water on the surface of the protein (shown for the generic globular protein).
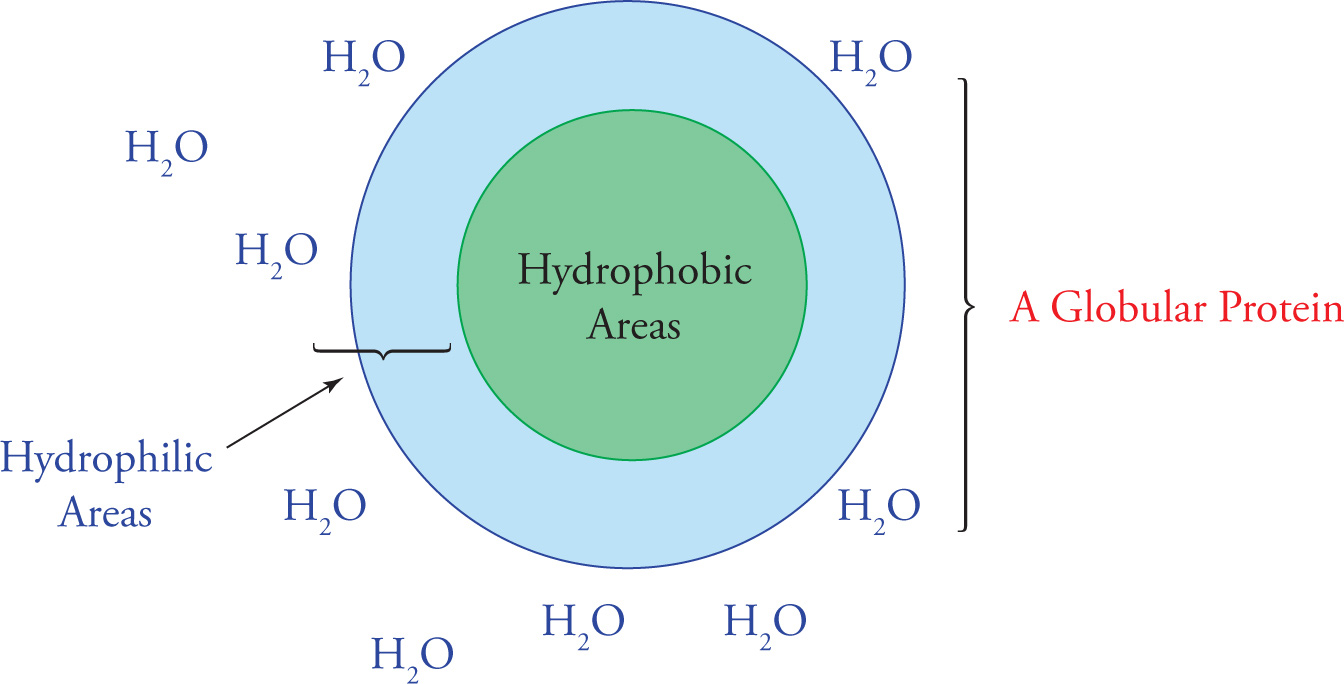
Folding of A Globular Protein in Aqueous Solution
Under the right conditions, the forces driving hydrophobic avoidance of water and hydrogen bonding will fold a polypeptide spontaneously into the correct conformation, the lowest energy conformation. In a classic experiment by Christian Anfinsen and coworkers, the effect of a denaturing agent (urea) and a reducing agent (β-mercaptoethanol) on the folding of a protein called ribonuclease were examined. In the following questions, you will reenact their thought processes. Figure out the answers before reading the footnotes.
28) Ribonuclease has eight cysteines that form four disulfides bonds. What effect would a reducing agent have on its tertiary structure?28
29) If the disulfides serve only to lock into place a tertiary protein structure that forms first on its own, then what effect would the reducing agent have on correct protein folding?29
30) Would a protein end up folded normally if you (1) first put it in a reducing environment, (2) then denatured it by adding urea, (3) next removed the reducing agent, allowing disulfide bridges to reform, and (4) finally removed the denaturing agent?30
31) What if you did the same experiment but in this order: 1, 2, 4, 3?31
The disulfide bridge is perhaps not a good example of 3° structure because it is a covalent bond, not a hydrophobic interaction. However, because the disulfide is formed after 2° structure and before 4° structure, it is usually considered part of 3° folding.
32) Which of the following may be considered an example of tertiary protein structure?32
I. van der Waals interactions between two Phe R-groups located far apart on a polypeptide
II. Hydrogen bonds between backbone amino and carboxyl groups
III. Covalent disulfide bonds between cysteine residues located far apart on a polypeptide
33) What effect would dissolving a globular protein in a hydrophobic organic solvent such as hexane have on tertiary protein structure?33
Quaternary (4o) Structure: Various Bonds Between Separate Chains
The highest level of protein structure, quaternary structure, describes interactions between polypeptide subunits. A subunit is a single polypeptide chain that is part of a large complex containing many subunits (a multisubunit complex). The arrangement of subunits in a multisubunit complex is what we mean by quaternary structure. For example, mammalian RNA polymerase II contains twelve different subunits. The interactions between subunits are instrumental in protein function, as in the cooperative binding of oxygen by each of the four subunits of hemoglobin.
The forces stabilizing quaternary structure are generally the same as those involved in secondary and tertiary structure—non-covalent interactions (the hydrogen bond and the van der Waals interaction). However, covalent bonds may also be involved in quaternary structure. For example, antibodies (immune system molecules) are large protein complexes with disulfide bonds holding the subunits together. It is key to understand, however, that there is one covalent bond that may not be involved in quaternary structure—the peptide bond—because this bond defines sequence (1° structure).
34) What is the difference between a disulfide bridge involved in quaternary structure and one involved in tertiary structure?34
7.3 CARBOHYDRATES
Carbohydrates are chains of hydrated carbon atoms with the molecular formula CnH2nOn. The chain usually begins with an aldehyde or ketone and continues as a polyalcohol in which each carbon has a hydroxyl substituent. Carbohydrates are produced by photosynthesis in plants and by biochemical synthesis in animals. Carbohydrates can be broken down to CO2 in a process called oxidation, which is also known as burning or combustion. Because this process releases large amounts of energy, carbohydrates serve as the principle energy source for cellular metabolism. Glucose in the form of the polymer cellulose is also the building block of wood and cotton. Understanding the nomenclature, structure, and chemistry of carbohydrates is essential to understanding cellular metabolism. This chapter will also help you understand key facts such as why we can eat potatoes and cotton candy but not wood and cotton T-shirts, and why milk makes some adults flatulent.
Structure and Nomenclature of Monosaccharides
A single carbohydrate molecule is a monosaccharide (meaning “single sweet unit”), also known as a simple sugar. Two monosaccharides bonded together form a disaccharide; several bonded together make an oligosaccharide, and many make a polysaccharide. If these polymers are subjected to strong acid, they are hydrolyzed to monosaccharides, which are not further hydrolyzed.
Classes of monosaccharides are given a two-part name. The first part is either “aldo” or “keto,” depending on whether an aldehyde or a ketone is present. The second part reveals the number of carbon atoms in the chain: trioses are the smallest and have three carbons; tetroses have four, pentoses five, hexoses six, and heptoses seven. For example, the polyhydroxy aldehyde glucose is an aldohexose because it is a six-carbon chain beginning in an aldehyde. “Glucose” and “fructose” are examples of common names. IUPAC nomenclature is not usually used with individual carbohydrates because the systematic names are so long.
The carbons in monosaccharides are numbered beginning with carbon #1 at the most oxidized end of the carbon chain, which is the end with the aldehyde or ketone.
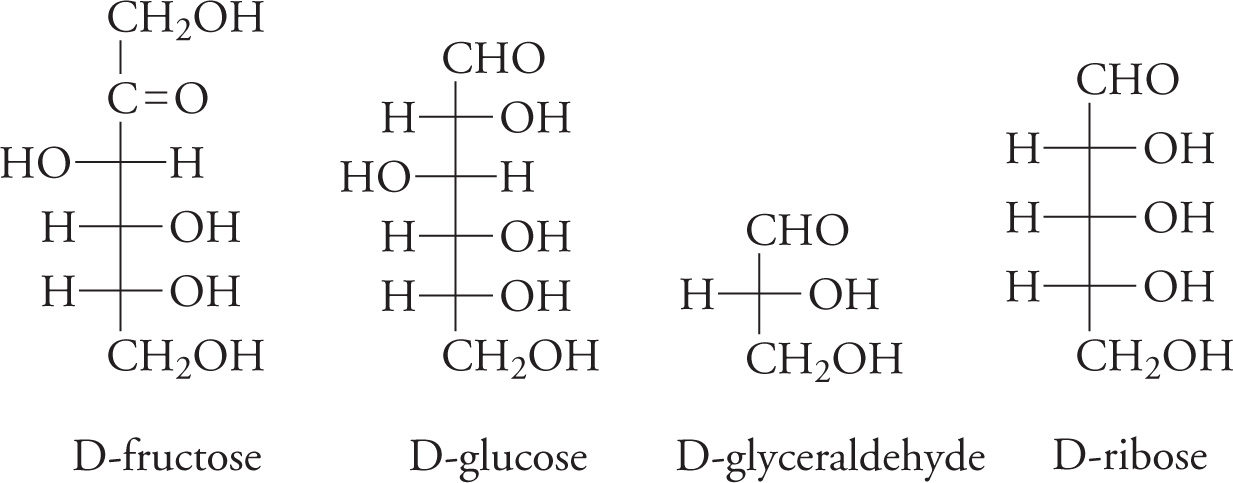
Some Metabolically Important Simple Sugars and Common Sugars on the MCAT
35) Which of the sugars in the figure above is a ketohexose?35
36) Which carbon (#?) is the most oxidized in fructose?36
Absolute Configuration of Monosaccharides
Because carbohydrates contain chiral carbons, it is also necessary to classify them according to stereochemistry. Like amino acids, carbohydrates are assigned one of two configurations, either D or L, based on the configuration of the last chiral carbon in the chain (farthest from the aldehyde or ketone). By convention, this configuration is determined by comparison with glyceraldehyde. If a monosaccharide’s last chiral carbon matches the chiral carbon of D-glyceraldehyde, it will be assigned the “D” label. The sugars in our bodies have the D configuration. When you are drawing a Fischer projection of a monosaccharide, put the aldehyde or ketone on top and the CH2OH group (last carbon) on the bottom. The last chiral carbon will have its OH on the Left for L monosaccharides. However, we have only D-sugars in our bodies. Remember that we have only L-amino acids and only D-sugars.
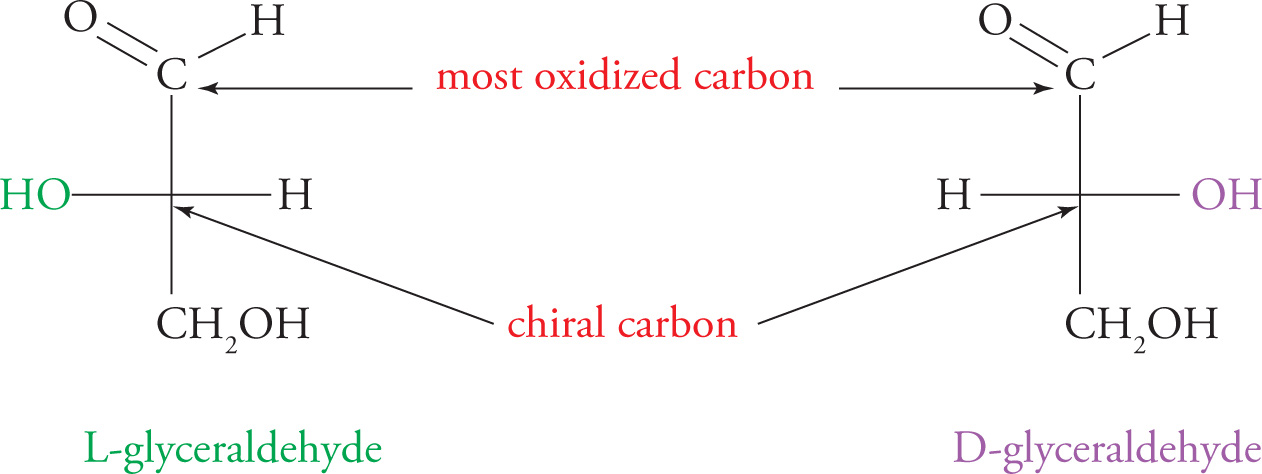
The Fischer Notation for Carbohydrates
For a given class of monosaccharide (like any other chiral molecule), there are 2n different stereoisomers, where n is the number of chiral carbons.
