Burn Math Class: And Reinvent Mathematics for Yourself (2016)
Act I
3. As If Summoned from the Void
3.4. Hammers, Patterns, and Hammer Patterns
3.4.1Where Were We?
Wow. . . Okay. . . I wasn’t expecting that. . . Where were we?
(Author flips back a few pages.)
3.4.2Where We Were
Right, let’s refresh our memory. We invented the hammer for talking about the derivative of a product in terms of the individual pieces. This hammer was the sentence (fg)′ = f′g + g′f. Then we defined the machine T(x) ≡ (xn) (x−n), which was just a fancy way of writing 1, and then we differentiated that machine in two ways.
First, we know its derivative is zero, because it’s a constant machine. Second, we differentiated it using our hammer. Having expressed the same thing in two ways, we tossed an equals sign between the two descriptions, rearranged things, and arrived at the sentence
(x−n)′ = −nx−n−1
Now, notice how similar this is to the old fact about positive powers from Chapter 2:
(xn)′ = nxn−1
In fact, we can think of them as two specific examples of a single, more general sentence. Both of them are saying, “Are you trying to find the derivative of a power machine (i.e., a machine that spits out some power of whatever you put in)? Well, just bring the old power out front, and knock down the power up top by subtracting 1 from it.”
It’s fairly surprising that things should work out so nicely. After all, we arrived at these two facts using two very different arguments. But the mathematics is now telling us that whenever # is a whole number, positive or negative, the way to differentiate x# follows the same pattern.
Oh! We’ve actually seen this pattern in one more place, though we didn’t realize it at the time. In the dialogue above — or whatever that was — Mathematics ended up demonstrating that
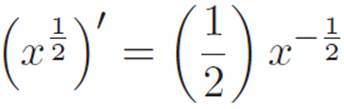
Since 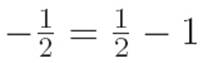 , this is exactly the same pattern as before.
, this is exactly the same pattern as before.
3.4.3Mathematical Metallurgy
You may think I have used a hammer to crack eggs, but I have cracked eggs.
—Subrahmanyan Chandrasekhar, on his habit of using lots of equations in his papers
How might we convince ourselves that this “bring down the power” pattern (x#)′ = #x#−1 continues to be true no matter what number # is? We could start by trying to hammer-away on xm/n, where m and n are any whole numbers, but we don’t really know what to do with that yet. Let’s try x1/nfirst, where n is some positive whole number. All we know about this beast at the moment is what we got from inventing it, namely:
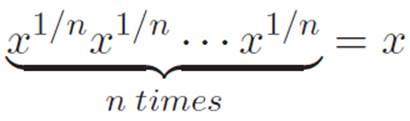
If we want to use the same type of argument we used above to figure out the derivative of x1/n, then we need to create a bigger hammer. What kind of hammer would we need? Well, we built the hammer (fg)′ = f′g + g′f for talking about the derivative of a product in terms of the individual pieces. This time, we have n things multiplied together, so it would seem that we need to make another complicated argument to figure out how to talk about the derivative of n machines multiplied together, like f1f2 . . . fn. But we may not have to reinvent the wheel. Remember that earlier we found the formula (f + g)′ = f′ + g′, and then we used this to argue that ![]() . All we had to do in order to get from the two-machines version to the n-machines version was to put on our philosopher’s hat, keep reinterpreting sums of machines as a single big machine, and then use the version for two machines over and over.
. All we had to do in order to get from the two-machines version to the n-machines version was to put on our philosopher’s hat, keep reinterpreting sums of machines as a single big machine, and then use the version for two machines over and over.
Let’s try to do that here, first looking at the simplest case we haven’t tackled yet. We’ll try to invent a hammer for computing (fgh)′, which is just three machines multiplied together. In the argument below, I’ll occasionally use [these] [kinds] [of] [brackets] instead of (these) (kinds) so that expressions like f′(gh) don’t look like “eff prime of gee aych.” The argument below is just a bunch of multiplication, and we’re simply using abbreviations like f′gh and f′[gh] to stand for f′(x)g(x)h(x). Things would be very confusing if we always used abbreviations like f′gh instead of f′(x)g(x)h(x), but at least in the argument below, these abbreviations are really helpful in avoiding clutter.
