Mathematics of Life (2011)
Chapter 7. The Molecule of Life
DNA is now a cultural icon. Scarcely a day goes by without some company or person claiming on television or in the newspapers that some activity or product is ‘in their DNA’. It is hailed as ‘the molecule of life’ and ‘the information needed to make an organism’. It is linked to new cures for diseases, the ‘Out of Africa’ theory of the spread of early humanity across the globe, and whether, tens of thousands of years ago, some ancestors of modern humans had sex with Neanderthals (they did).
At times, DNA seems to be accorded almost mystical significance. We are often told that someone is having a child ‘in order to pass on his (or her) DNA’, or perhaps ‘to pass on their genes’. Maybe today some people genuinely have children for those reasons, but for hundreds of thousands of years people have been having children because they wanted to, for personal reasons, or because they couldn’t avoid it. Their genes got passed on anyway, along with their DNA, as a vital part of the process . . . but that wasn’t the reason. It can’t have been. They didn’t know they had genes.
Passing on genes or DNA can be viewed as an evolutionary reason for having children, one that helped instil in us a strong drive to reproduce despite the dangers of childbirth, but we should not confuse human volition with the mechanistic workings of biological development and natural selection. That confusion is a symptom of DNA as icon, something with almost magical significance. But after decades of telling the public that working out the human DNA sequence would lead to cures for innumerable diseases, or allow scientists to engineer new creatures, biologists should hardly be surprised when members of the public take these claims seriously.
There is no doubt that DNA is important. The discovery of its remarkable molecular structure was probably the biggest scientific breakthrough of recent times. But DNA is only one part of a far more complex story. And however magical it may seem, it doesn’t work by magic.
Humanity’s tortuous path to the chemical nature of the gene, and the beautiful geometry of the molecular carrier of heredity, took more than a century.
In 1869 a Swiss doctor, Friedrich Miescher, was engaged in a very unglamorous piece of medical research: analysing pus in bandages that were being discarded after use in surgery. He would have been amazed had he known that he was opening the door to one of the most glamorous areas of science that there has ever been. Miescher discovered a new chemical substance, which turned out to originate inside the nuclei of cells. Accordingly, he called it nuclein. Fifty years later, Phoebus Levine made inroads into its chemical structure, showing that Miescher’s molecule was built from lots of copies of a basic unit, a nucleotide made from a sugar, a phosphate group and a base. He conjectured that the full molecule was made from a moderate number of copies of this nucleotide, attached to one another by the phosphate groups, and repeating the same pattern of bases over and over again.
When more had been discovered about his new molecule, it was named deoxyribonucleic acid,1 which we all know by the acronym DNA. It was a gigantic molecule, and the techniques available then would never be able to reveal its structure – the atoms it contained, and how they were bonded to one another. But two decades later, the technique of X-ray diffraction was coming into use, and it proved to be just the ticket.
Light is an electromagnetic wave, and so are X-rays. When a wave encounters an obstacle, or passes through a series of closely spaced obstacles, it appears to bend. This effect is called diffraction. The exact mechanism depends on the mathematics of wave interference. The basic principles were discovered by the father-andson team of William Lawrence Bragg and William Henry Bragg in 1913. The wavelength of X-rays is in the right range for them to be diffracted by the atoms in a crystal.
There are mathematical techniques for reconstructing the atomic structure of the crystal from the diffraction pattern that it produces. One of them is Bragg’s law, which describes the diffraction pattern created by a series of equally spaced parallel layers of atoms, a particularly simple type of crystal lattice. The law can be used to deduce the spacing and orientation of such layers within a crystal. The mathematical concept that provides all of the fine details about how the atoms are arranged is the Fourier transform, introduced by the French mathematician Joseph Fourier in the early 1800s in a study of heat flow. Here the idea is to represent a periodic pattern in space or time as a superposition of regular waves of all possible wavelengths. Each such wave has an amplitude (how large the peaks and troughs of the wave are) and a phase (determining the precise positions of the peaks).