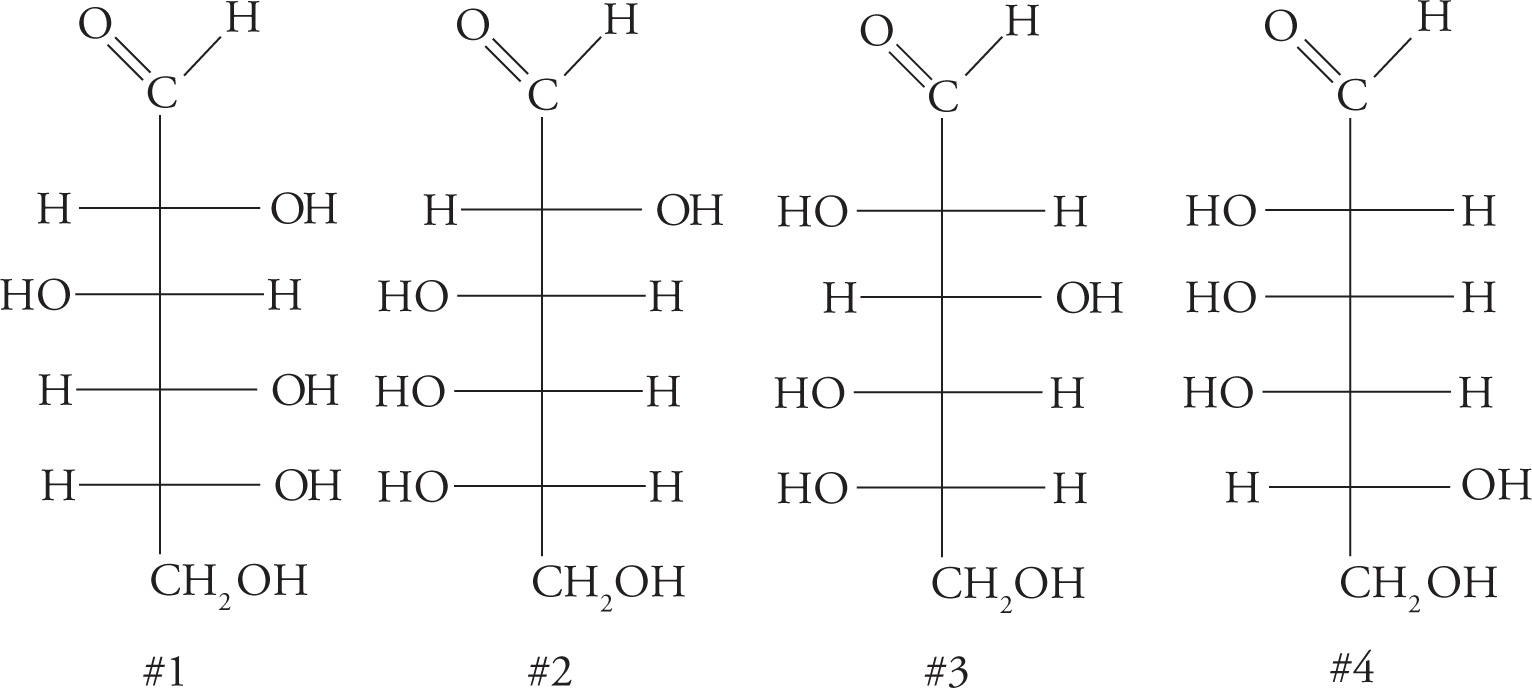
Four Monosaccharide Stereoisomers
37) Consider the four monosaccharides on the previous page. Which one of the following is correct?37
A. Carbohydrate #2 is a D sugar and an enantiomer of #4.
B. Carbohydrate #2 is an enantiomer of #3.
C. Carbohydrates #1 and #3 are epimers and enantiomers.
D. Carbohydrates #1 and #3 are enantiomers.
38) There are _____ aldohexoses and _______ D-aldohexoses (tough question but you do have all the information you need to figure it out).38
39) Is it possible to produce a diastereomer of D-glyceraldehyde? How about an epimer?39
Since we already discussed the relationships between the terms isomer, stereoisomer, enantiomer, diastereomer, and epimer in Chapter 4, we will not discuss them again here. The following Venn diagram represents a concise way of categorizing these terms. It shows which groups are subsets of which. Isomers have the same atoms but different bonds, unless they are also stereoisomers. Stereoisomers have the same atoms and the same bonds, but different bond geometries. All stereoisomers are either enantiomers or diastereomers. Some diastereomers are epimers.
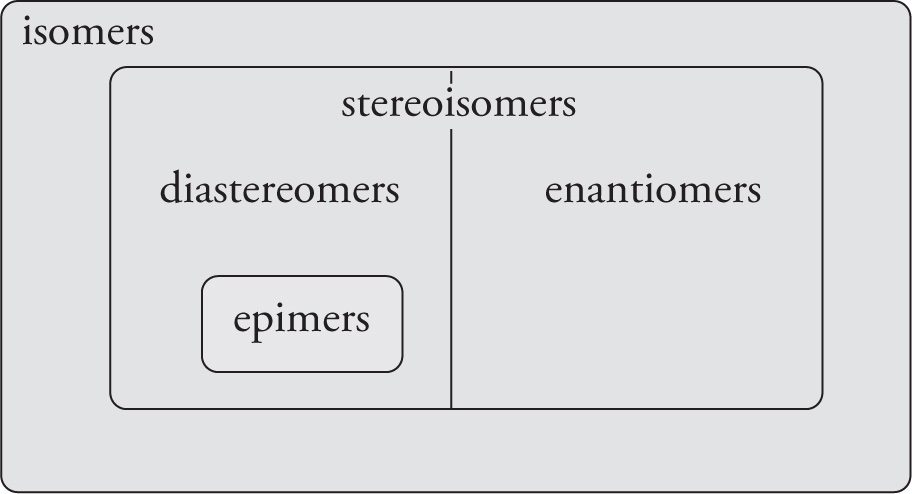
A Venn Diagram for Stereoisomers
Cyclic Structures of Monosaccharides
So far, we have represented the monosaccharides as straight chain structures. In solution, however, hexoses and pentoses spontaneously form five- and six-membered rings. In fact, the cyclic structures are thermodynamically favored, so that only a small percentage usually exist in the open chain form. The six-membered ring structures are termed pyranoses due to their resemblance to pyran, and five-membered sugar rings are termed furanoses due to their resemblance to furan.

Let’s take glucose as an example. The ring forms when the OH on C5 nucleophilically attacks the carbonyl carbon (C1), forming a hemiacetal. The reactions involved, in which an alcohol reacts with an aldehyde to produce a hemiacetal (one −OR group and one −OH group) and subsequently an acetal (two −OR groups), are shown below (see also Section 6.1). The difference between an acetal and a hemiacetal is that the hemiacetal is in constant equilibrium with the carbonyl form. The acetal form, in contrast, is quite stable, requiring an enzyme to react.
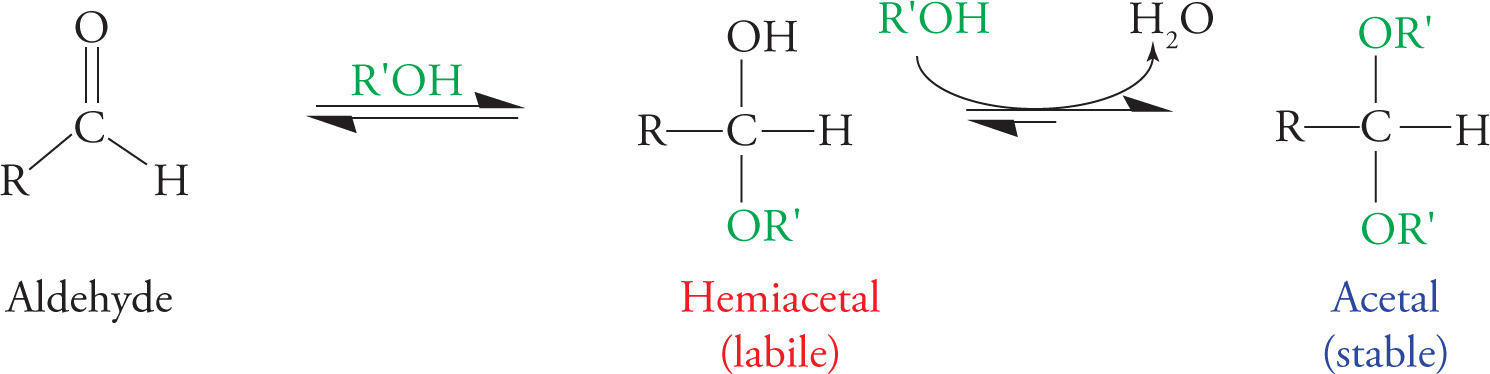
Formation of a Hemiacetal and an Acetal
The figure below shows the reaction for glucose. This manner of drawing ring structures is a modified form of Fischer notation, useful for indicating which carbons are involved in forming the cyclical structure, but unrealistic in terms of bond lengths and angles.
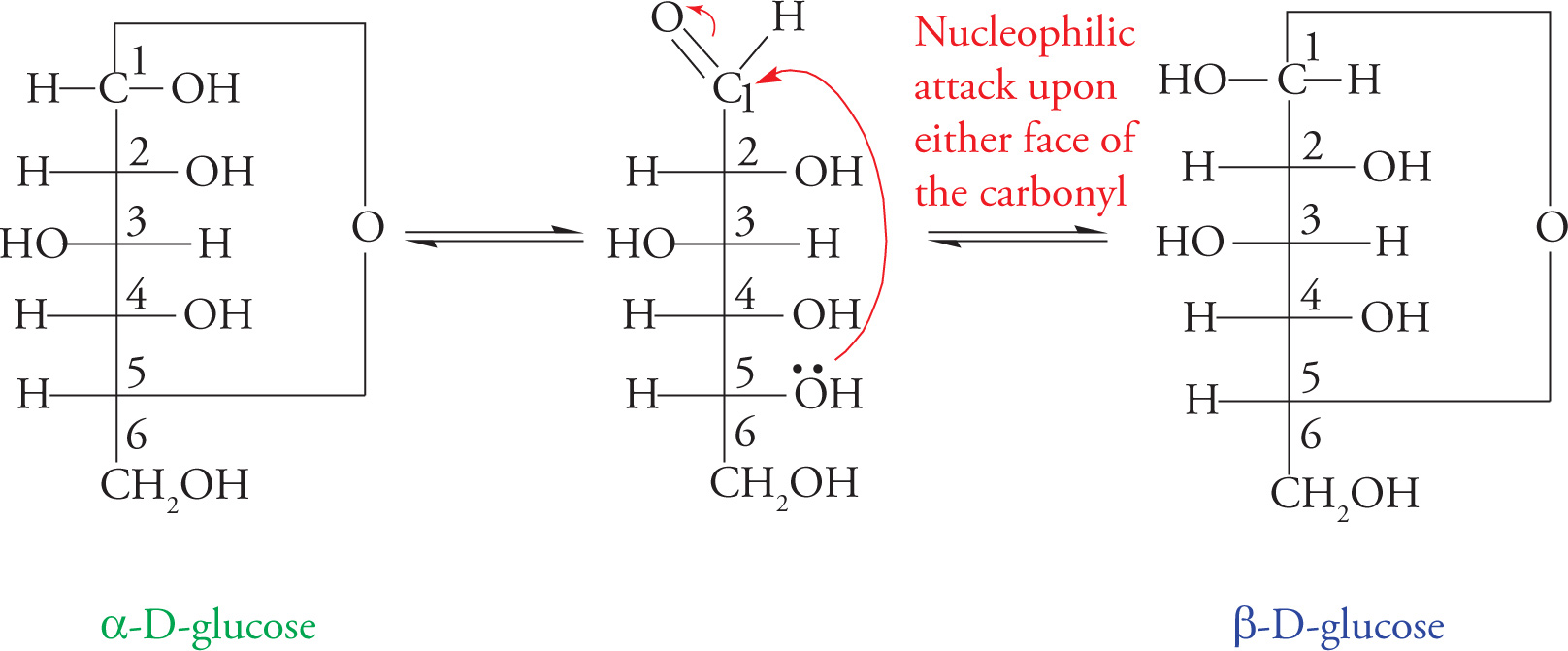
Glucopyranose Formation: A Nucleophilic Addition Reaction
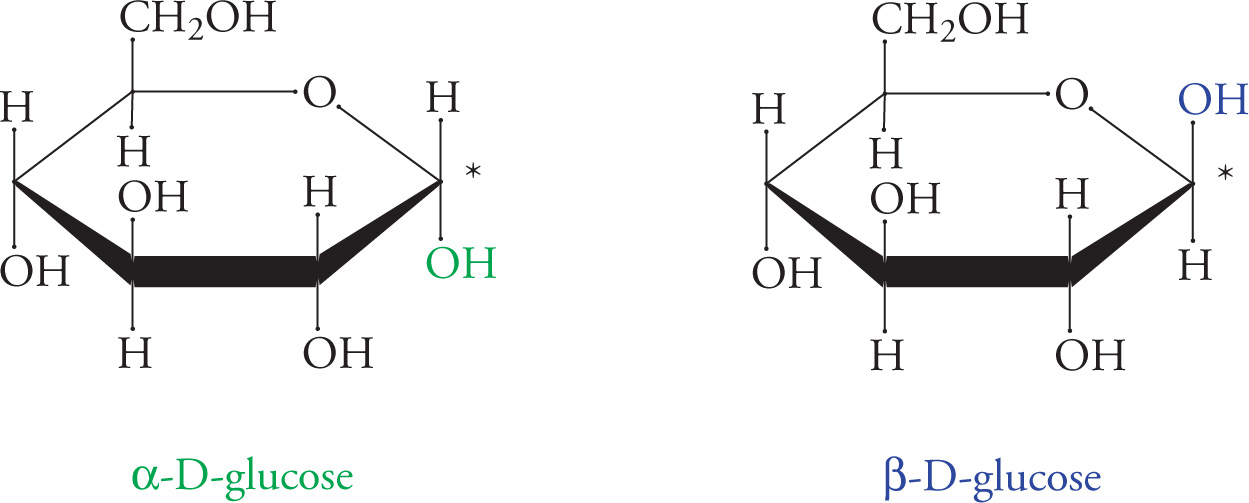
The more realistic “chair” representations of these structures are shown below. Note that two different ring structures are shown, α and β. The α or β ring is formed depending upon from which face of the carbonyl the C5-hydroxyl group attacks. If the attack comes from one face, the carbonyl oxygen will become an equatorial hydroxyl group; if the attack comes from the other face, the carbonyl oxygen will become an axial hydroxyl group. [To distinguish the forms, remember, “It’s always better to βE up (happy)!” This will help you remember that in β-D-Glucose, the anomeric hydroxyl group is up.] The two forms are called anomers, and C1 (designated with an asterisk in the figures) is called the anomeric carbon. The anomeric carbon is always the carbonyl carbon, so in aldoses it is C1, but in ketoses it is C2. The interconversion between the two anomers is called mutarotation.
The groups on the left in Fischer notation are above the ring in chair notation. Also, remember that axial substituents on six-membered chair rings are those that point straight up or down. The equatorial substituents point out from the ring. Equatorial substituents have less steric hindrance with the ring and are thus thermodynamically more favorable.