Alright! If we start by sneakily thinking of gh as a single machine, then fgh can be thought of as two machines, namely, (f) and (gh), so we can apply our hammer for two machines on these two pieces. Then we can switch hats and start thinking of gh as two machines multiplied together, and maybe we’ll start to see a pattern. But we’re not plugging these machines into each other or anything, just multiplying. Okay, let’s go. First we use the hammer for two machines, thinking of gh as one big machine. This gives:
[fgh]′ = f′[gh] + f[gh]′
The [gh]′ piece on the far right can be broken up using the hammer for two machines, which lets us write it as [gh]′ = g′h + gh′. If we pull this tricky move, we get
![]()
We can sort of see a pattern emerging. We could summarize the pattern by saying: If you’ve got n machines multiplied together, like f1f2 . . . fn, then the derivative of the whole shebang seems like it should be a bunch of pieces added together, each of which looks almost like the original, except in each piece, one and only one machine gets its turn to be “primed.” There will be as many pieces as there are individual machines, because everybody gets a turn. We could write our guess this way:
![]()
But this is fairly complicated-looking, and it’s got a lot of dot-dot-dots. How could we convince ourselves that this pattern continues being true no matter what n is? Well, here’s an idea. We know the version for two machines, and we got the version for three machines by applying the version for two machines twice. How would we get the version for four machines? Well, thinking of f2f3f4 as a single machine, we could just use the version for two machines once, like this:
![]()
But we invented the hammer for three machines earlier, so we can crack open the [f2f3f4]′ piece on the far right of the above equation to get
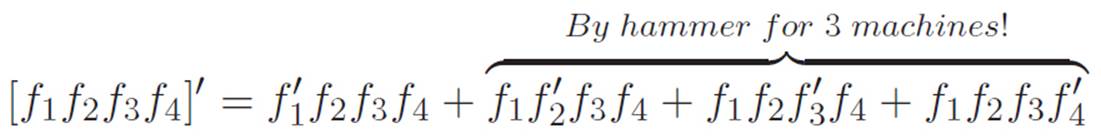
This is getting really ugly, but it’s not complicated in the least; it’s just a lot of symbols. The above equation just says “Everybody gets a turn to be primed,” using a gigantic avalanche of symbols. Moreover, there’s nothing about the reasoning process that is getting ugly. Quite the reverse. Not only has a pattern emerged in the mathematics, a pattern is emerging in our process of reasoning.
The pattern in our process of reasoning is that if we have convinced ourselves that the mathematical pattern is true5 for some number of machines multiplied together, then we can always get from that number to the next.
If it bothers you that I’m using the phrase “the pattern is true,” despite the fact that only sentences (propositions) can be true, relax please. . . But yeah, you’re right.
•We know the pattern is true for two machines multiplied together.
•If we know the pattern is true for two machines multiplied together (which we do), then we can argue that it’s true for three machines multiplied together (which we did).
•If we know the pattern is true for three machines multiplied together (which we do), then we can argue that it’s true for four machines multiplied together (which we did).
•· · ·
•If we know the pattern is true for 792 machines multiplied together, then we can argue that it’s true for 793 machines multiplied together.
•Ad infinitum.
This is the pattern that has emerged in our process of reasoning. We would like to convince ourselves that the pattern we noticed in the mathematics continues to be true for all n. However, it might seem at first like this is impossible. After all, we have an infinite bag of sentences that we want to convince ourselves of: one sentence for each number n. When n is 792, the sentence is “The pattern is true for 792 things multiplied together.”
How can we possibly convince ourselves of infinitely many sentences in a finite amount of time? Well, the pattern we observed in our process of reasoning suggests a way forward. We’ve already discovered the “everyone gets a turn” pattern in a few specific cases (two machines multiplied together, three machines, four machines). What if we made an argument, in abbreviated form, that whenever we know the pattern is true for one number of machines multiplied together, then it has to be true for the next number? Then we would automatically know that the pattern was true for every number. Let’s try to say this in abbreviated form.