The main goal of X-ray diffraction is to find the electron density map of the crystal – that is, the way its electrons are distributed in space. From this, its atomic structure and the chemical bonds that hold the atoms together can be worked out. To do this, crystallographers observe the diffraction patterns produced by a beam of X-rays passing through a crystal. They repeat these observations with the crystal aligned at many different angles to the beam. From these measurements they deduce the amplitude of each component wave in the Fourier transform of the electron density. Finding the phase is much harder; one method is to add heavy metal atoms, such as mercury, to the crystal, and then compare the new diffraction pattern with the original one. The amplitudes and phases together determine the entire Fourier transform of the electron density, and a further ‘inverse’ Fourier transform converts this into the electron density itself. So, if you have an interesting molecule and can persuade it to crystallise, you can use X-ray diffraction to probe its atomic structure. As it happens, DNA can be made to crystallise, though not easily. In 1937 William Astbury used X-ray diffraction to confirm that the molecule has a regular structure, but he could not pin down what that structure was.
In the meantime, cell biologists had been figuring out what DNA did. There was certainly a lot of it about, so it ought to have some important function. In 1928 Frederick Griffith was studying the bacterium then called Pneumococcus, now Streptococcus pneumoniae, a major cause of pneumonia, meningitis and ear infections. The bacterium exists in two distinct forms. Type II-S is recognisable by its smooth surface, a capsule that protects it from the host’s immune system, giving it time to kill the host. Type II-R has a rough surface – no capsule, hence no protection, so it succumbs to the host’s immune system. Griffith injected live rough bacteria into mice, which survived. The same happened when he injected dead smooth bacteria. But when he injected a mixture of these two apparently harmless forms, the mice died.
This was surprising, but Griffith noticed something even more surprising. In the blood of the dead mice, he found live smooth bacteria. He deduced that something – he didn’t know what, and in the time-honoured terminology of biology he gave it a vague name, the ‘transforming principle’ – must have passed from the dead smooth bacteria to the live rough bacteria. The explanation came in 1943, when Oswald Avery, Colin MacLeod and Maclyn McCarty showed that Griffith’s ‘transforming principle’ was a molecule, DNA. The DNA of the dead smooth bacteria was somehow responsible for the existence of the protective capsule, and it had been taken up by the live rough ones – which promptly acquired their own capsules, and in effect turned into the smooth form. Presumably, the rough form does not have that particular type of DNA – though it does have its own DNA. The Avery – MacLeod – McCarty experiment strongly suggested that DNA was the longsought molecular carrier of inheritance, and this was confirmed by Alfred Hershey and Martha Chase in 1952, when they showed that the genetic material of a virus known as the T2 phage is definitely DNA. The experiment also suggested that superficially identical molecules of DNA can be subtly different from one another.
The race was now on to determine the exact molecular structure of DNA. As so often happens in science, the key results came in a series of steps, not all of which were recognised to be significant when they were first discovered. It was already known from Levine’s work that DNA was made from nucleotides, and each nucleotide was made from a sugar, a phosphate group and a base. It now transpired that there were four distinct bases: adenine, cytosine, guanine and thymine – all small, simple molecules (see Figure 15).
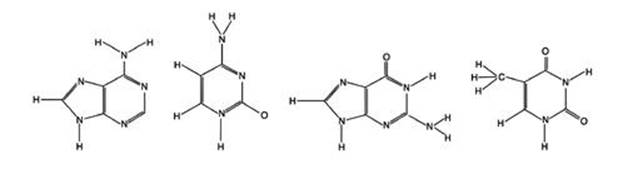
Fig 15 The four DNA bases. Left to right: Adenine, cytosine, guanine, thymine.