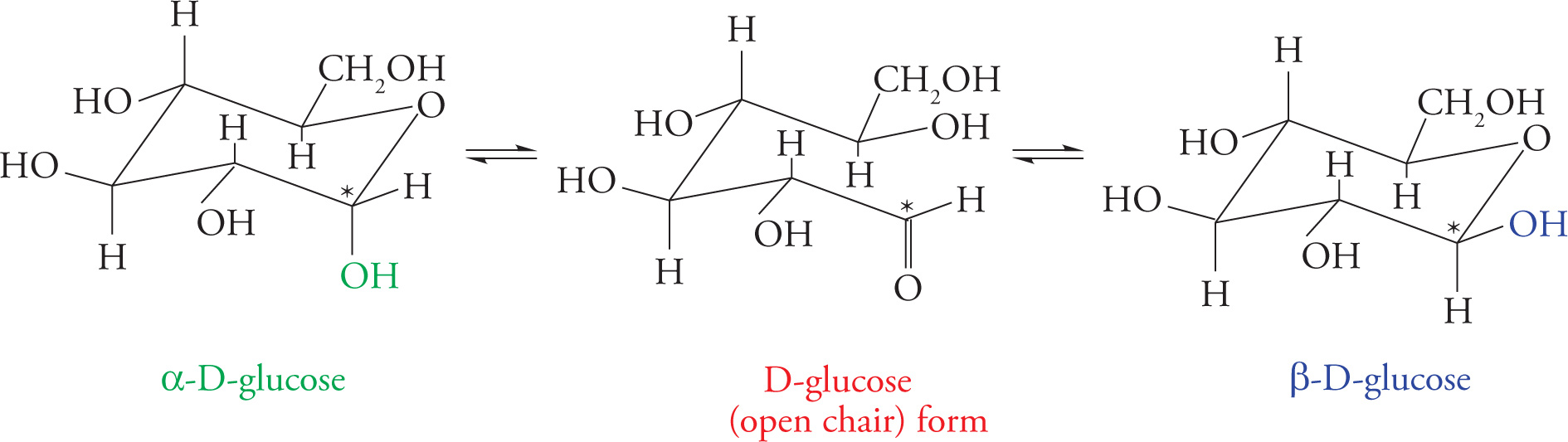
Chair Representation of Glucopyranose Formation
40) Why doesn’t glucose cyclize into three- or four-membered rings?40
41) Are the OH’s in β-D-glucopyranose axial or equatorial?41
42) A solution of glucose may contain both furanose and pyranose rings. How can the same sugar exist in both forms?42
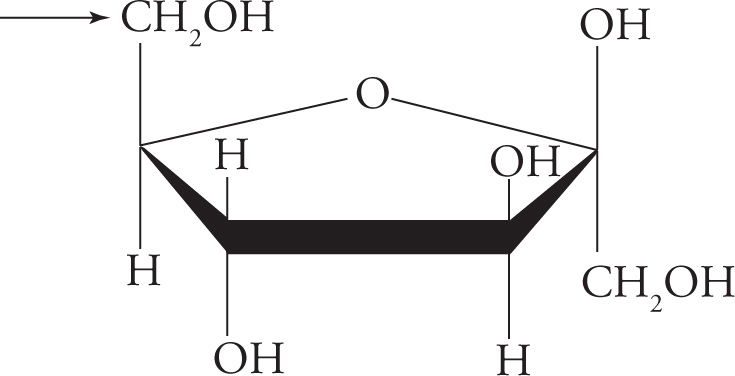
Another way to represent cyclic sugars is called Haworth notation. The groups on the left in Fischer notation are above the ring in Haworth notation (as in the chair form). A summary of how to convert Fischer Projections of sugars to Haworth Projections is as follows:
1. Draw the basic structure of the sugar.
2. If the sugar is a D-sugar, place a −CH2OH above the ring on the carbon to the left of the oxygen. For an L-sugar, place it below the ring.
3. For an α-sugar, place an −OH below the ring on the carbon to the right of the ring oxygen. For a β-sugar, place the −OH above the ring.
4. Finally, −OH groups on the right go below the ring and those on the left above, using the −CH2OH group as the reference point for both projections.
Haworth Representation of Glucopyranose
43) A monosaccharide is represented below in Haworth notation. What number is the carbon that the arrow is pointing toward? Is this a furanose or a pyranose? Is it the α- or β-anomer?43
44) Is this a D- or L-sugar? How many chiral carbons does it have?44
Structure and Nomenclature of Disaccharides
Recall that two monosaccharides bonded together form a disaccharide, a few form an oligosaccharide, and many form a polysaccharide. The bond between two sugar molecules is called a glycosidic linkage. This is a covalent bond, formed in a dehydration reaction that requires enzymatic catalysis.
Typically, the glycosidic bond joins C1 of one pyranose or furanose to C4 (sometimes C2 or C6) of another pyranose or furanose through an oxygen atom. Is the anomeric carbon in a hemiacetal form, or is it in an acetal form once it is part of a glycosidic bond? It has two −OR constituents, so it forms an acetal group. The significance of this is that the glycosidic linkage stays in the α or β configuration until an enzyme breaks the bond, because the acetal is a stable functional group. In other words, once a monosaccharide has attacked another sugar to form a glycosidic linkage, it is no longer free to mutarotate. This is an important concept, and we will discuss it further in the section on reducing sugars.
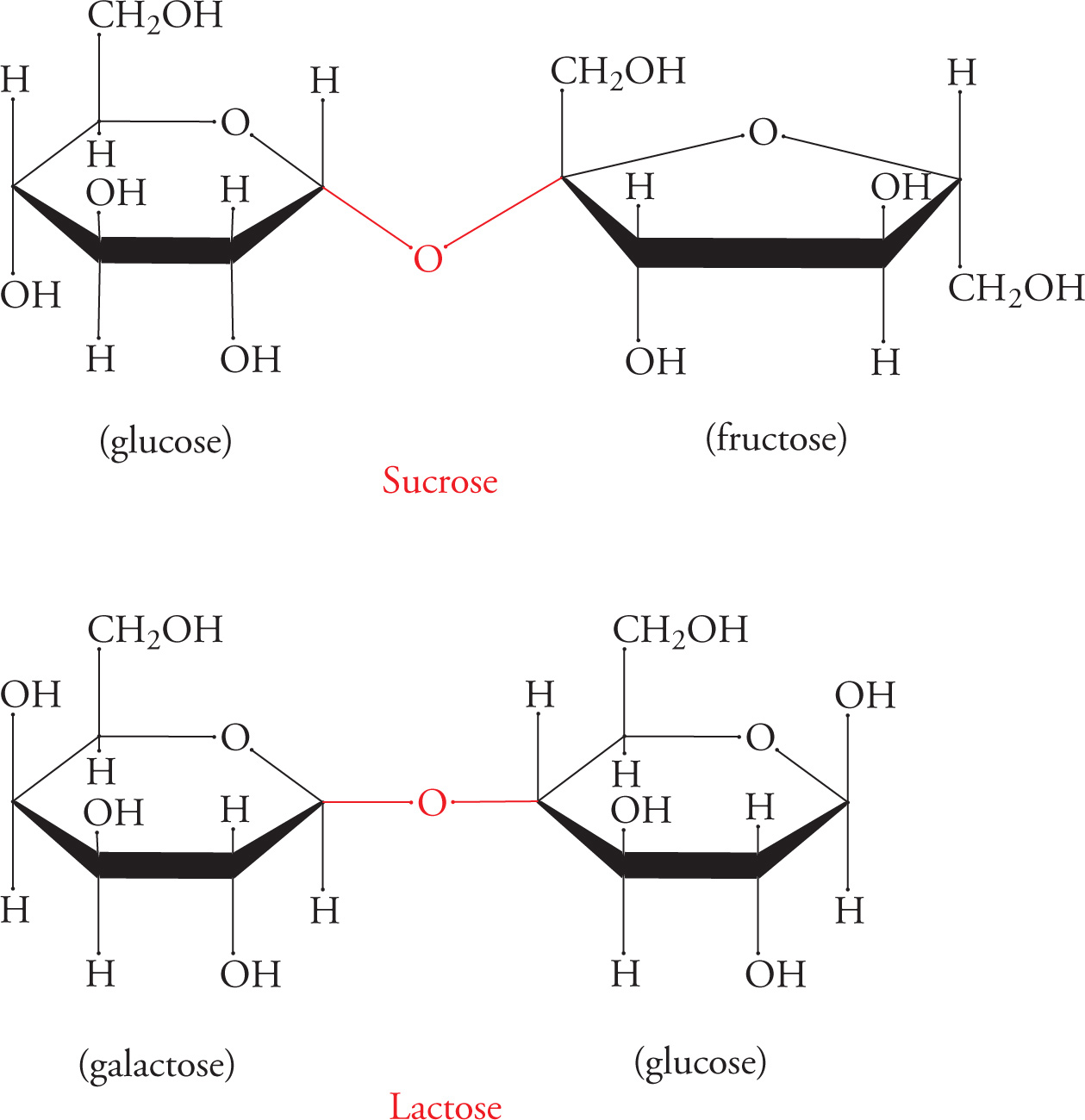
Disaccharides and the α- or β-Glycosidic Bond
Glycosidic linkages are named according to which carbon in each sugar comprises the linkage. The configuration (α or β) of the linkage is also specified. For example, lactose (milk sugar) is a disaccharide joined in a galactose-β-1,4-glucose linkage (above). Sucrose (table sugar) is also shown above, with a glucose unit and a fructose unit.
45) Does sucrose contain an α- or β-glycosidic linkage?45
Some common disaccharides you might see on the MCAT are sucrose (Glc-α-1,2-Fru), lactose (Gal-β-1,4-Glc), maltose (Glc-α-1,4-Glc), and cellobiose (Glc-β-1,4-Glc). However, you should NOT try to memorize these linkages.
Polymers made from these disaccharides form important biological macromolecules. Glycogen serves as an energy storage carbohydrate in animals and is composed of thousands of glucose units joined in α−1,4 linkages; α−1,6 branches are also present. Starch is the same as glycogen (except that the branches are a little different), and serves the same purpose in plants. Cellulose is a polymer of cellobiose; the β-glycosidic bonds allow the polymer to assume a long, straight, fibrous shape. Wood and cotton are made of cellulose.
The hydrolysis of polysaccharides into monosaccharides is essential for monosaccharides to enter metabolic pathways (e.g., glycolysis) and be used for energy by the cell. Different enzymes catalyze the hydrolysis of different linkages. The enzyme is named for the sugar it hydrolyzes. For example, the enzyme that catalyzes the hydrolysis of maltose into two glucose monosaccharides is called maltase. Each enzyme is highly specific for its linkage.
This specificity is a great example of the significance of stereochemistry. Consider cellulose. A cotton T-shirt is pure sugar. The only reason we can’t digest it is that mammalian enzymes can’t deal with the β-glycosidic linkages that make cellobiose from glucose. Cellulose is actually the energy source in grass and hay. Cows are mammals, and all mammals lack the enzymes necessary for cellobiose breakdown. To live on grass, cows depend on bacteria that live in an extra stomach called a rumen to digest cellulose for them. If you’re really on the ball, you’re next question is: Humans are mammals, so how can we digest lactose, which has a β linkage? The answer is that we have a specific enzyme, lactase, which can digest lactose. This is an exception to the rule that mammalian enzymes cannot hydrolyze β-glycosidic linkages. People without lactase are lactose malabsorbers, and any lactose they eat ends up in the colon. There it may cause gas and diarrhea, if certain bacteria are present; people with this problem are said to be lactose intolerant. People produce lactase as children so that they can digest mother’s milk, but most adults naturally stop making this enzyme, and thus become lactose malabsorbers and sometimes intolerant.
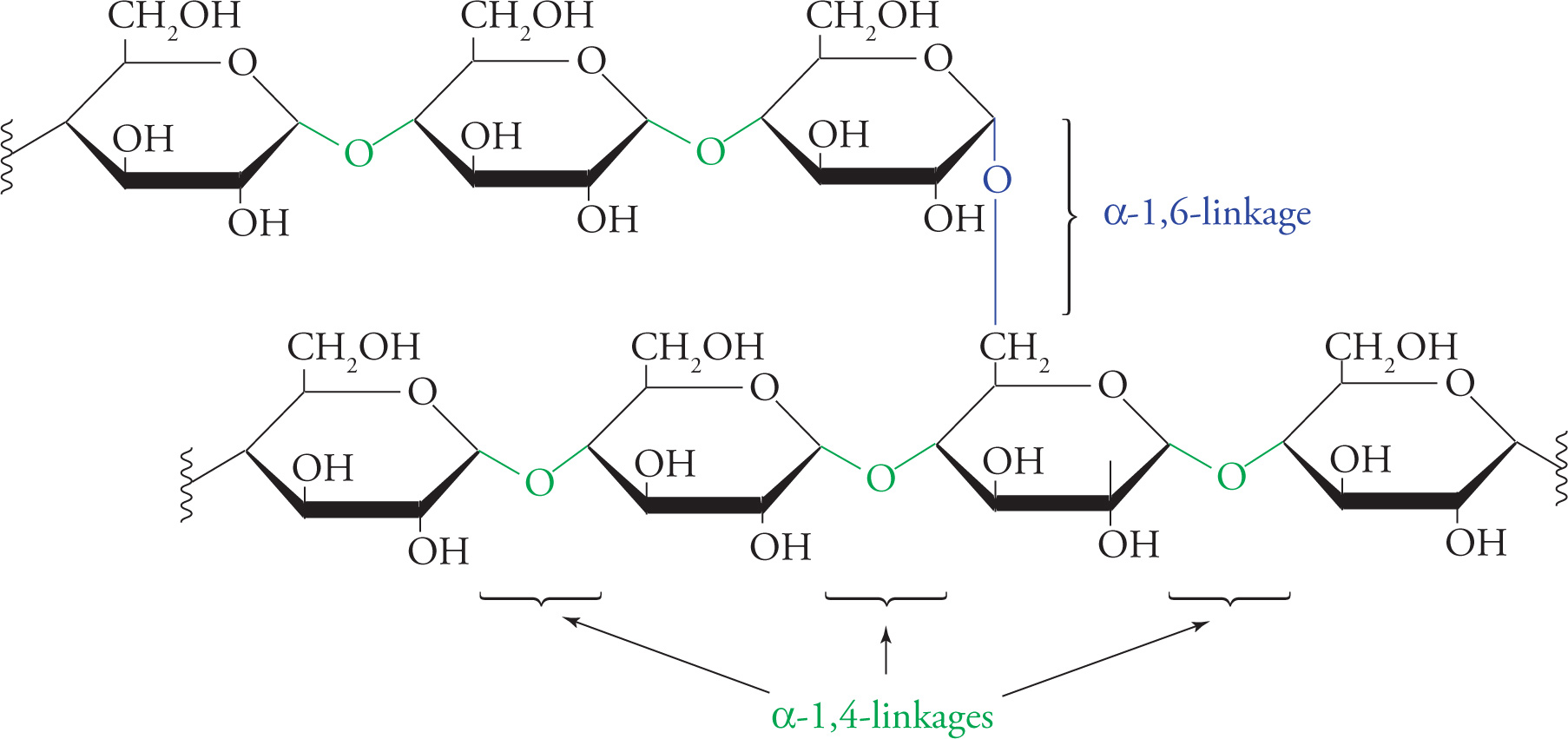
The Polysaccharide Glycogen
Hydrolysis of Glycosidic Linkages
Disaccharides and polysaccharides are broken down into their component monosaccharides by enzymatic hydrolysis. This just means water is the nucleophile, and one of the sugars is the leaving group (the one that was the attacker during bond formation). In other words, the cleavage reaction is precisely the reverse of the formation reaction.