Let’s imagine that we’ve already got the hammer for some specific number k. That is, we assume that the pattern is true for some specific number of machines multiplied together, and we choose to call this number k. Then we can try to use this assumption to show that the pattern has to be true for the next number k + 1. Since we’re assuming that the pattern is true for k machines, we may be able to argue that the pattern has to be true for the next number of machines k + 1, just by interpreting the first k machines as a big machine, which we’ll call g, and then applying the hammer for two machines. That is to say, let’s abbreviate g ≡ f1f2 . . . fk, and write:
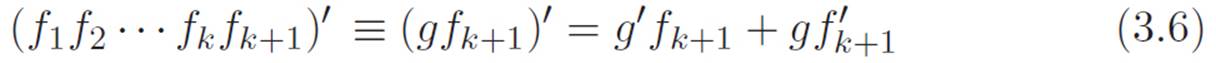
Then since we’re imagining that we already know the “everyone gets a turn” pattern is true for any k machines multiplied together, we can use that to expand the piece g′ in equation 3.6, since g was just our abbreviation for k machines multiplied together. That lets us write g′ this way:
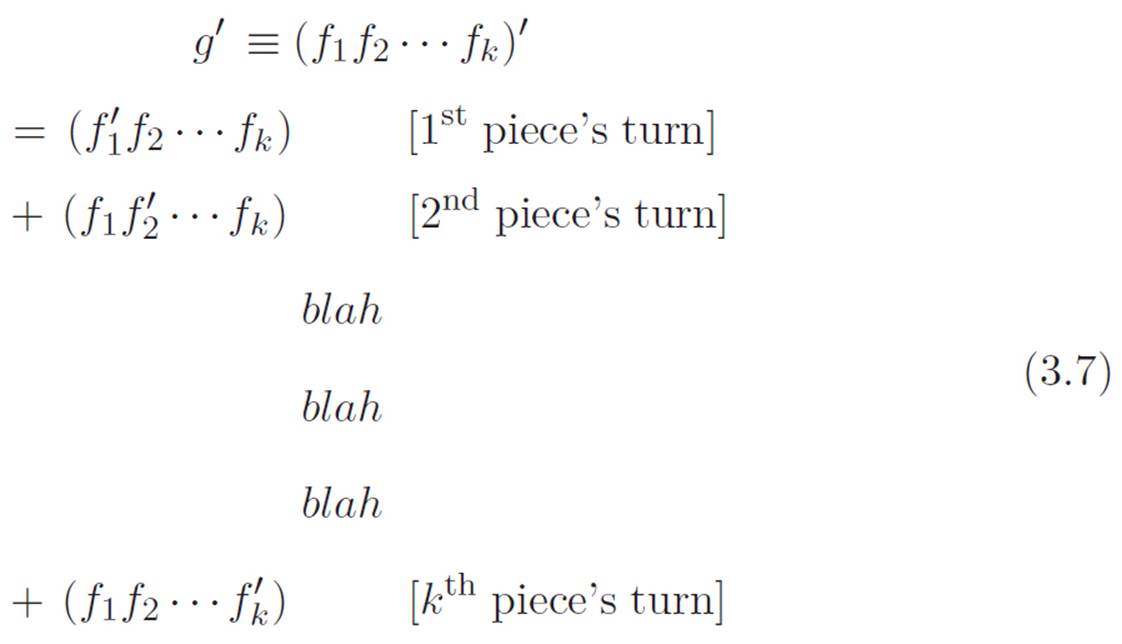
Let’s not substitute this big ugly thing into equation 3.6, but rather just imagine what we’d get if we did. In equation 3.6, the g′fk+1 piece will just be equation 3.7 if we tacked on a fk+1 to the right side of each piece. So looking back at equation 3.6, the g′fk+1 piece will be k things added together: the first piece is f1’s turn to be primed, the second piece is f2’s turn to be primed, and so on up to k. But fk+1 is sitting on the right side of all of these and never gets its turn to be primed.
Did the pattern break down? No! The piece where fk+1 gets its turn to be primed is the piece ![]() on the far right of equation 3.6. So the big mess in equation 3.6, despite its messiness, is not so messy after all, because once it is expanded using the hammer for k pieces, equation 3.6 is just k + 1 things added together, and each of the particular pieces is one individual machine’s turn to be primed. Each of the machines gets one and only one turn.
on the far right of equation 3.6. So the big mess in equation 3.6, despite its messiness, is not so messy after all, because once it is expanded using the hammer for k pieces, equation 3.6 is just k + 1 things added together, and each of the particular pieces is one individual machine’s turn to be primed. Each of the machines gets one and only one turn.
That was a weird argument, so it’s worth trying to summarize the style of reasoning we used in an abbreviated form. We wanted to convince ourselves that the “everyone gets one turn to be primed” pattern was true for any number of machines multiplied together. We can think of this as wanting to convince ourselves that infinitely many different sentences are true. Here’s what I mean: let’s use S to stand for the word “sentence,” and let’s use n to stand for some whole number. Then for each number n, there was a sentence we wanted to convince ourselves was true, which we can abbreviate:
S(n) ≡ “The ‘everyone gets a turn to be primed’ pattern for the derivative of a product is true for any n machines multiplied together.”
Our original hammer (fg)′ = f′g + g′f just says that the sentence S(2) is true. Then we showed that the pattern is true for three things multiplied together, which gave us equation 3.5. This equation was just the sentence S(3). We eventually realized that it was pointless to keep doing this, because we had infinitely many sentences we wanted to convince ourselves of. However, we noticed a pattern in our process of reasoning that let us get from any sentence S(k) to the next sentence S(k + 1). That is, we couldn’t just immediately convince ourselves all at once that S(n) was true for any n, but we could do two things:
1.We could convince ourselves that S(2) was true.
2.If we imagined that we had already convinced ourselves that the sentence S(some number) was true, then it was easy to convince ourselves that the sentence S(the next number) had to be true as well.
Although it might not be clear right away, these two things are enough to show that S(n) is true for any whole number n ≥ 2. Here’s the logic of it: say someone hands you n = 1749 and asks you to convince her that S(1749) is true. Well, rather than tackling the problem directly, which would be a gigantic pain, suppose we’ve convinced her of the two items above: S(2) is true, and the more powerful part, S(some number) always implies S(the next number). Using item 1 from the above list once, and then using item 2 over and over again, tells us the following: We believe S(2) is true. Further, if we believe S(2), we also have to believe S(3). But if we believe S(3), we also have to believe S(4). If we believe S(4). . . you get the idea.