How did these four bases sit inside a complete DNA molecule? An important – but initially baffling – clue was found by the Austrian biochemist Erwin Chargaff, who had fled from the Nazis to the USA in 1935. Chargaff made careful studies of nucleic acids, including DNA, and in 1950 he pointed out a curious pattern. Table 4 shows some of his data for how frequently each base occurs in the DNA of various organisms, expressed as a percentage of the total number of bases.
Table 4 Some of Chargaff’s data on the percentage of the four bases in the DNA of various organisms.
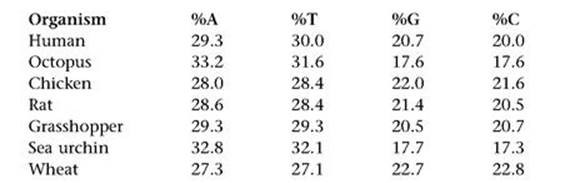
The numbers vary considerably from species to species – A occurs in 29.3% of humans, but 32.8% of sea urchins, for instance. However, there are some clear patterns. One is known as Chargaff parity rule 1. In each organism listed (and in many others), the percentages of A and T are almost equal, and the same goes for G and C. However, those of A/T can differ considerably from G/C. There is also a Chargaff parity rule 2, whose statement involves knowing (as we now do) that DNA consists of two intertwined strands. This states that the same equalities of percentages hold on each strand separately. In addition, Wacław Szybalski noticed that usually – though not always – the percentage of A/T is greater than that of G/C.
These three rules refer only to the overall percentages of the four bases in bulk DNA. They do not tell us – not directly – about the positioning of the bases within the molecule. We still do not know why Chargaff parity rule 2 and Szybalski’s rule hold, but Chargaff parity rule 1 has a very simple explanation, which was one of the clues that led Crick and Watson to the famous double helix. They noticed that guanine and cytosine naturally join together using three hydrogen bonds, and similarly adenine and thymine join up using two hydrogen bonds (the dotted lines in Figure 16). Moreover, the two resulting pairs are chemically very similar – they have almost the same shape, the same size and the same potential for joining up with other molecules in the DNA structure.
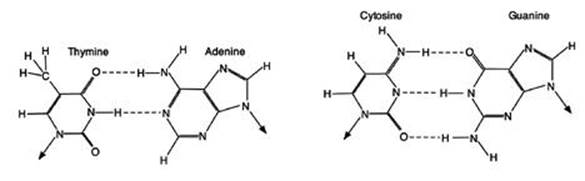
Fig 16 How bases pair up in DNA. The two joined pairs have almost identical shapes and sizes.
It was as though Chargaff had analysed a huge consignment of cutlery and crockery, and found that the percentages of knives and forks were the same, and similarly for cups and saucers. What might seem coincidence for the entire consignment made immediate sense if it were made up of packages each consisting either of paired knives and forks or paired cups and saucers. Then the percentages would match exactly, and they would match in every part of the consignment, not just in the overall totals. Similarly, if Crick and Watson were right, Chargaff parity rule 1 would be an immediate consequence. Not only were the percentages equal in bulk DNA, but the bases were arranged in matching pairs – like knives and forks.
This simple observation suggested that the DNA of organisms was made from these base pairs. When considered alongside other known features of the molecule, and an X-ray diffraction pattern obtained by Maurice Wilkins and Rosalind Franklin, it suggested a dazzlingly simple idea. DNA was a huge stack of base pairs, piled one on top of the other, held together by other parts of the molecule such as phosphate groups. The chemical forces between the atoms caused each successive base pair to be twisted by a fixed amount, relative to the one beneath. The base pairs were arranged like the slabs of a spiral staircase – or more accurately, two intertwined spiral staircases. The mathematical term for the shape is ‘helix’, so DNA was a double helix.
Watson’s book of the same name told the story, warts and all, including his view of the difficulties encountered when trying to obtain access to Franklin’s data, and how he and Crick dealt with them. By his own admission, this was not the pinnacle of scientific ethics, but was justified by the pressing need to sort out the structure before Nobel prize-winner Linus Pauling beat them to it. The story had a tragic ending: Franklin died of cancer, while Crick and Watson (and to a lesser extent Wilkins) got the glory.