Hydrolysis of polysaccharides into monosaccharides is favored thermodynamically. This means the hydrolysis of polysaccharides releases energy in the cell. However, it does not occur at a significant rate without enzymatic catalysis. As catalysts, enzymes increase reaction rates by lowering the activation energy but do not change final concentrations of reactants and products.
46) Which requires net energy input: polysaccharide synthesis or hydrolysis?46
47) If the activation energy of polysaccharide hydrolysis were so low that no enzyme was required for the reaction to occur, would this make polysaccharides better for energy storage?47
Reducing Sugars
This is a simple concept that often confuses students. Benedict’s test is a chemical assay that detects the carbonyl units of sugars. It is useful because it distinguishes hemiacetals from acetals [only hemiacetals are in equilibrium with the carbonyl (open-chain) form]. For example, if you had a white powder that you knew to be composed of glucose, you would be able to say whether the glucose existed in the free monosaccharide form or was in the form of glycogen. How? Well, if it’s in the monosaccharide form, there will be many hemiacetals, and Benedict’s test will be strongly positive. However, if the powder consists of only relatively few glycogen molecules, Benedict’s will be only weakly positive. This is because all the glucose units in a glycogen polymer are tied up in acetal linkages, except for the very first one in the chain (the one which was first attacked during polymerization).
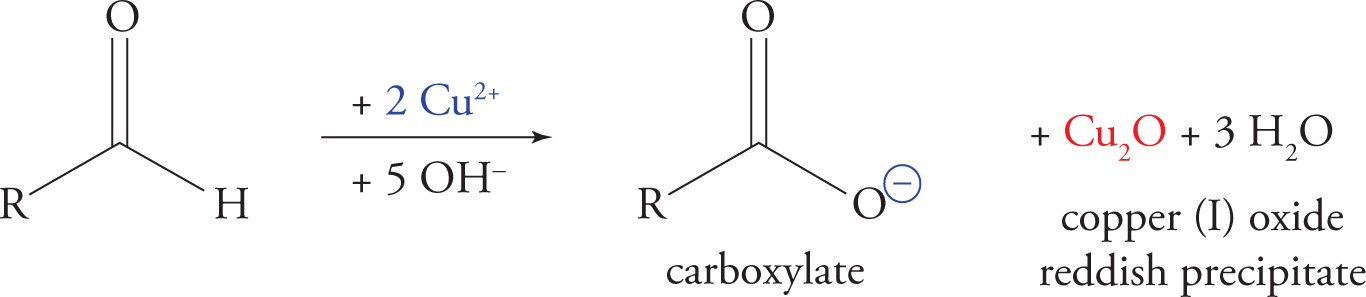
Benedict’s Test for Reducing Sugars
Benedict’s test is performed as follows: Benedict’s reagent, an oxidized form of copper, is used to oxidize a sugar’s aldehyde or ketone to the corresponding carboxylic acid, yielding a reddish precipitate. Any carbohydrate that can be oxidized by Benedict’s reagent is referred to as a reducing sugar because it reduces the Cu2+ to Cu+ while itself being oxidized. All monosaccharides are reducing sugars. More generally, all aldehydes, ketones, and hemiacetals give a positive result in Benedict’s test for reducing sugars; acetals give a negative result because they do not react with Cu2+, and they are not in equilibrium with the open-chain (carbonyl) form.
48) Which carbon of glucose can be oxidized by Benedict’s reagent? What about fructose?48
Recall that we’ve said once a monosaccharide has attacked another sugar to form a glycosidic linkage, it is no longer free to mutarotate. Now we can expand this statement as follows: Once a monosaccharide has attacked another sugar to form a glycosidic linkage, its anomeric carbon is in an acetal configuration and is thus no longer free to mutarotate nor to reduce Benedict’s reagent.
49) If 98% of a monosaccharide is present as the ring form at equilibrium in solution, then how much of the sugar can be oxidized in Benedict’s reaction?49
50) Is lactose a reducing sugar? What about sucrose? (You may refer back to the text and figures previously.)50
7.4 LIPIDS
Lipids are oily or fatty substances that play three physiological roles, summarized here and discussed below.
• In cellular membranes, phospholipids constitute a barrier between intracellular and extracellular environments.
• In adipose cells, triglycerides (fats) store energy.
• Finally, cholesterol is a special lipid that serves as the building block for the hydrophobic steroid hormones.
The cardinal characteristic of the lipid is its hydrophobicity. Hydrophobic means water-fearing. It is important to understand the significance of this. Since water is very polar, polar substances dissolve well in water; these are known as water-loving, or hydrophilic substances. Carbon-carbon bonds and carbon-hydrogen bonds are nonpolar. Hence, substances that contain only carbon and hydrogen will not dissolve well in water. Some examples: table sugar dissolves well in water, but cooking oil floats in a layer above water or forms many tiny oil droplets when mixed with water. Cotton T-shirts become wet when exposed to water because they are made of glucose polymerized into cellulose, but a nylon jacket does not become wet because it is composed of atoms covalently bound together in a nonpolar fashion. A synonym for hydrophobic is lipophilic (which means lipid-loving); a synonym for hydrophilic is lipophobic. We return to these concepts below.
Fatty Acid Structure
Fatty acids are composed of long unsubstituted alkanes that end in a carboxylic acid. The chain is typically 14 to 18 carbons long, and because they are synthesized two carbons at a time from acetate, only even-numbered fatty acids are made in human cells. A fatty acid with no carbon-carbon double bonds is said to be saturated with hydrogen because every carbon atom in the chain is covalently bound to the maximum number of hydrogens. Unsaturated fatty acids have one or more double bonds in the tail. These double bonds are almost always (Z) (or cis). The position of a double bond in the alkyl chain of a fatty acid is denoted by the symbol ∆ and the number of the first carbon involved in the double bond. Carbons are numbered starting with the carboxylic acid carbon. For example, a (Z) double bond between carbons 3 and 4 in a fatty acid would be referred to as (Z)-∆3 (or cis-∆3).
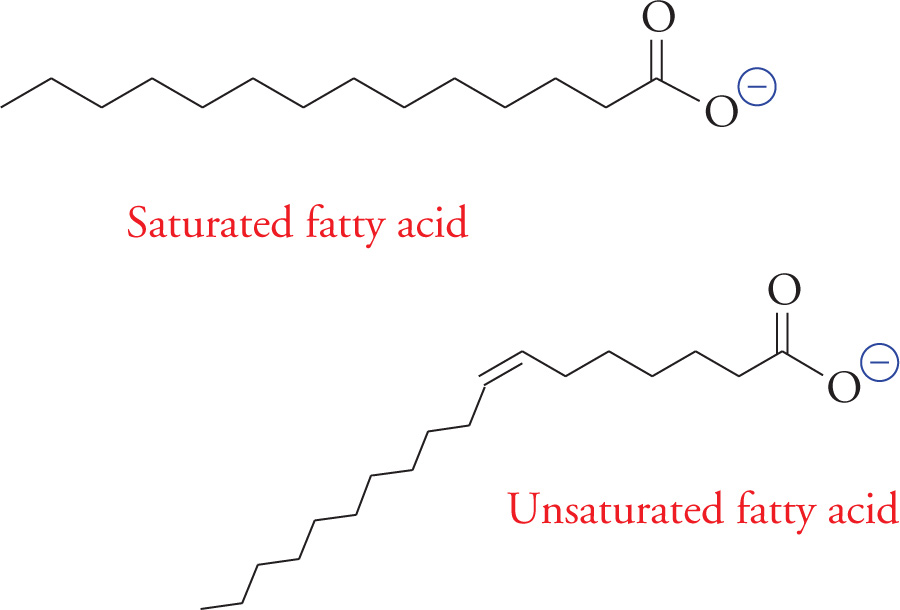
51) What is the correct nomenclature for the double bond in the unsaturated fatty acid above?51
52) How does the shape of an unsaturated fatty acid differ from that of a saturated fatty acid?52
53) If fatty acids are mixed into water, how are they likely to associate with each other?53
The drawing on the next page illustrates how free fatty acids interact in an aqueous solution; they form a structure called a micelle. The force that drives the tails into the center of the micelle is called the hydrophobic interaction. The hydrophobic interaction is a complex phenomenon. In general, it results from the fact that water molecules must form an orderly solvation shell around each hydrophobic substance. The reason is that H2O has a dipole that “likes” to be able to share its charges with other polar molecules. A solvation shell allows for the most water-water interaction and the least water-lipid interaction. The problem is that forming a solvation shell is an increase in order and thus a decrease in entropy (∆S < 0), which is unfavorable according to the second law of thermodynamics. In the case of the fatty acid micelle, water forms a shell around the spherical micelle with the result being that water interacts with polar carboxylic acid head groups while hydrophobic lipid tails hide inside the sphere.
Soaps are the sodium salts of fatty acids (RCOO−Na+). They are amphipathic, which means both hydrophilic and hydrophobic.
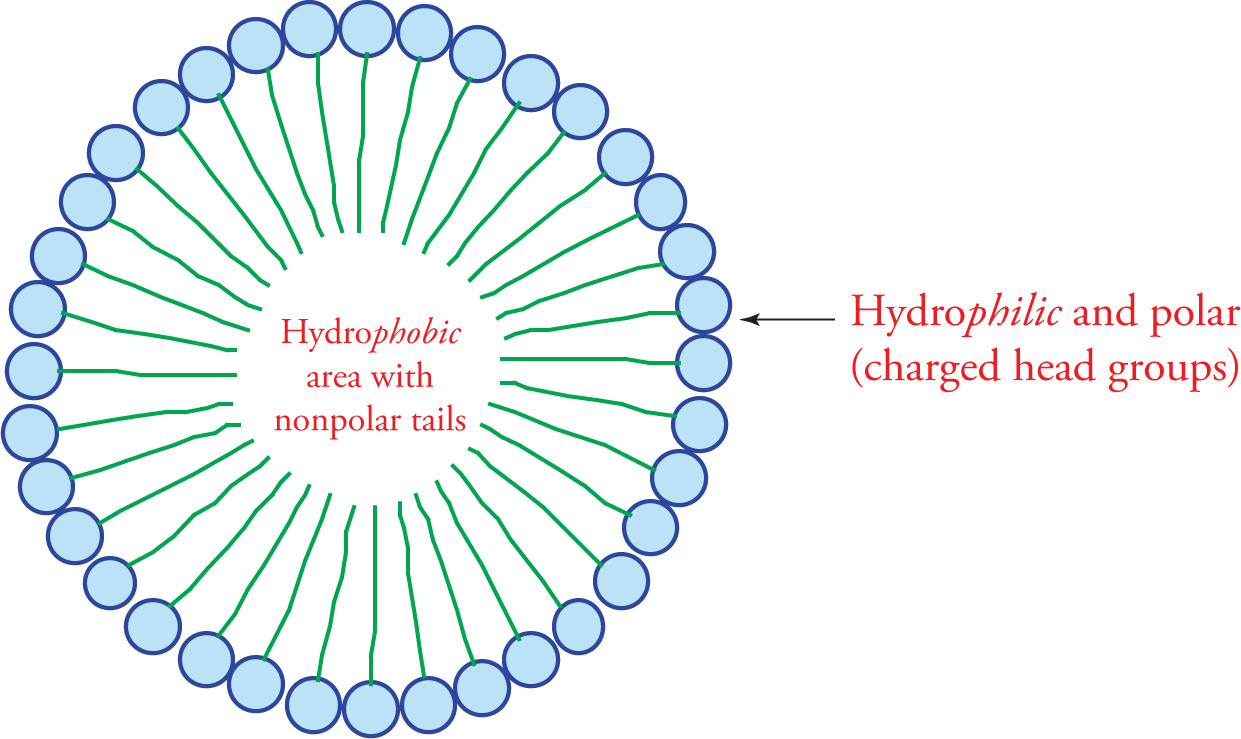
A Fatty Acid Micelle
54) How does soap help to remove grease from your hands?54
Triacylglycerols (TG)
The storage form of the fatty acid is fat. The technical name for fat is triacylglycerol or triglyceride (shown below). The triglyceride is composed of three fatty acids esterified to a glycerol molecule. Glycerol is a three-carbon triol with the formula HOCH2−CHOH−CH2OH. As you can see, it has three hydroxyl groups that can be esterified to fatty acids. It is necessary to store fatty acids in the relatively inert form of fat because free fatty acids are reactive chemicals.