We can get anywhere if we can convince ourselves (i) we can take the first step, and (ii) if we’ve taken some number of steps, then we can always take one more. Another way to think about this type of reasoning is by thinking of a ladder. What we showed is (i) we can get on the first rung, and (ii) no matter where we are on the ladder, we can always get to the next rung above us. If we can convince ourselves of these two things, then we know that there’s no ladder too high for us to climb.
Textbooks call this style of reasoning “mathematical induction.” Though this term is fine once we’re used to it, it’s unfortunate for several reasons. First, it’s not the best reminder of what we’re talking about, but more importantly, it can be confusing for outsiders because the word “induction” variously refers to (a) the style of mathematical argument we just made, (b) an unrelated phenomenon about electricity and magnetism, and (c) a form of probabilistic reasoning often contrasted with the “deductive” reasoning common in mathematical proofs. Despite all these unrelated meanings of induction, if you hear it used after the word “mathematical,” then they’re talking about this ladder-like process of reasoning.
3.4.4A More Powerful Hammer
Armed with our more powerful hammer:
(f1f2 · · · fn)′ = The thing where everyone gets a turn
or in more detailed language
![]()
we can now try to tackle the derivative of x1/n. Remember that we wanted to make an argument similar to the one we used to find out the derivative of x1/2. That is, we argued that we might be able to figure out the derivative of x1/n by defining a really simple machine, but writing it in a funny-looking way:
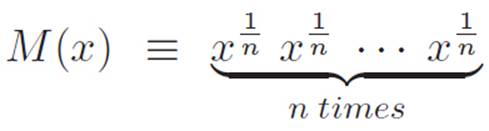
This machine is just the “most boring machine” M(x) ≡ x in disguise, the machine that just hands us back whatever we put into it. So we know that its derivative is
M′(x) = 1
However, we can now use our more powerful hammer on it. It turns out that this new hammer is much more powerful than we need for this particular problem. Since M(x) is just n copies of x1/n, when we use our new hammer on M(x), each of the pieces in equation 3.8 will be the same. That is, each of the pieces in equation 3.8 will have n − 1 copies of x1/n and one copy of (x1/n)′. Since this same thing will show up n times, we can write
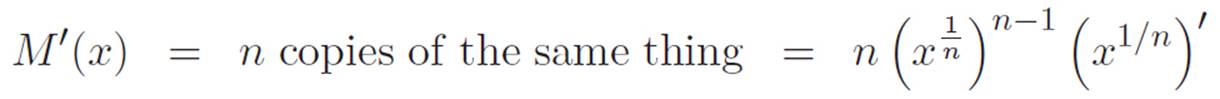
We’ve written the same thing in two ways, so let’s slap an equals sign between them, like this:
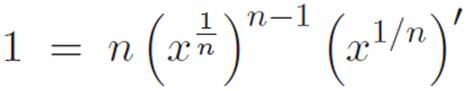
The abbreviation 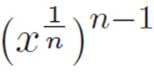 looks scary, but because of the way we invented powers, this is just xstuff, where stuff is whatever you get from adding
looks scary, but because of the way we invented powers, this is just xstuff, where stuff is whatever you get from adding ![]() to itself n − 1 times. But then stuff must just be
to itself n − 1 times. But then stuff must just be 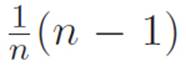 or to write the same thing in a different way,
or to write the same thing in a different way, 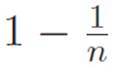 . So we can change the power to that in the equation above. Also, since we’re trying to figure out (x1/n)′, let’s throw everything that isn’t that over to the other side of the equals sign. This gives us
. So we can change the power to that in the equation above. Also, since we’re trying to figure out (x1/n)′, let’s throw everything that isn’t that over to the other side of the equals sign. This gives us

Now, at this point, we’re done, in the sense that we’ve found what we wanted. It doesn’t matter if it isn’t “simplified.” The question of what counts as “simplified” is like the question of what counts as “good” art. The question isn’t completely meaningless, but it’s also not completely meaningful, and there’s certainly no single answer. It depends on our aesthetic preferences. Simplification is a human construct, and the mathematics can’t tell the difference between a “simplified” answer and an ugly answer that says the same thing. So in that sense, we’re done.
However, personally, we’re in a little bit of suspense, because we’re not yet sure if this is the same pattern we’ve been seeing up until now. Remember that every time we’ve figured out the derivative of x to some power (so far), the derivative has been the thing we would have gotten by bringing the old power out front, and then knocking down the upstairs power by one. We found this for positive whole numbers in the sentence (xn)′ = nxn−1, we found this for negative whole numbers in the sentence (x−n)′ = (−n)x−n−1, and we even found this for a particular fractional power, when we found that 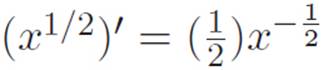 . We’re hoping that this pattern is always true, because then instead of our mathematical universe containing lots of different ugly “rules” for differentiating stuff to a power, depending on what the power is, we would only have one big wonderful rule. The thing we just discovered in equation 3.9 might be saying something like this, and it might not. The way it’s written, we can’t tell.