When Crick and Watson published the double-helix structure of DNA in Nature in 1953, they pointed out that the occurrence of bases in specific pairs suggested an obvious way for DNA to be copied – which was necessary both for cell division and to transmit genetic information from parent to offspring. The point is that if you know one half of a base pair, you immediately know what the other half is. If one half is A, the other must be T; if one half is T, the other must be A. The same goes for G and C. So you could imagine some chemical process unzipping the two helical strands, pulling them apart, tacking on the missing half of each base pair and coiling the two resulting copies back into double helices.
If you think about the geometry, it is clear that this process can’t be straightforward, and may not be a literal description. The strands will get tangled up for topological reasons – try separating the strands of a length of rope and you’ll soon see why.
Biochemists now have strong evidence that the actual process involves several other molecules, types of enzyme, whose structure, intriguingly, is also coded in the organism’s DNA.2 Two of these enzymes, a helicase and a topoisomerase, unwind the double helix locally (Figure 17, see over). Then missing halves of the base pairs in the two separated strands are reconstituted, but not quite simultaneously. One strand leads and the other lags, probably because that makes room for the necessary molecular machinery to gain access and do the job. Another enzyme called DNA polymerase then fills in the matching pairs for the leading strand copy, while a second DNA polymerase does the same for the lagging strand. DNA polymerase makes its copies in short chains called Okazaki fragments. Then yet another enzyme worker, DNA ligase, joins the Okazaki fragments together.
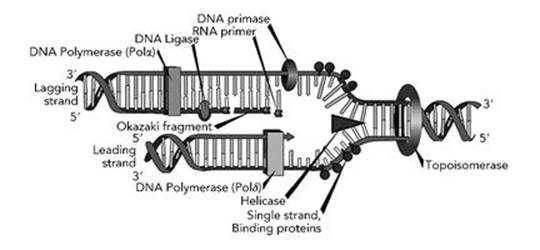
Fig 17 How to copy a DNA double helix. The entire process moves along the helix from left to right.
You can see why Crick and Watson kept their speculations about replication brief, but also why they felt the need to say something, otherwise someone else would have made the same obvious suggestion and claimed the credit. And you can see why it took about fifty years to sort out how the trick was actually achieved.
That was how DNA represented genetic ‘information’, and how the information was copied from parent to offspring. But what did the information mean?
The earliest proposal was that DNA is a recipe for proteins. Organisms are made from proteins – plus other things, but proteins are the most complex constituents, the most common and arguably the most important. Proteins are long chains of molecules known as amino acids, and twenty of these occur in living organisms. In an actual molecule the chain folds up in complex ways, but the key to making the chain is to specify the sequence of amino acids.
Soon after Crick and Watson’s publication of the double-helix structure, the physicist George Gamow suggested that the most likely way for DNA sequences to specify amino acid sequences was by a three-letter code. His argument was a mathematical thought experiment. Using the four bases as letters, you can form 4 oneletter words (A, C, G, T), 4×4=16 two-letter words (AA, AC, ..., TT), and 4×4×4=64 three-letter words (AAA, AAC, ..., TTT). Using one or two letters provided a total of 20 possible words – but how could the chemistry tell that AA is a two-letter word rather than two separate A’s? It made more sense to use words of a fixed length, which had to be at least three since there were too few two-letter words to specify 20 amino acids. With 64 three-letter words to play with there is plenty of wiggle room, so it seemed highly inefficient to use even more letters.
A long series of brilliant experiments proved Gamow right, and led to what we now call the genetic code. It’s worth looking at this in detail, because it displays a puzzling mixture of pattern and irregularity.
Table 5 The 20 amino acids involved in the genetic code, and which triplet of DNA bases codes for which amino acid.