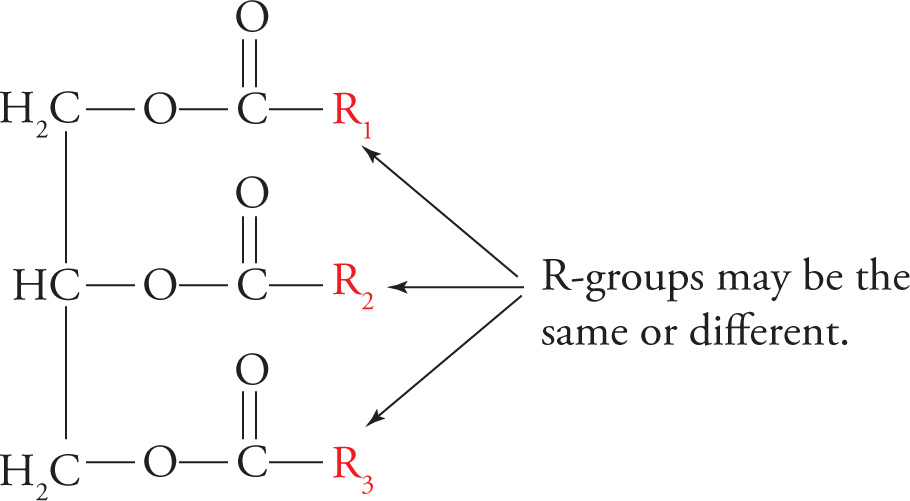
A Triglyceride (Fat)
The triacylglycerol undergoes reactions typical of esters, such as base-catalyzed hydrolysis. Soap is economically produced by base-catalyzed hydrolysis of triglycerides from animal fat into fatty acid salts (soaps). This reaction is called saponification and is illustrated below.
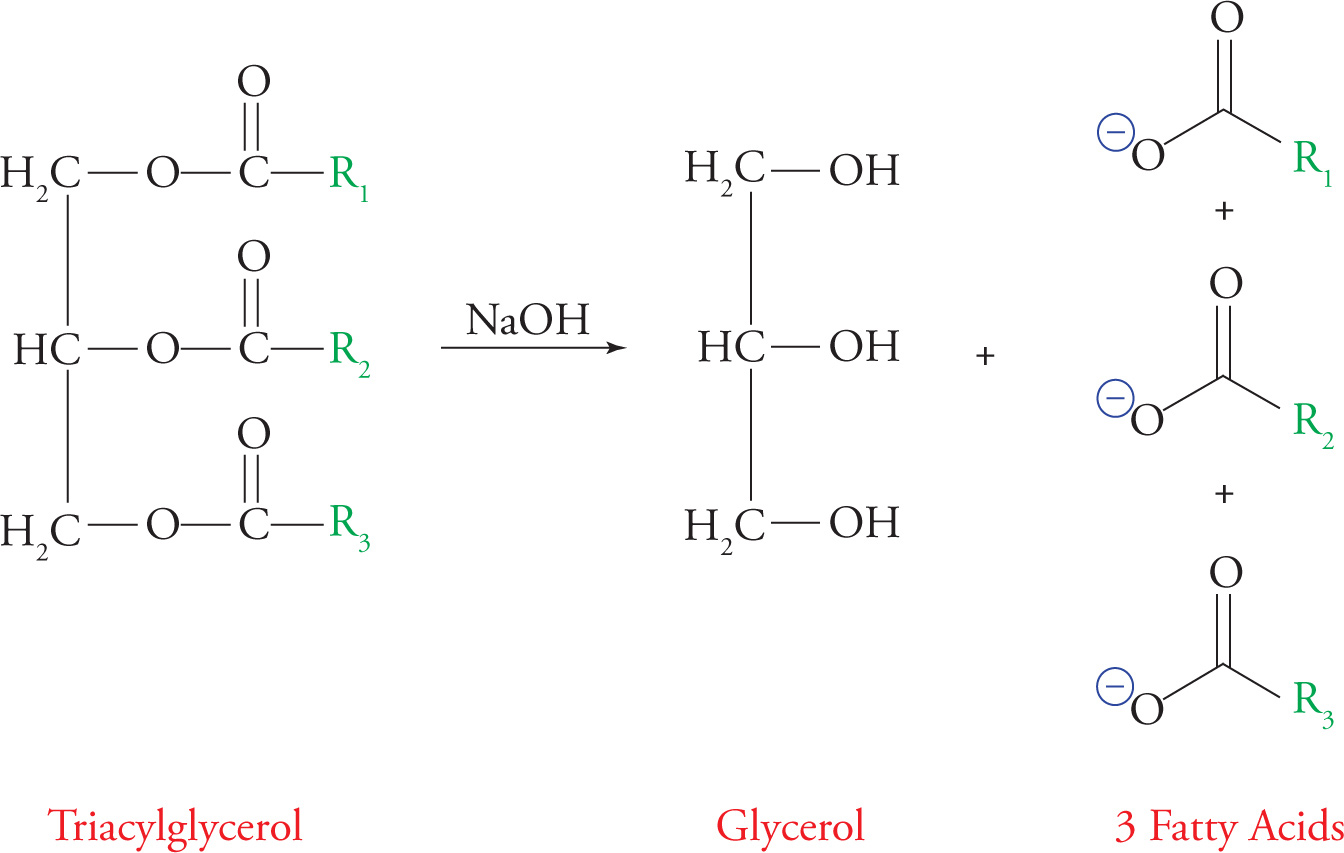
Saponification
Lipases are enzymes that hydrolyze fats. Triacylglycerols are stored in fat cells as an energy source. Fats are more efficient energy storage molecules than carbohydrates for two reasons: packing and energy content.
Packing: Their hydrophobicity allows fats to pack together much more closely than carbohydrates. Carbohydrates carry a great amount of water-of-solvation (water molecules hydrogen bonded to their hydroxyl groups). In other words, the amount of carbon per unit area or unit weight is much greater in a fat droplet than in dissolved sugar. If we could store sugars in a dry powdery form in our bodies, this problem would be obviated.
Energy content: All packing considerations aside, fat molecules store much more energy than carbohydrates. In other words, regardless of what you dissolve it in, a fat has more energy carbon-for-carbon than a carbohydrate. The reason is that fats are much more reduced. Remember that energy metabolism begins with the oxidation of foodstuffs to release energy. Since carbohydrates are more oxidized to start with, oxidizing them releases less energy. Animals use fat to store most of their energy, storing only a small amount as carbohydrates (glycogen). Plants such as potatoes commonly store a large percentage of their energy as carbohydrates (starch).
Introduction to Lipid Bilayer Membranes
Membrane lipids are phospholipids derived from diacylglycerol phosphate or DG-P. For example, phosphatidyl choline is a phospholipid formed by the esterification of a choline molecule [HO(CH2)2N+(CH3)3] to the phosphate group of DG-P. Phospholipids are detergents, substances that efficiently solubilize oils while remaining highly water-soluble. Detergents are like soaps, but stronger.
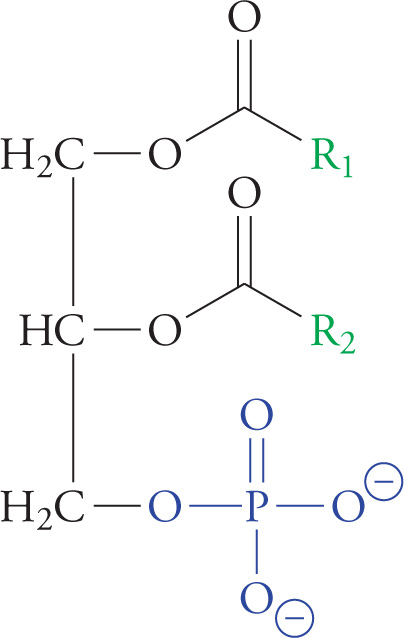
A Phosphoglyceride (Diacylglycerol Phosphate, or DGP)
We saw previously how fatty acids spontaneously form micelles. Phospholipids also minimize their interactions with water by forming an orderly structure—in this case, it is a lipid bilayer (below). Hydrophobic interactions drive the formation of the bilayer, and once formed, it is stabilized by van der Waals forces between the long tails.
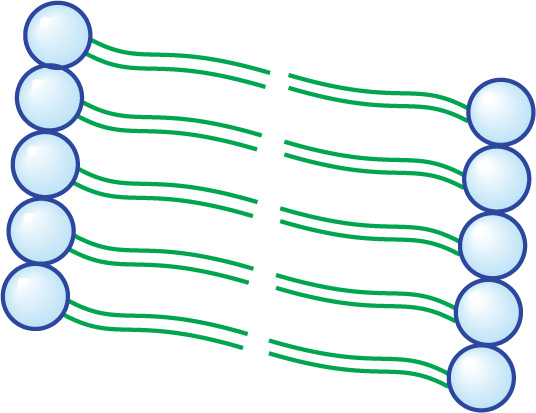
A Small Section of a Lipid Bilayer Membrane
55) Would a saturated or an unsaturated fatty acid residue have more van der Waals interactions with neighboring alkyl chains in a bilayer membrane?55
A more precise way to give the answer to the question above is to say that double bonds (unsaturation) in phospholipid fatty acids tend to increase membrane fluidity. Unsaturation prevents the membrane from solidifying by disrupting the orderly packing of the hydrophobic lipid tails. This decreases the melting point. The right amount of fluidity is essential for function. Decreasing the length of fatty acid tails also increases fluidity. The steroid cholesterol (discussed a bit later) is a third important modulator of membrane fluidity. At low temperatures, it increases fluidity in the same way as kinks in fatty acid tails; hence, it is known as membrane antifreeze. At high temperatures, however, cholesterol attenuates (reduces) membrane fluidity. Don’t ponder this paradox too long; just remember that cholesterol keeps fluidity at an optimum level. Remember, the structural determinants of membrane fluidity are: degree of saturation, tail length, and amount of cholesterol.
The lipid bilayer acts like a plastic bag surrounding the cell in the sense that it seals the interior of the cell from the exterior. However, the cell membrane is much more complex than a plastic bag. Since the plasma bilayer membrane surrounding cells is impermeable to charged particles such as Na+, protein gateways such as ion channels are required for ions to enter or exit cells. Proteins that are integrated into membranes also transmit signals from the outside of the cell into the interior. For example, certain hormones (peptides) cannot pass through the cell membrane due to their charged nature; instead, protein receptors in the cell membrane bind these hormones and transmit a signal into the cell in a second messenger cascade.
Terpenes
A terpene is a member of a broad class of compounds built from isoprene units (C5H8) with a general formula (C5H8)n.
Terpenes may be linear or cyclic, and are classified by the number of isoprene units they contain. For example, monoterpenes consist of two isoprene units, sesquiterpenes consist of three, and diterpenes contain four.
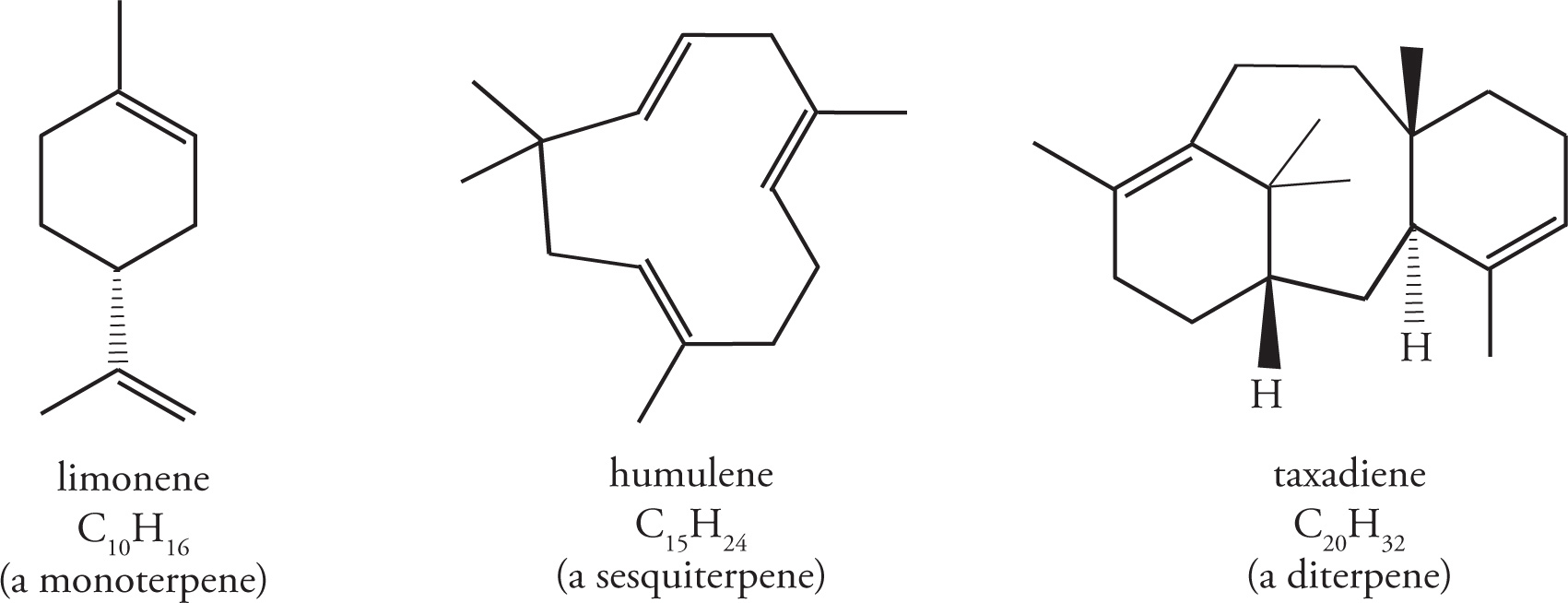
Squalene is a triterpene (made of six isoprene units), and is a particularly important compound as it is biosynthetically utilized in the manufacture of steroids.
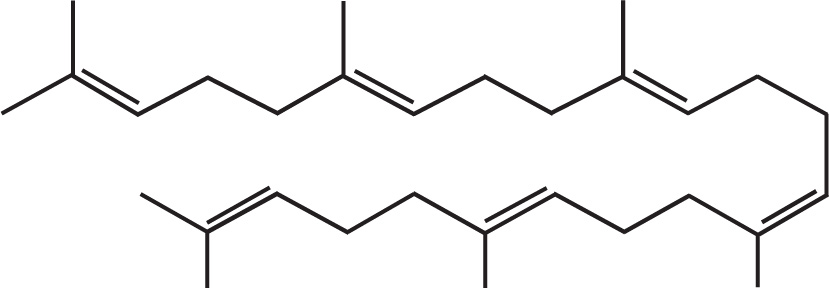
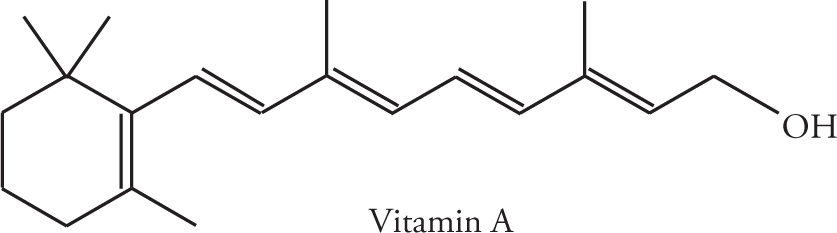
Whereas a terpene is formally a simple hydrocarbon, there are a number of natural and synthetically derived species that are built from an isoprene skeleton and functionalized with other elements (O, N, S, etc.). These functionalized-terpenes are known as terpenoids. Vitamin A (C20H30O) is an example of a terpenoid.