. We’re hoping that this pattern is always true, because then instead of our mathematical universe containing lots of different ugly “rules” for differentiating stuff to a power, depending on what the power is, we would only have one big wonderful rule. The thing we just discovered in equation 3.9 might be saying something like this, and it might not. The way it’s written, we can’t tell.
So even though “simplification” is a human construct that has nothing to do with mathematics, and even though any educational authority figure who takes off points for a correct but “non-simplified” answer is just teaching you about their own preferences, we personally would like to write equation 3.9 differently, so that we can get an idea of how unified our mathematical universe is. Whether you want to call this “simplifying” or not is irrelevant. What we want to do is to write equation 3.9 in a way that makes it clear to us whether the pattern we’ve been seeing up until now is still true, or whether it has broken down. How can we squish equation 3.9 into this form? Well, when we invented powers, we found out that 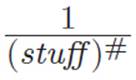 can be written as (stuff)−#. So looking back at the equation we just discovered, equation 3.9, we can bring some stuff from the bottom to the top by noticing that
can be written as (stuff)−#. So looking back at the equation we just discovered, equation 3.9, we can bring some stuff from the bottom to the top by noticing that ![]() . Also, division by n is really just multiplication by
. Also, division by n is really just multiplication by ![]() . So we can rephrase equation 3.9 by writing
. So we can rephrase equation 3.9 by writing

Perfect! There’s that pattern again. There’s no way this keeps appearing by accident. It would be nice to finish off this mystery once and for all. At this point, we would bet a lot that (x#)′ = #x#−1 no matter what number # is. We don’t know whether any number can be written in the form ![]() , where m and n are whole numbers, but we can convince ourselves that any number # can be approximated as close as we want by something that looks like
, where m and n are whole numbers, but we can convince ourselves that any number # can be approximated as close as we want by something that looks like ![]() . How? Like this: suppose someone hands you an annyong6 number like
. How? Like this: suppose someone hands you an annyong6 number like
This was supposed to have been the word “annoying,” but for reasons that will be clear to anyone who knows a little Korean (or knows a bit of Hangul, arguably the most elegant writing system on the planet)(or who has seen the show Arrested Development), this typo was too good to correct. As a side note, this also happens to be an example of the principle that has created all life on this planet: the principle of natural selection. Although the vast majority of mutations (typos) are deleterious (meaningless), rarely a mutation (typo) arises that contains useful information (meaning) not present in the original (e.g., annoying → annyong), such as the ability to make a protein with a shape sufficiently different from the original that it can perform a different job. Speaking of typos and natural selection, it’s worth relating a similar story about what was perhaps the greatest typo in the history of literature. In the course of writing his book The Greatest Show on Earth, Richard Dawkins was writing a passage about the Large Hadron Collider, which he accidentally misspelled as the Large Hardon Collider. He describes the incident as follows: “I spotted the misprint and of course I left it in! But alas, the publisher’s proofreader also spotted it, and she removed it. I begged her on my knees to leave it in. She said it was more than her job was worth.”
# = 8.34567840987238654 . . .
which is a number I made just now by banging on my keyboard, and let’s imagine that I say “approximate this number to ten decimal places using something that looks like ![]() , where m and n are two whole numbers.” You don’t need any fancy mathematics to do this. You can simply do the following:
, where m and n are two whole numbers.” You don’t need any fancy mathematics to do this. You can simply do the following:
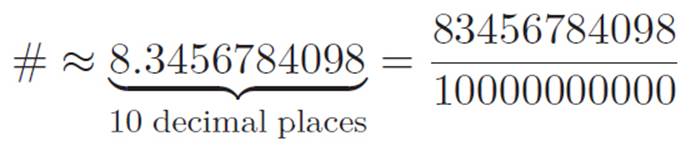
So even though this is a random number I just made up, we can see without any fancy mathematics that we can approximate it to (say) ten decimal places just by using one whole number divided by another. Clearly, this will work no matter what the original number was, and no matter how many decimal places worth of accuracy we want.
Because of this, we’ll start the process of trying to convince ourselves that (x#)′ = #x#−1 is true for any number # by first looking at powers of the form ![]() , protected by the knowledge that we can always get as close to any number # as we want using numbers of this form. We don’t know yet whether there are numbers that can’t be written exactly as a ratio of whole numbers — maybe every number is just a ratio of whole numbers, maybe not; we don’t know yet — but the argument above assures us that even if such weird numbers do exist, we can always get as close to them as we want by using ratios of whole numbers. Then, if we ever discover that not all numbers can be written as
, protected by the knowledge that we can always get as close to any number # as we want using numbers of this form. We don’t know yet whether there are numbers that can’t be written exactly as a ratio of whole numbers — maybe every number is just a ratio of whole numbers, maybe not; we don’t know yet — but the argument above assures us that even if such weird numbers do exist, we can always get as close to them as we want by using ratios of whole numbers. Then, if we ever discover that not all numbers can be written as ![]() , where m and n are whole numbers, we could try to convince ourselves that the pattern still works, if we feel like doing so. Let’s finish this mystery off once and for all.