Alanine (Ala), arginine (Arg), asparagine (Asn), aspartic acid (Asp), cysteine (Cys), glutamic acid (Glu), glutamine (Gln), glycine (Gly), histidine (His), isoleucine (Ile), leucine (Leu), lysine (Lys), methionine (Met), phenylalanine (Phe), proline (Pro), serine (Ser), threonine (Thr), tryptophan (Trp), tyrosine (Tyr), valine (Val)
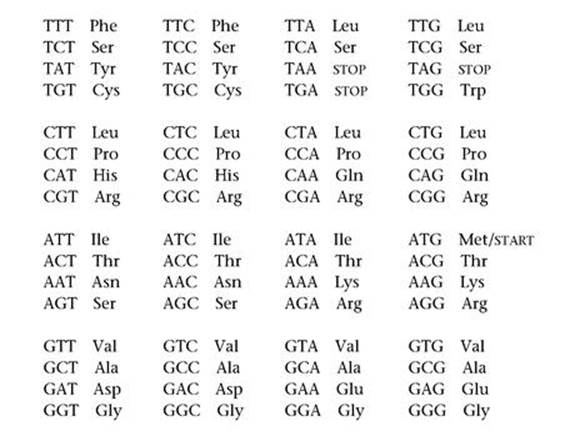
Table 5 lists the 20 amino acids involved and which triplet of DNA bases codes for which amino acid. To bring out the structure, I’ve split the triplets into four blocks, according to the first letter; then within each block, the second letter corresponds to the row and the third letter to the column. The triplets TGA, TAA, TAG and ATG are exceptional. The first three of these do not code for an amino acid, but stop the conversion of triplets into amino acids. When the fourth triplet ATG is at the beginning of a gene it causes this process to start, but otherwise it codes for methionine.
We speak of ‘the’ genetic code because exactly the same code applies to the nuclear DNA sequences of virtually every known microorganism, plant and animal. There are a very small number of exceptions, almost all of which assign an amino acid to one of the three STOP triplets. Also, mitochondria contain their own DNA, and the genetic code for mitochondrial DNA has some small but important differences.3 A very similar code applies to DNA’s sister molecule RNA (ribonucleic acid), which among other things plays a key role in turning DNA code into proteins, a process known as transcription. The code in RNA has exactly the same structure, but with thymine (T) replaced by a similar molecule, uracil (U). You will often see U used in place of T in sequence data.
The genetic code contains both intriguing hints of order and baffling irregularities. There are more triplets than amino acids (even counting STOP and START), so some amino acids must be specified by several triplets. The most common number is four triplets to an amino acid: for example TCT, TCC, TCA and TCG all code for serine (the top row of triplets in the table). Here the third letter tells us nothing new, so it is redundant as far as the code goes. This feature is common: eight of the sixteen rows in the table correspond to precisely one amino acid. The third letter could not be removed entirely in these cases, because the current chemical machinery works with triplets. But this pattern suggests that maybe there was once a simpler code, using pairs of bases, and TC indicated serine. Later, the code itself evolved.
However, phenylalanine corresponds to TTT and TTC, but TTA and TTG correspond to leucine. So do four triplets that begin with CT. So here two triplets code for phenylalanine, but a whopping six for leucine. It is as if the genetic code itself also evolved – but how could it, while still ‘working’?
There are mathematical issues here, to do with changes to codes and why they occur, as well as biological questions. Any major changes in the code must have happened very early on, when life was first appearing on Earth, because once life gets going, changes at such a fundamental level become increasingly difficult, and we ought to see remnants of discarded codes somewhere in the living world, albeit in some obscure organism. As I’ve said, there are a few exceptions to the standard genetic code, but those look like recent slight changes, not ancient major ones.
The ‘frozen accident theory’ takes the view that the genetic code could easily have been very different. A different code would have worked fine, but when life began to diversify, whichever code was in use could no longer survive major changes. A code that initially arose by accident was frozen in place once variants couldn’t compete with the established code.