Steroids
Steroids are included here because of their hydrophobicity, and, hence, similarity to fats. Their structure is otherwise unique. All steroids have the basic tetracyclic ring system (see below), based on the structure of cholesterol, a polycyclic amphipath. (Polycyclic means several rings, and amphipathic means displaying both hydrophilic and hydrophobic characteristics.)
As discussed above, the steroid cholesterol is an important component of the lipid bilayer. It is obtained from the diet and synthesized in the liver. It is carried in the blood packaged with fats and proteins into lipoproteins. One type of lipoprotein has been implicated as the cause of atherosclerotic vascular disease, which refers to the build-up of cholesterol “plaques” on the inside of blood vessels.
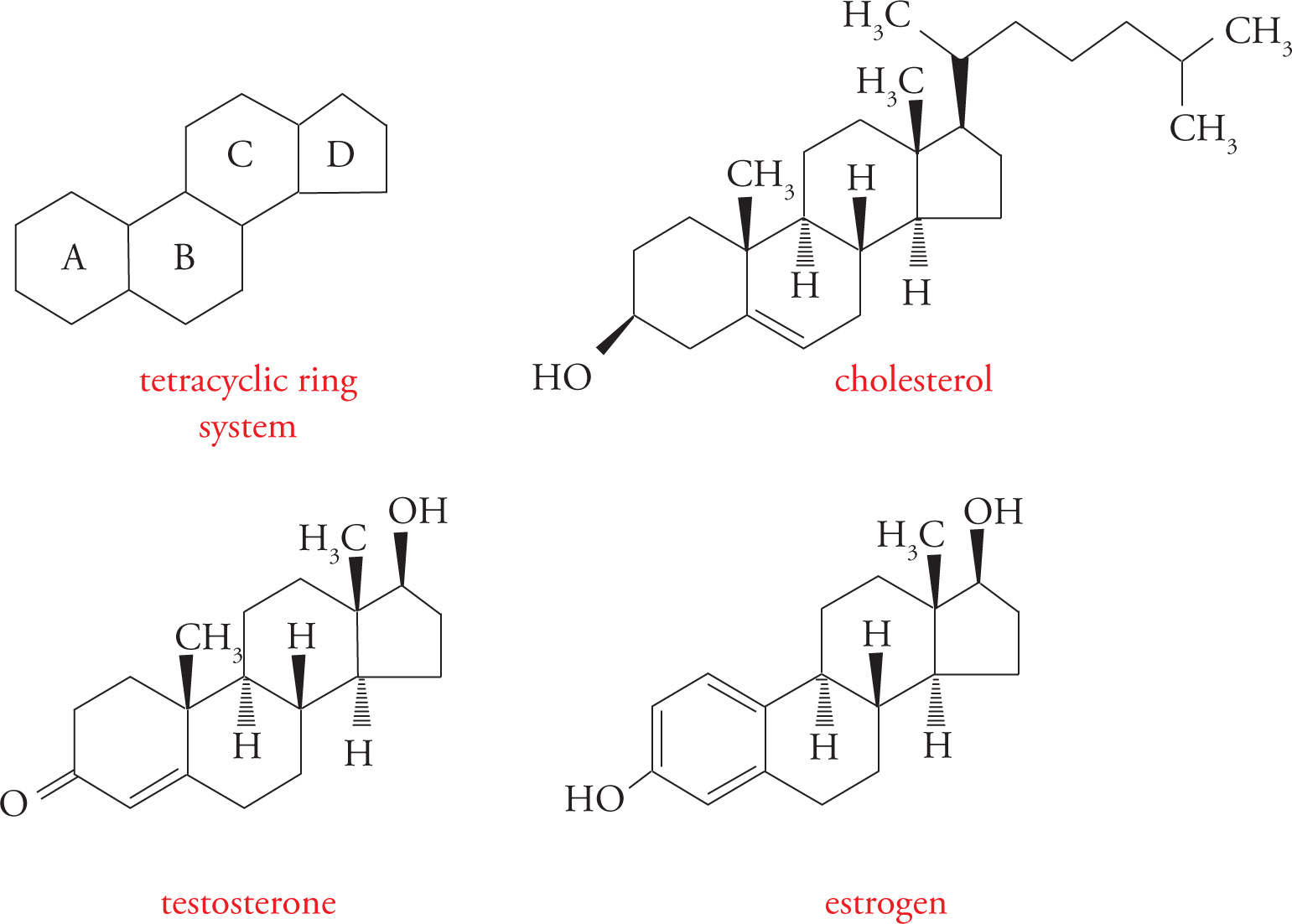
Cholesterol-Derived Hormones
Steroid hormones are made from cholesterol. Two examples are testosterone (an androgen or male sex hormone) and estradiol (an estrogen or female sex hormone). There are no receptors for steroid hormones on the surface of cells. If this is true, how can they exert an influence on the cell? Because steroids are highly hydrophobic, they can diffuse right through the lipid bilayer membrane into the cytoplasm. The receptors for steroid hormones are located within cells rather than on the cell surface. This is an important point! You must be aware of the contrast between peptide hormones, such as insulin, which exert their effects by binding to receptors at the cell-surface, and steroid hormones, such as estrogen, which diffuse into cells to find their receptors.
7.5 NUCLEIC ACIDS
Before we can talk about nucleic acids, we must first briefly review some background.
Phosphorus-Containing Compounds
Phosphoric acid is an inorganic acid (it does not contain carbon) with the potential to donate three protons. The Kas for the three acid dissociation equilibria are 2.1, 7.2, and 12.4. Therefore, at physiological pH, phosphoric acid is significantly dissociated, existing largely in anionic form.

Phosphoric Acid Dissociation
Phosphate is also known as orthophosphate. Two orthophosphates bound together via an anhydride linkage form pyrophosphate. The P—O—P bond in pyrophosphate is an example of a high-energy phosphate bond. This name is derived from the fact that the hydrolysis of pyrophosphate is thermodynamically extremely favorable (shown on the next page). The ∆G° for the hydrolysis of pyrophosphate is about −7 kcal/mol. This means that it is a very favorable reaction. The actual ∆G° in the cell is about −12 kcal/mol, which is even more favorable.
There are three reasons that phosphate anhydride bonds store so much energy:
1. When phosphates are linked together, their negative charges repel each other strongly.
2. Orthophosphate has more resonance forms and thus a lower free energy than linked phosphates.
3. Orthophosphate has a more favorable interaction with the biological solvent (water) than linked phosphates.
The details are not crucial. What is essential is that you fix the image in your mind of linked phosphates acting like compressed springs, just waiting to fly open and provide energy for an enzyme to catalyze a reaction.
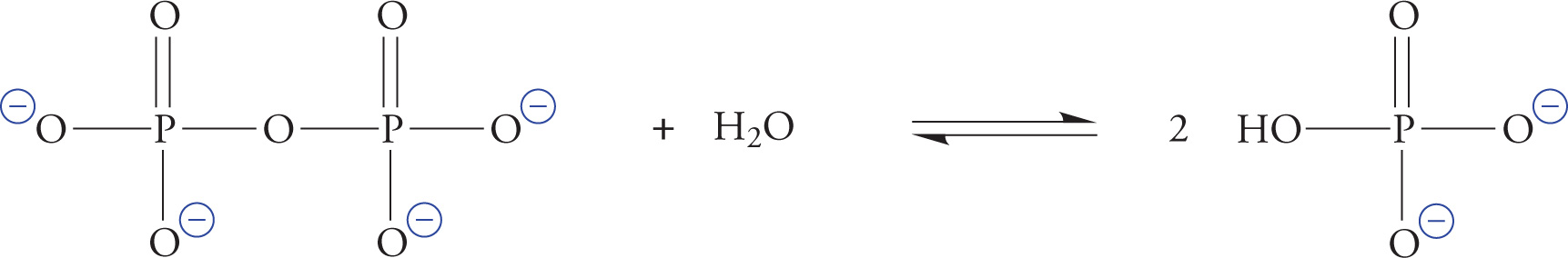
The Hydrolysis of Pyrophosphate
Nucleotides
Nucleotides are the building blocks of nucleic acids (RNA and DNA). Each nucleotide contains a ribose (or deoxyribose) sugar group; a purine or pyrimidine base joined to carbon number one of the ribose ring; and one, two, or three phosphate units joined to carbon five of the ribose ring. The nucleotide adenosine triphosphate (ATP) plays a central role in cellular metabolism in addition to being an RNA precursor.
ATP is the universal short-term energy storage molecule. Energy extracted from the oxidation of foodstuffs is immediately stored in the phosphoanhydride bonds of ATP. This energy will later be used to power cellular processes; it may also be used to synthesize glucose or fats, which are longer-term energy storage molecules. This applies to all living organisms, from bacteria to humans. Even some viruses carry ATP with them outside the host cell, though viruses cannot make their own ATP.
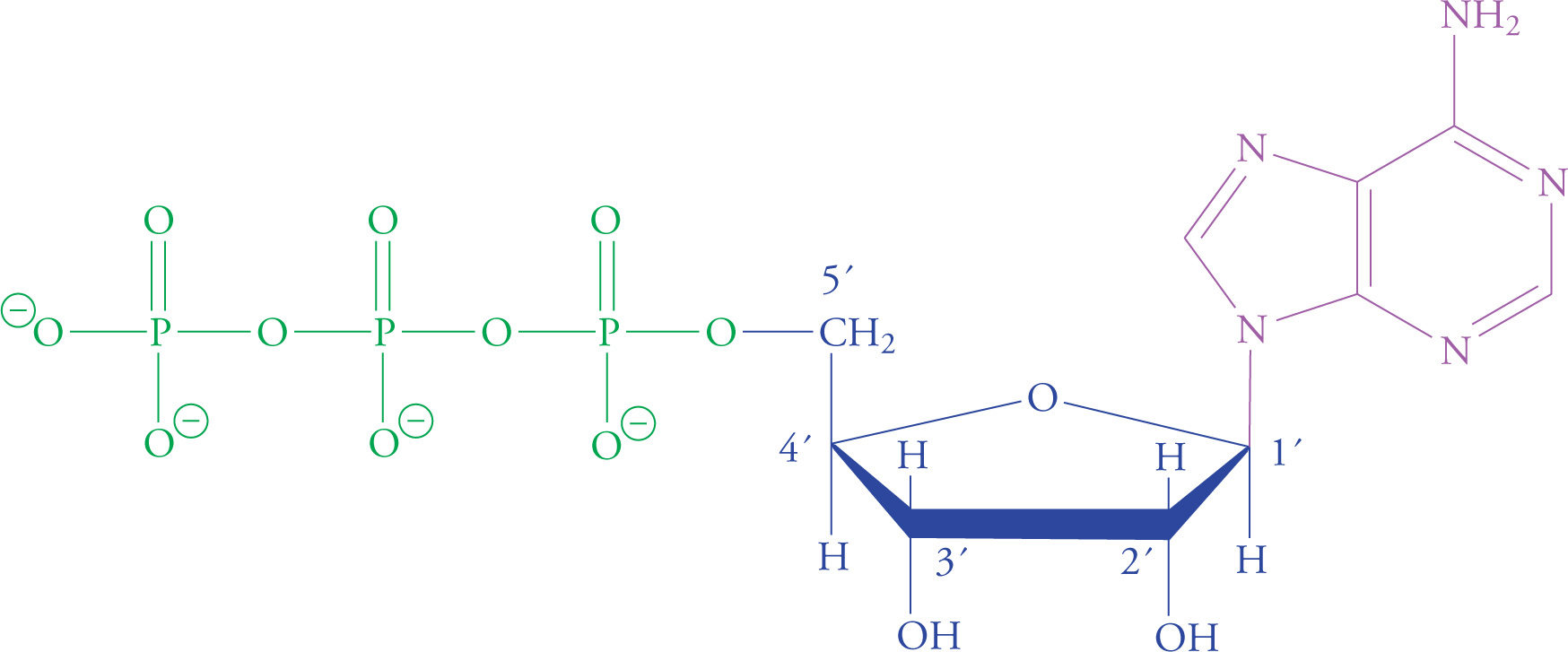
Adenosine Triphosphate (ATP)
Chapter 7 Summary
• Amino acids (AAs) consist of a tetrahedral α-carbon connected to an amino group, a carboxyl group, and a variable R group, which determines the AA’s properties.
• The isoelectric point of an AA is the pH at which the net charge on the molecule is zero; this structure is referred to as the zwitterion.
• Electrophoresis separates mixtures of AAs and is conducted at buffered pH. Positively charged AAs move to the “−” end of the gel, and negative AAs move to the “+” end. Zwitterions will not move.
• Proteins consist of amino acids linked by peptide bonds, or amide bonds, which have partial double bond characteristics, lack rotation and are very stable.
• The secondary structure of proteins (α-helices and β-sheets) is formed through hydrogen bonding interactions between atoms in the backbone of the molecule.
• The most stable tertiary protein structure generally places polar AAs on the exterior and nonpolar AAs on the interior of the protein. This minimizes interactions between nonpolar AAs and water, while optimizing interactions between side chains inside the protein.
• All animal amino acids are L-configuration and all animal sugars are D-configuration.
• Carbohydrates are chains of hydrated carbon atoms with the molecular formula CnH2nOn.
• Sugars in solution exist in equilibrium between the straight chain form and either the furanose (five-atom) or pyranose (six-atom) cyclic forms.
• The anomeric forms of a sugar differ by the position of the OH group on the anomeric carbon; OH down = α, OH up = β.
• All monosaccharides will give a positive result in a Benedict’s test because they contain an aldehyde, ketone or hemiacetal, and are therefore reducing sugars.