, where m and n are whole numbers, we could try to convince ourselves that the pattern still works, if we feel like doing so. Let’s finish this mystery off once and for all.
3.4.5Avoiding Tedium
At this point, we could choose to do basically the same thing we did above, and define the machine:
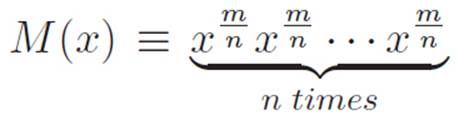
On the one hand, this is just a silly way of writing M(x) = xm, and we know how to differentiate that. We could also differentiate M(x) using the really powerful hammer that we invented earlier (the one that lets us differentiate n machines multiplied together). Then, we would have written the same thing in two ways, so we could slap an equals sign between them and try to isolate the derivative of ![]() . However, that would be a pain, so let’s try to think of a less tedious way to do this. If we can’t think of a simpler way, we can always come back and do it the long way, so there’s no harm in playing around and trying to think of a shortcut.
. However, that would be a pain, so let’s try to think of a less tedious way to do this. If we can’t think of a simpler way, we can always come back and do it the long way, so there’s no harm in playing around and trying to think of a shortcut.
3.4.6A Crazy Idea That Just Might Work
Here’s a crazy idea. We want to differentiate the super-general stuff-to-a-power machine:
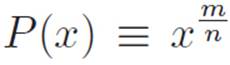
where P stands for “power,” and m and n are whole numbers. Now, because of the way we invented powers, this is just another way of writing
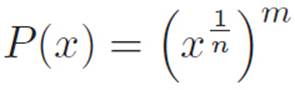
From the very beginning we’ve been emphasizing the fact that we can abbreviate things however we want. Now, if we really take that idea seriously, we can pull off a helpful trick. The expression for P(x) above looks fairly scary, but it’s just
P(x) = (stuff)m
where (stuff) is an abbreviation for x1/n. So P(x)is one thing we know how to differentiate, inside of another thing that we know how to differentiate. That is:
1.We know how to find the derivative of (stuff)m. It’s just m(stuff)m−1.
2.We also know how to find the derivative of (stuff), because (stuff) was just an abbreviation for x1/n, and we figured out the derivative of x1/n a few pages ago.
But this chain of reasoning isn’t really very airtight or convincing, because in sentence (1), we were thinking of (stuff) as the variable, but in sentence (2), we were thinking of x as the variable. It’s not quite clear how to tie those two ways of thinking together. However, if we could somehow tie them together, we might be able to differentiate ![]() , and we may even be able to use this kind of thinking on any crazier machines we might run into in the future.
, and we may even be able to use this kind of thinking on any crazier machines we might run into in the future.
So far, we’ve mostly been using the “prime” notation for derivatives, writing M′ for the derivative of a machine M. That’s totally fine. But we’re also trying to make sense of our crazy idea from above, where we realized that P(x) was made out of two pieces that we knew how to differentiate, one inside the other. To express our idea, we had to think of two different things as “the variable,” but the prime notation doesn’t really let us express that idea very well. What’s the problem? Well, if we can really abbreviate things however we want, then all of the sentences below should be saying the same thing:
(xn)′ = nxn−1
(Qn)′ = nQn−1
(Blah)′ = n(Blah)n−1
This seems perfectly reasonable, because we can abbreviate things however we want. However, the prime notation and this new crazy idea don’t get along very well, and it’s easy to get stuck in a whirlpool of confusion if we use the prime notation and our crazy idea in the same argument. Here’s why. We know 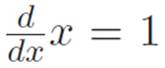 , which is just saying (x)′ = 1, but if we can abbreviate things however we want, then we could take any machine, say M(s) ≡ sn, abbreviate it by writing x ≡ sn, and then using the prime notation we could get (x)′ = 1. However, x was just an abbreviation for sn, and we know that (sn)′ = nsn−1. But then we would have “proved” that nsn−1 = 1, which is certainly not always true! For example, when s = 1 and n = 2, it says that 1 = 2. Aaah! What did we do wrong?
, which is just saying (x)′ = 1, but if we can abbreviate things however we want, then we could take any machine, say M(s) ≡ sn, abbreviate it by writing x ≡ sn, and then using the prime notation we could get (x)′ = 1. However, x was just an abbreviation for sn, and we know that (sn)′ = nsn−1. But then we would have “proved” that nsn−1 = 1, which is certainly not always true! For example, when s = 1 and n = 2, it says that 1 = 2. Aaah! What did we do wrong?