However, there are tantalising hints that the current code might be more ‘natural’ than most alternatives. There are biochemical affinities between particular amino acids and particular triplets, so the whole set-up might have been predisposed towards some relatively minor variant of the code we find today.
Attempts are being made to trace the likely evolution of the early code, before it became locked in, based on symmetry principles and a host of other speculative uses of mathematics and physics, to try to reconstruct whatever it was that happened about 3.8 billion years ago. Finding definitive evidence, when DNA data for organisms more than a few tens of thousands of years old are unobtainable, will be tricky. So this one will run and run.
DNA provided an unexpected source of independent evidence in favour of evolution.
Before Crick and Watson discovered the structure of DNA, taxonomists had developed Linnaeus’s classification scheme into an extensive description of the ‘Tree of Life’, the presumed evolutionary ancestry of today’s organisms, by comparing the anatomical features and behaviour of existing creatures. This complex sequence of divergent species constituted a massive collection of predictions based on evolutionary theory. What was needed was an independent way to test those predictions – and DNA sequencing does exactly that. When suitable techniques became available, it turned out that organisms thought to be related by evolution generally have similar DNA sequences.
In some cases it is even possible to determine a specific genetic change that distinguishes two species. Lacewings are elegant, delicate flying insects which occupy some 85 genera and about 1,500 species. In North America the two most common species are Chrysopa carnea and C. downesi. The first is light green in spring and summer but brown in autumn, whereas the second is permanently dark green. The first lives in grasslands and deciduous trees; the second lives on conifers. The first breeds twice, once in the winter and once in summer; the second breeds in the spring.
In the wild the two types do not interbreed, so they satisfy the usual definition of distinct species. However, the genetic differences between them are small and very specific, and centre on three genes. One controls colour, and the other two control the breeding time via the insect’s response to the length of daylight (a common mechanism found in insects to ensure that they breed at a suitable time of year). These genetic differences were initially inferred from laboratory experiments in which the two species were brought together and given the opportunity to interbreed.
Natural selection suggests a simple explanation of these findings. A dark green insect is less visible on a dark green conifer than a light green one is. So when dark mutants appeared, natural selection kicked in: dark green lacewings that lived on conifers were better protected against predators than light green ones, and conversely light green ones living on light green grass were better protected than dark green ones. Once the two incipient species came to occupy separate habitats, they ceased to interbreed – not because this was impossible in principle, but because they didn’t meet up very often. The accompanying changes to the breeding time reinforced this ‘reproductive isolation’.
Detailed analysis of a truly gigantic number of DNA sequences leads to a Tree of Life that is very similar to the one already developed on purely taxonomic grounds. The correspondence isn’t perfect – it would be very suspicious if it were – but it is strikingly good. So DNA mutations joined the story, confirming most of the evolutionary sequences that taxonomists had inferred from phenotypes, and providing clear evidence of the underlying genetic mutations that enabled phenotypic changes.
A fossil rabbit in the wrong geological stratum would disprove evolution. So would a modern rabbit with the wrong DNA.
The supremacy of the gene has become entrenched in our collective consciousness to such an extent that news media often talk of ‘genetic science’ when no genes or DNA are involved at all. The vivid, flawed, but by no means nonsensical image of the ‘selfish gene’ introduced in Richard Dawkins’ book of the same title has captured public imagination.4 The main motivation for this image is the existence of so-called junk DNA,5 which gets replicated along with the important parts of the genome when an organism reproduces. From this, Dawkins argues that the survival of a segment of DNA is the sole criterion for its successful replication, whence DNA is ‘selfish’.6
This is of course the old ‘a chicken is just an egg’s way to breed a new egg’ line of thinking, dressed up in fancy hi-tech. It is equally possible to give an account of genetics and evolution from the point of view of an organism, leading to what biologist Jack Cohen and I call the ‘slavish gene’, obsessed with activities that do not damage the organism’s survival chances.7 The selfish gene metaphor is not wrong – in fact, it is intellectually defensible as a debating point. But it diverts our attention rather than adding to our understanding. The relation between genes and organisms is a feedback loop: genes affect organisms via development; organisms affect genes (in the next generation) via natural selection. It is a fallacy to attribute the dynamics of this loop to just one of its components. It’s like saying that wage increases cause inflation, but forgetting that price increases fuel demands for higher wages.