• The glycosidic linkage in a disaccharide is named based on which anomer is present for the sugar containing the acetal and the numbers of the carbons linked to the bridging O.
• Saponification (base-mediated hydrolysis) of a triglyceride produces three equivalents of fatty acid carboxylates. These amphipathic molecules form micelles in solution.
• Lipids are found in several forms in the body, including triglycerides, phospholipids, cholesterol and steroids.
• The building blocks of nucleic acids (DNA and RNA) are nucleotides, which are comprised of a pentose sugar, a purine or pyrimidine base, and 2-3 phosphate units.
CHAPTER 7 FREESTANDING PRACTICE QUESTIONS
1. Which of the following best explains the strength of the peptide bond in a protein?
A) The steric bulk of the R groups prevents nucleophilic attack at the carbonyl carbon.
B) The electron pair on the nitrogen atom is delocalized by orbital overlap with the carbonyl group.
C) Peptide bonds are never exposed to the exterior of a protein.
D) The peptide bond is resistant to hydrolysis by many biological molecules.
2. Why is ATP known as a “high energy” structure at neutral pH?
A) It exhibits a large decrease in free energy when it undergoes hydrolytic reactions.
B) The phosphate ion released from ATP hydrolysis is very reactive.
C) It causes cellular processes to proceed at faster rates.
D) Adenine is the best energy storage molecule of all the nitrogenous bases.
3. Which of the following best describes the secondary structure of a protein?
A) Various folded polypeptide chains joining together to form a larger unit
B) The amino acid sequence of the chain
C) The polypeptide chain folding upon itself due to hydrophobic/hydrophilic interactions
D) Peptide bonds hydrogen-bonding to one another to create a sheet-like structure
4. Which of the following fatty acids has the highest melting point?
A) 4,5-Dimethylhexanoic acid
B) Octanoic acid
C) 2,3-Dimethylbutanoic acid
D) Hexanoic acid
5. Which of the following terms best describes the interconversion between α-D-glucose and β-D-glucose?
A) Tautomerism
B) Nucleophilic addition
C) Mutarotation
D) Elimination
6. A dipeptide is synthesized with the sequence Asp-Glu. The aspartic acid residue has an observed pKa of 2.10 for its side chain. In free glutamic acid, the side chain has an expected pKa of 2.15. However, in this dipeptide, it is likely that the observed pKa of the glutamic acid side chain will be:
A) higher due to a favorable ionic interaction between the deprotonated side chains.
B) lower due to a favorable ionic interaction between the deprotonated side chains.
C) higher due to an unfavorable ionic interaction between the deprotonated side chains.
D) lower due to an unfavorable ionic interaction between the deprotonated side chains.
7. In the dipeptide shown below, all of the labeled dihedral angles may freely rotate EXCEPT:
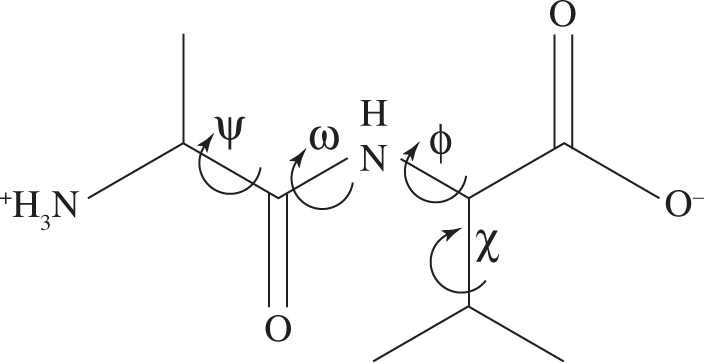
A) ω
B) ψ
C) χ
D) ϕ
CHAPTER 7 PRACTICE PASSAGE
In the body, proteins are constantly being synthesized and degraded in order to maintain and modulate protein concentration and enzyme activity levels. In eukaryotic cells, a 76-residue protein called ubiquitin is used as a tag to label proteins destined for degradation.
Ubiquitin forms an amide bond between its glycine residue at position 76 and the side chain of a lysine residue of the target protein. Three enzymes are required in the attachment of ubiquitin to the target protein. The steps of ubiquitination at pH 7 are shown in Figure 1. The first step is coupled to ATP hydrolysis.
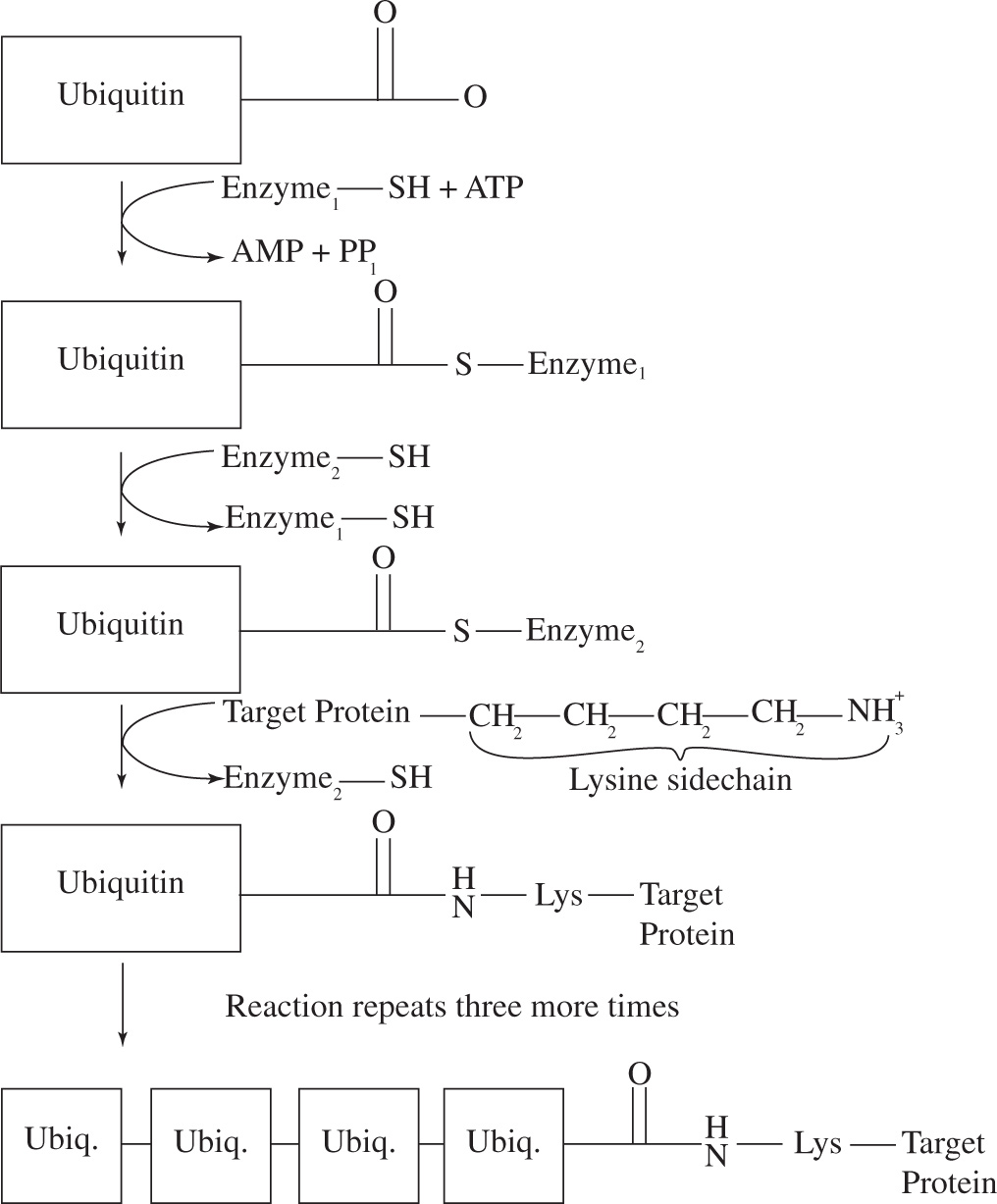
Figure 1 Ubiquitination
(Adapted from Stryer, Biochemistry, 3rd edition)
First, a single ubiquitin is attached to the target protein via the reaction shown in Figure 1. Subsequently, a second ubiquitin is attached to a lysine residue of the first ubiquitin, a third ubiquitin is attached to a lysine residue of the second ubiquitin, and so on, until a chain consisting of four ubiquitin monomers is attached to the target protein (Figure 1). The ubiquitinated protein is then sent to the proteosome where it is degraded into single amino acids. In the proteosome, threonine proteases cleave solvent-exposed peptide bonds using a threonine active site residue. A representative cleavage of a diglycine peptide at pH 7 is shown in Figure 2.
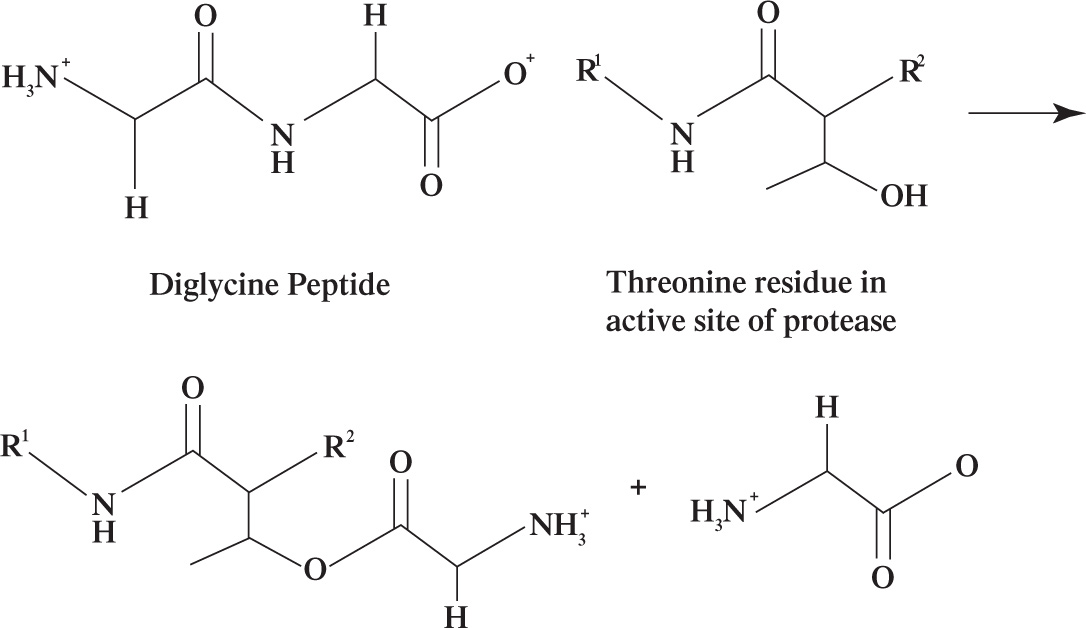
Figure 2 Threonine-dependent peptide hydrolysis
1. The amide bond between ubiquitin and its target protein is formed between the side chain of a lysine residue and the:
A) C-terminus of glycine 76.
B) N-terminus of glycine 76.
C) side chain of glycine 76.
D) α-carbon of glycine 76.
2. In Step 2 of ubiquitination, the ubiquitin is transferred from Enzyme1 to Enzyme2. This reaction is most accurately described as:
A) nucleophilic substitution.
B) transesterification.
C) trans(thio)esterification.
D) nucleophilic addition.
3. In the absence of ATP, the ubiquitination reaction would:
A) occur more slowly than in the presence of ATP.
B) occur more quickly than in the presence of ATP.
C) not be affected.
D) not occur.
4. Compared to lysine, the isoelectric point (pI) of glycine
A) is lower.
B) is higher.
C) is the same.
D) cannot be determined without more information.
5. In the threonine-dependent hydrolysis of proteins, the primary function of the threonine residue is to act as a(n):
A) acid.
B) base.
C) nucleophile.
D) electrophile.
6. Which of the following techniques would be most effective in separating lysine from a mixture of lysine, glycine, and threonine in aqueous buffer at pH 7?
A) Extraction
B) Gel electrophoresis
C) Column chromatography
D) Distillation
SOLUTIONS TO CHAPTER 7 FREESTANDING PRACTICE QUESTIONS
1. B Because the peptide bond is delocalized, the C—N bond has double-bond character and is difficult to break. Choice A can be eliminated because steric hindrance describes the electron density surrounding an atom, not the density associated with bonds. Choice C can be eliminated because the folding of a peptide within a protein does not affect bond strength. Choice D can be eliminated because proteins are susceptible to hydrolysis from enzymes.
2. A Choice A is the best because it directly addresses the energetics of ATP hydrolysis. Choice B discusses the reactivity of the released phosphate ion and not the structure of ATP itself, so it can be eliminated. Choice C can be eliminated because it describes the rate of cellular processes not the energy of ATP. Choice D can be eliminated because the structure of adenine is not related to why ATP is a good energy storage molecule.
3. D The secondary structure of proteins is the initial folding of the polypeptide chain into α-helices or β-pleated sheets. Choice A describes the formation of a quaternary protein, choice B can be eliminated because it describes the primary protein structure, and choice C can be eliminated because it describes the tertiary protein structure.
4. B Two points to consider in the melting point of fatty acids are 1) molecular weight, and 2) branching. Choices A and B both consist of eight carbons, while choices C and D each have six. Thus, it is likely that choice A or B will be the better choice based on molecular weight. Since choice A is branched and choice B is not, choice A has the lower melting point. Although all four structures may be drawn to answer this question, it is not necessary. The carbons can be counted based on the names (2 methyl = 2 carbons + hexan = 6 carbons or but = 4 carbons), and the methyl substituents are indicative of branching in choices A and C.
5. C The interconversion between α and β anomers of the same sugar is known as mutarotation. Although the mechanism of mutarotation involves both elimination, then nucleophilic addition, individually each of these two answers is incomplete (eliminate choices B and D). Tautomerism describes the equilibration between structural isomers (eliminate choice A), not anomers, which are stereoisomers.