Well, you might be tempted to blame our abbreviations, and say that we really can’t abbreviate things however we want. But of course we can! The trap we found ourselves in just now was really the fault of the prime notation, because it doesn’t remind us which thing we’re thinking of as the variable! When we wrote (x)′ = 1, we were really using the prime to mean “the derivative with respect to x,” or “the derivative if we’re thinking of x as the variable.” When we wrote (sn)′ = nsn−1, we were really using the prime to mean “the derivative with respect to s,” or “the derivative if we’re thinking of s as the variable.” So we didn’t really do anything wrong above when we wrote either of these things, but we weren’t justified in slapping the equals sign between them, because the two expressions were the answers to two different questions.
All is well with the world, and we can still abbreviate things however we want. But we’ve noticed that the prime notation is dangerous if we want to say things like we did in the three expressions involving x, Q, and Blah from earlier. If we instead say what we meant to say above, it would look something like this:
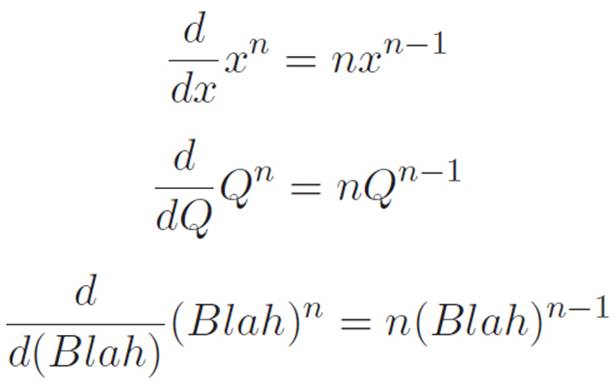
Notice that the thing we’re thinking of as the variable changes in each case, so the x in ![]() changes to Q and then to Blah as we change our minds about what we’re thinking of as the variable. We can still do whatever we want, but we have to make sure we remember what we were thinking earlier when we invented the abbreviations we’re using. Or if we don’t feel like remembering, we at least have to go back and look at what we were thinking when we invented those abbreviations originally. We don’t have to memorize anything, but we do have to make sure not to contradict things we said earlier.
changes to Q and then to Blah as we change our minds about what we’re thinking of as the variable. We can still do whatever we want, but we have to make sure we remember what we were thinking earlier when we invented the abbreviations we’re using. Or if we don’t feel like remembering, we at least have to go back and look at what we were thinking when we invented those abbreviations originally. We don’t have to memorize anything, but we do have to make sure not to contradict things we said earlier.
Now after all this, let’s see if we can express our crazy idea about reabbreviation without using the prime notation. We’ll only let ourselves use the d notation, because that notation makes it easier to switch hats and change our minds about what we’re thinking of as the variable. The idea we had earlier was that if
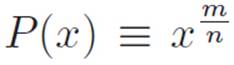
we can choose to think of this as 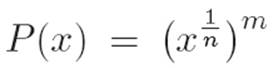 . Then if we abbreviate
. Then if we abbreviate 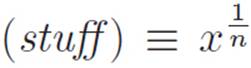 , we have P(x) = (stuff)m, and we can write
, we have P(x) = (stuff)m, and we can write
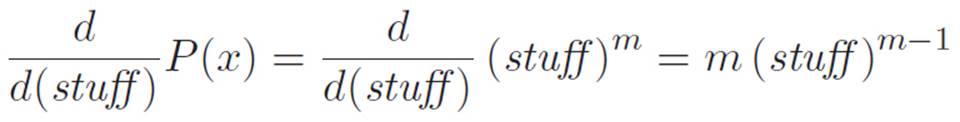
Now that we switched notation, it’s a bit more clear where we went wrong earlier. Everything we just did was right, but it was the right answer to a slightly different question than the one we asked originally. We wanted to know the derivative of P(x), thinking of x as the variable. We answered a slightly different question: the derivative of P(x), thinking of (stuff) as the variable, where (stuff) was an abbreviation for x1/n.
This is exactly the situation we’ve been in several times now. We wanted to answer one question, but we couldn’t. Then we found that if only the question were slightly different, then we could answer it no problem. So to answer the original question — the one we couldn’t answer — we can perform that strange feat of conceptual gymnastics called “lying and correcting for the lie.” If only the question we were asking was “What is the derivative of P(x) with respect to (stuff), where (stuff) is x1/n?” then it would be easy. However, that’s not the question we’re asking, so let’s lie, answer the easier question, and then correct for the lie. Here’s what I mean. We begin with the question:
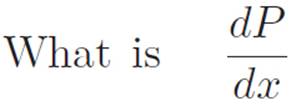
We don’t know, so we lie, and change the question to
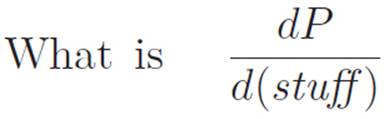
which is a question we can answer, at least when (stuff) is x1/n. However, we lied, and that changes things, so we have to go back and correct for the lie, by first throwing an extra d(stuff) up top to kill the d(stuff) we just introduced on the bottom, and second, replacing the dx on the bottom that we removed when we lied. This gives us the original question, in a slightly different-looking form:
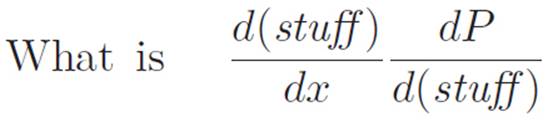
If we don’t want to think about lying and correcting for the lie, we can just think of this whole process as multiplying by 1. To see this, let’s start the problem over and make the whole argument we just made all at once.