The image of the selfish gene has also inspired a rather naive kind of genetic determinism, in which the only things that matter about human beings are their genes. This vision of the gene as absolute dictator of form and behaviour lies not far beneath the surface of today’s biotechnology: so-called ‘genetic engineering’. By cutting and splicing DNA molecules, it is possible to insert new genes into an organism or to delete or otherwise modify existing ones. The results are sometimes beneficial: pest resistance in agricultural plants, for instance. But even this can have undesirable side effects.
Such technology is controversial, especially when it comes to genetically modified food. There are good reasons for this controversy, and both sides have put forward some compelling arguments. My own feeling is that we know enough about the mathematics of complex systems to be very wary of simplistic models of how genes act, and this feeling is reinforced by the huge amount that we don’t know about genes. I wouldn’t trust a computer whose software had been hacked by a bright ten-year-old, even if the result gave me a really nice screen saver. I would worry whether anything had accidentally been damaged when the program was hacked. I would be more likely to trust a professional programmer who really understood the computer’s operating system. But right now, genetic engineers are really just clever hackers, and no one has much idea of how the genetic ‘operating system’ really works.
With huge amounts of money at stake, the discussion has become polarised. Opponents of genetic modification are often branded as ‘hysterical’, even when they make their criticisms in a moderate and well-reasoned manner. Biotechnology companies are accused of taking huge risks for profit even though some of their motives are more benign. Some people deny that any risks exist; others exaggerate them. Underneath these arguments is a serious scientific problem which deserves more attention. To put it bluntly: our current understanding of genetics is completely inadequate for assessing the likely benefits, costs or potential dangers of genetic modification.
This may seem a strong claim, but specialists in genetics are often blinded by their own expertise. Knowing far more about genes and their modification than the opposition, they fall into the trap of thinking that they know everything. However, the entire history of genetics shows, that at every stage of its development, whenever new data became available most of the previous confidently held theories topple in ruins.
Only a few decades ago, each gene was thought to occupy a single connected segment of the genome, and its location was fixed. Barbara McClintock, a geneticist at Cornell University, made a series of studies of maize and deduced that genes can be switched on or off, and that they can sometimes move. For years her ideas about ‘jumping genes’ were derided, but she was right. In 1983 she won a Nobel prize for discovering what are now called transposons – mobile genetic elements.
Before the human genome was sequenced – a story I’ll tell in the next chapter – the conventional wisdom was that one gene makes one protein, and since humans have 100,000 proteins, they must have 100,000 genes. This was pretty much considered to be a fact. But when the sequence was obtained, the number of genes was only a quarter of that. This unexpected discovery drove home a message that biologists already knew, but had not fully taken on board: genes can be chopped up and reassembled when proteins are being made. On average, each human gene makes four proteins, not one, by exploiting this process.
Each overturning of the conventional wisdom can be viewed in a positive light: human knowledge is thereby advanced, and we gain insight into life’s subtleties. But there is a negative aspect as well: the overwhelming confidence that the system was thoroughly understood, and that no big surprises were going to happen, right up to the moment when it all fell to bits. This does not set a convincing precedent.