6. C This problem can be approached as a two-by-two. First, consider that when aspartic acid and glutamic acid are deprotonated, they go from having neutral side chains to having a negative charge. Repulsion between these two negative charges creates an unfavorable ionic interaction (eliminate choices A and B). If the side chain of glutamic acid has a higher observed pKa, the repulsion can be avoided somewhat since the group will be deprotonated only at higher pH, and therefore a narrower range of conditions (eliminate choice D).
7. A Since the peptide bond has partial double bond character, it cannot freely rotate. The peptide bond is labeled as ω, making choice A the correct answer. The rest of the labeled dihedral angles are all single bonds, and therefore can freely rotate.
SOLUTIONS TO CHAPTER 7 PRACTICE PASSAGE
1. A Since proteins are written from N-terminus to C-terminus, glycine 76 is the C-terminal residue with the free carbonyl shown (eliminate choice B). Glycine does not have a side chain (its R group attached to the α-carbon is a single H) so choice C can be eliminated. The α-carbon of an amino acid is next to the carbonyl, not the carbonyl carbon itself, so choice D can be eliminated.
2. C At the beginning of Step 2, the ubiquitin is linked to Enzyme1 through a thioester bond, not a simple ester, due to the presence of sulfur in the molecule. At the end of the reaction it emerges linked to Enzyme2 through a new thioester bond. Transesterification and trans(thio)esterification involve the exchange of one alcohol or thiol group, respectively, on one ester compound for another. Therefore, this reaction is best described as a trans(thio)esterification (eliminate choice B). Substitution is a tempting answer since one enzyme has been replaced by another, maintaining the same number of sigma bonds from reactant to product. However, since the interconversion of carboxylic acid derivatives occurs through an addition-elimination mechanism, choice C is a more specific answer, and choice A can be eliminated. Choice D can be eliminated since it only describes part of the mechanism.
3. D ATP coupling is used to drive thermodynamically unfavorable reactions that would otherwise be nonspontaneous. Therefore, in the absence of ATP this reaction would not occur. Choices A and B imply that the kinetics of the reaction would change, not the thermodynamics, and can therefore be eliminated.
4. A The isoelectric point (pI) of an amino acid is the pH at which it has an overall neutral charge. Differences in pI between the amino acids are due to differences in the side chains, since all amino acids have both an amino and carboxyl group that behave similarly in terms of their protonation states. In the passage, the side chain of lysine at pH 7 is shown in Figure 1; it is protonated and carries a positive charge. The side chain of glycine, a hydrogen, is shown in Figure 2, carries a neutral charge. Since the side chains are different and have different overall charges at pH 7, their pIs are not the same, and choice C can be eliminated. Since the side chain of lysine is still charged at pH 7, in order to deprotonate this side chain so that the overall amino acid carries a neutral charge, the pH must be raised. Therefore, the pH at which glycine carries an overall neutral charge is lower than the pH at which lysine carries an overall neutral charge, so the pI of glycine is lower than that of lysine.
5. C The hydroxyl group on the threonine side chain carries two lone pairs and can act as a nucleophile. Reaction 2 shows that this hydroxyl group attacks the electrophilic carbonyl carbon of the peptide bond, further implicating threonine as a nucleophile. While there is some proton transfer in this reaction, the main function of threonine is not to act as an acid or base (eliminate choices A and B), but to cause the cleavage of the peptide bond via nucleophilic addition-elimination.
6. B The major physical difference between lysine and the other two amino acids at pH 7 is that lysine carries an overall positive charge, as shown in Figures 1 (lysine side chain) and 2 (threonine and glycine). Gel electrophoresis separates molecules with different charges, and therefore would be the best choice for the separation. Extraction would not be effective since all of the species are charged and soluble in aqueous solution at pH 7 (eliminate choice A). Silica gel is a polar substance that would strongly attract all of the amino acids, therefore it would be very difficult to separate them using silica-based chromatography (eliminate choice C). The high molecular weight of the amino acids and ionic interactions between them will cause them to have a high vaporization point, making them nearly impossible to distill (eliminate choice D).
1 No. Enzyme activity depends on three-dimensional shape, and all animal digestive enzymes have active sites specific for substrate carbohydrates with the D configuration.
2 Choice C is correct: In the equilibrium shown, HA can either act as an acid by donating a proton (choice B is wrong) or as a base by accepting a proton (choice A is wrong). Remember also that equilibrium is not a fixed state; in other words, HA is not doomed to stay HA forever, it can move forward and back between the states shown (choice D is wrong).
3 Remember that a larger pH implies fewer extra protons, since pH = −log[H+]. A pH of 7.4 describes a solution with slightly fewer extra free protons, i.e., a slightly less acidic (more basic) solution, relative to a pH 7.0 solution.
4 Simply use the formula for pH. Pure water has a pH of −log (10−7) = 7.
5 The solution will have a proton concentration equal to 0.1 or 10−1 M. The pH of a solution with [H+] = 10−1 M is determined by the formula for pH: pH = −log(10−1 M) = 1.
6 First, substitute into the equation: 4.7 = 4.7 + log [CH3COO−]/[CH3COOH]. Then, solve:
0 = log [CH3COO−]/[CH3COOH].
What has a log of 0? In other words, ten to the power of 0 is equal to what?
100 = [CH3COO−]/[CH3COOH] = 1.0
So when the pH = pKa, the ratio of base to acid is 1 to 1. That’s a fact worth memorizing.
7 A higher pKa means that a higher proportion of the protonated form is present relative to the unprotonated form, according to the H-H equation. High pKa indicates a weak acid. Acids with low pKas, tend to deprotonate more easily. Therefore, ammonium groups have a stronger tendency to keep their protons and carboxyl groups will donate protons at the lowest pH (highest [H+]).
8 The pH is less than the pKa here, so protonation wins over dissociation, and the group will be protonated. The correct answer is −COOH.
9 The pH is much lower than the pKa for the ammonium group, so the amino group is protonated: NH3+.
10 Since pH 12 represents a very low [H+], both groups will become deprotonated (COO− and NH2), creating a net charge of −1 per glycine molecule.
11 The carboxyl group will be deprotonated (COO−) with a charge of −1 and the amino group will be protonated (NH3+) with a charge of +1, creating a net charge of 0 per glycine molecule.
12 To calculate the pI, just average the pKas of the two functional groups: (9.60 + 2.34)/2 = 5.97, or roughly 6.
13 At this pH level, glycine has a net charge of zero. Hence, it will not move in an electric field.
14 The amino group will be protonated (−NH3+), and both carboxyl groups deprotonated (−COO−), producing an average charge per aspartic acid molecule of −1. Thus, aspartic acid will migrate toward the oppositely charged (+) pole at pH 7.4.
15 Both carboxyl groups would be protonated and uncharged (−COOH), and the amino group would be protonated and charged (−NH3+). The net charge is +1, so aspartic acid would migrate toward the (−) pole.
16 Glu is incorrect, since this amino acid is charged at a pH of 7. Of the three remaining, phenylalanine has the largest hydrophobic group, and is therefore the most likely to be found on the interior of a protein. The answer is C.
17 Leucine, alanine, and isoleucine are all hydrophobic residues more likely to be found on the interior than the exterior of proteins. Serine (choice C), which has a hydroxyl group that can hydrogen bond with water, is the correct answer.
18 As stated above, the amino end is always written first. Hence, the oligopeptide begins with an exposed Phe amino group and ends with an exposed Ala carboxyl; all the other backbone groups are hitched together in peptide bonds. Out of all the R-groups, there is only one acidic or basic functional group, the acidic glutamate R-group. This R-group plus the two terminal backbone groups gives a total of three acid/base functional groups.
19 The dipeptide has a higher free energy, so its existence is less favorable. In other words, existence of the chain is less favorable than existence of the isolated amino acids.
20 During protein synthesis, stored energy is used to force peptide bonds to form. Once the bond is formed, even though its destruction is thermodynamically favorable, it remains stable because the activation energy for the hydrolysis reaction is so high. In other words, hydrolysis is thermodynamically favorable but kinetically slow.
21 No, only the peptide bond (between amino acids) is rigid due to resonance. The bonds to the α-carbon (within each amino acid) are free to rotate.
22 No. After hydrolysis all amino acids are separate and have free amino and carboxyl groups.
23 Trypsin will cleave on the carboxyl side of the Lys residue, with Phe on the N-terminus of the new Phe-Phe-Lys fragment. There will be two fragments after trypsin cleavage: Phe-Phe-Lys and Ala-Gly-Glu-Lys.
24 The sulfur in cysteine is bonded to a hydrogen and a carbon; the sulfur in cystine is bonded to a sulfur and a carbon. Hence, the sulfur in cystine is more oxidized.
25 In a reducing environment, the S-S group is reduced to two SH groups. Disulfide bridges are found only in extracellular polypeptides, where they will not be reduced. Examples of protein complexes held together by disulfide bridges include antibodies and the hormone insulin.
26 It would be antiparallel because one participant in the β-pleated sheet would have a C to N direction, while the other would be running N to C.
27 Putting a protein in a urea solution will disrupt H-bonding, thus disrupting secondary structure by unfolding α-helices and β-sheets. It would not affect primary structure, which depends on the much more stable peptide bond. Disruption of 2°, 3°, or 4° structure without breaking peptide bonds is denaturation.
28 The disulfide bridges would be broken. Tertiary structure would be less stable.
29 The shape should not be disrupted if breaking disulfides is the only disturbance. It’s just that the shape would be less sturdy—like a concrete wall without the rebar.
30 No. If you allow disulfide bridges to form while the protein is still denatured, it will become locked into an abnormal shape.
31 You should end up with the correct structure. In step one, you break the reinforcing disulfide bridges. In step two, you denature the protein completely by disrupting H-bonds. In step four, you allow the H-bonds to reform; as stated in the text, normally the correct tertiary structure will form spontaneously if you leave the polypeptide alone. In step three, you reform the disulfide bridges, thus locking the structure into its correct form.
32 This is a simple question provided to clarify the classification of the disulfide bridge. Item I is a good example of 3° structure. Item II is describes 2°, not 3°, structure. Item III describes the disulfide, which is considered to be tertiary because of when it is formed, despite the fact that it is a covalent bond.
33 The protein would be turned inside out.
34 Quaternary disulfides are bonds that form between chains that aren’t linked by peptide bonds. Tertiary disulfides are bonds that form between residues in the same polypeptide.
35 Fructose. It has six carbons, making it a hexose, and the carbonyl group is located on carbon #2, making it a ketose. Fructose is a polyhydroxy ketone, or a ketohexose.
36 Carbon #2.
37 Sugar #2 is an L sugar, since the last chiral OH is on the left (choice A is false and can be eliminated). Sugars #2 and #3 are not mirror images, so they cannot be enantiomers (choice B is false and can be eliminated). Since sugars #1 and #3 are non-superimposable images, the are enantiomers (choice D is the correct statement), and remember that epimers are never enantiomers (choice C is false and can be eliminated).
38 There are 24 aldohexoses, because there are 4 chiral carbons (#2, 3, 4, and 5). There are only 23 D-aldohexoses, because when you specify the “D” configuration, you leave only 3 variable chiral centers.
39 No, it is not possible to make a glyceraldehyde diastereomer, because the molecule has only one chiral carbon. The only stereoisomer of D-glyceraldehyde is L-glyceraldehyde, an enantiomer. You can’t make an epimer because the word “epimer” is reserved for sugars with more than one chiral center.
40 Smaller rings necessitate bond angles that are much narrower than the normal tetrahedral angle. Strained bonds are unfavorable because they are high energy.
41 They are all equatorial. This makes it a very stable molecule, and may explain why it is the most prevalent sugar in nature. It stores a lot of energy, and yet is very stable. (Key fact.)
42 The structure that forms depends on which OH attacks the carbonyl carbon (C#1). If OH4 attacks the carbonyl, the result will be a five-membered ring. If OH5 attacks, the result will be a six-membered ring. If you actually counted the structures in solution, you’d find more six-membered rings, since these are inherently more stable due to bond angles.
43 It is the one farthest from the anomeric carbon, so it is #6. It is in a five-membered ring, so it is a furanose. The anomeric OH (former carbonyl O) is up, so it’s β.
44 It is D-fructose, with three chiral carbons (four when cyclic). One way to determine that it’s a D sugar is to identify the penultimate chiral carbon, mentally open the chain, and visualize it as a Fischer structure. Another is to assign absolute configuration. D sugars have R configurations at the penultimate carbon.
45 The anomeric carbon of glucose is pointing down, which means the linkage is α-1,2. So, sucrose is Glc-α-1,2-Fru.
46 Because hydrolysis of polysaccharides is thermodynamically favored, energy input is required to drive the reaction toward polysaccharide synthesis.
47 No, because then polysaccharides would hydrolyze spontaneously (they’d be unstable). The high activation energy of polysaccharide hydrolysis allows us to use enzymes as gatekeepers—when we need energy from glucose, we open the gate of glycogen hydrolysis.
48 The anomeric carbon, which is #1 for aldoses like glucose and #2 for ketoses like fructose.
49 100% will be oxidized. In a monosaccharide, the ring form is in equilibrium with the open chain form. So when the open chain form is used up in the oxidation reaction, it will be replenished by other rings opening up (Le Châtelier’s principle).
50 Lactose (Gal-β-1-,4-Glc) is a reducing sugar. Although the attacking anomeric carbon becomes locked in an acetal, the anomeric carbon of the attacked monosaccharide is still free to mutarotate or react with Benedict’s reagent. Sucrose (Glc-α-1-,2-Fru) is not a reducing sugar, because it is made of glucose and fructose, which are both joined at their anomeric carbons. Carbon #1 of glucose is the anomeric carbon, since glucose is an aldose; carbon #2 of fructose is the anomeric carbon, since fructose is a ketose.
51 This double bond extends between carbons 7 and 8, and is cis. The bond therefore is cis-∆7.
52 An unsaturated fatty acid is bent, or “kinked,” at the cis double bond.
53 The long hydrophobic chains will interact with each other to minimize contact with water, exposing the charged carboxyl group to the aqueous environment.
54 Grease is hydrophobic. It does not wash off easily in water because it is not soluble in water. Scrubbing your hands with soap causes micelles to form around the grease particles.
55 The bent shape of the unsaturated fatty acid means that it doesn’t fit in as well and has less contact with neighboring groups to form van der Waals interactions. Unsaturation makes the membrane less stable, less solid.