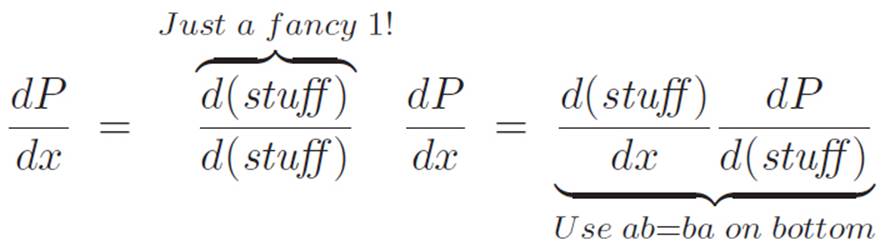
Hey! We know how to calculate both of these things! This is great. We defined 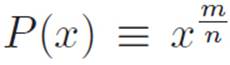 , and we didn’t really want to differentiate it the long way. We could have, but we felt like trying to think of a shortcut. We got confused by the prime notation, but once we rewrote things using the dnotation, the problem became much easier, just by lying and correcting for the lie. We already figured out that the derivative of P with respect to (stuff) was
, and we didn’t really want to differentiate it the long way. We could have, but we felt like trying to think of a shortcut. We got confused by the prime notation, but once we rewrote things using the dnotation, the problem became much easier, just by lying and correcting for the lie. We already figured out that the derivative of P with respect to (stuff) was
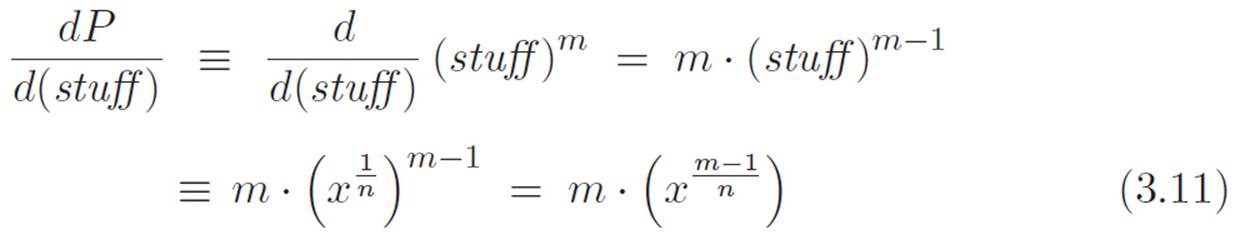
And we already figured out that the derivative of (stuff) ≡ x1/n with respect to x was
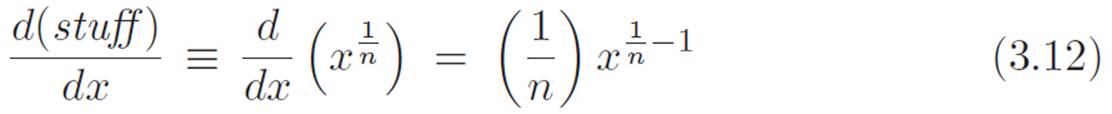
So this new miraculous hammer tells us that the sought-after derivative of P with respect to x, which would have been so tedious to find the long way, can be found by just multiplying the two things above. Let’s do that.
3.4.7The Pattern Emerges Again
We’re basically done. We just have to use the stuff we already invented above. Writing (stuff) as an abbreviation for ![]() , we can use equations 3.11 and 3.12 to write:
, we can use equations 3.11 and 3.12 to write:
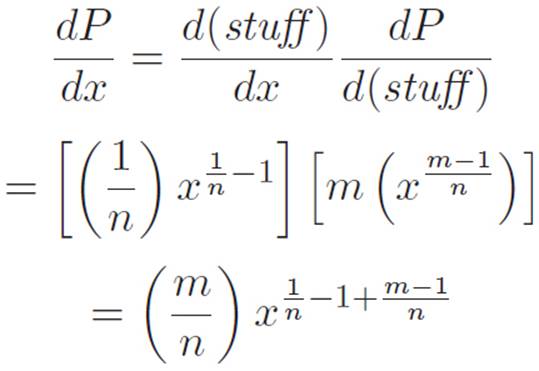
The only ugly part about this is the power, but if we stare at it for a few seconds, we see that it’s just ![]() , so we can write
, so we can write
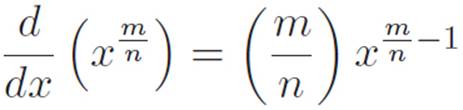
Perfect! This is the same pattern we’ve been seeing all along! This is great. Time for some philosophical yammering.