Genetic modification has huge potential, but there is a danger of this being squandered by prematurely bringing experimental organisms to market. The commercial use of genetically modified food plants has already led to unexpected adverse effects, and hardly any of the plants have lived up to the early hype. Most were quickly withdrawn. Some that initially appeared to be successes are running into trouble. There is a tendency among biotechnology companies to focus on food safety (‘our grain is perfectly safe’), where they feel comfortable. They tend to ignore potential undesirable effects on the environment, especially delayed-action effects, our knowledge of which is pitiful – mainly because we don’t understand ecosystems well enough. No amount of genetic expertise will improve that.
However, safety is also a significant concern. The argument that genetic modification merely does quickly and directly what conventional plant breeding does slowly and indirectly is nonsense. Conventional breeding mimics nature by forming new combinations using existing genes, through the operation of the plant’s normal genetic machinery. Genetic modification fires alien DNA randomly into the genome, allowing it to lodge wherever it falls. But an organism’s genome is not merely a list of bases. It is a highly complex dynamical system. It is naive to imagine that making crude changes here and there will have only the obvious, expected effects.
Imagine taking a gene whose effect, in its normal location in its normal organism, is to make a protein that has no adverse effect on humans – which is what ‘safe to eat’ basically means. Does that guarantee that it will be equally ‘safe’ when introduced into a new organism? On the contrary: it could potentially wreak havoc, because we often don’t know where the new segment of DNA will lodge itself – and even if we do, genes can move. The new gene might not make the desired protein and nothing else. It might not make it at all. It could end up inside another gene, interfering with that gene’s function. This function might be making a protein: if so, either the wrong protein gets made, with potential hazards, or it doesn’t get made, with knock-on effects for the whole plant. Worse, the newcomer might end up inside a regulatory gene, and the entire network of gene interactions could go haywire.
None of this is particularly likely, but it is possible. Organisms reproduce, so any disaster can propagate and grow. We have the perennial problem of an event that is very unlikely, but could do enormous damage if it happens, with the added feature that it can reproduce.
In the rush to market, experiments have been carried out on a large scale in the natural environment, when controlled laboratory testing would have been far more effective and informative. The British Government sanctioned large-scale planting of genetically modified plants in order to test whether their pollen spread only a few metres (as expected) and to make sure that the new gene would not be spontaneously incorporated into other species of plant (ditto). It turned out that the pollen spread for miles, and the new genes could transfer without difficulty to other plants. Effects like this could, for example, create pesticide-resistant strains of weeds. By the time the experiment had revealed that the conventional wisdom was wrong, there was no way to get the pollen, or its genes, back. Simple laboratory tests – such as painting pollen onto plants directly – could have established the same facts more cheaply, without releasing anything into the environment. It was a bit like testing a new fireproofing chemical by spraying it on a city and setting the place alight, with the added twist that the ‘fire’ might spread indefinitely if, contrary to expectations, it took hold.
It is all too easy to imagine that the genome is a calm and orderly place, a repository of information that can be cut and pasted from one organism to another, only ever performing ‘the function’ that geneticists expect it to perform. But it’s not – it’s a hotbed of dynamic interactions, of which we understand only the tiniest part. Genes have many functions; moreover, nature can invent new ones. They do not bear a label ‘USE ONLY TO MAKE PROTEIN X’.
Continuing to do research on genetic modification, and occasionally using successfully modified organisms for specific purposes such as the production of expensive drugs, make good sense. Helping developing countries to produce more food is a worthy aim, but it is sometimes used as an excuse for an alternative agenda, or as a convenient way to demonise opponents. There is little doubt that the technology needs better regulation: I find it bizarre that standard food safety tests are not required, on the grounds that the plants have not been changed in any significant way, but that the innovations are so great that they deserve patent protection, contrary to the long-standing view that naturally occurring objects and substances cannot be patented. Either it’s new, and needs testing like anything else, or it’s not, and should not be patentable. It is also disturbing, in an age when commercial sponsors blazon their logos across athletes’ shirts and television screens, that the biotechnology industry has fought a lengthy political campaign to prevent any mention of their product being placed on food. The reason is clear enough: to avoid any danger of a consumer boycott. But consumers are effectively being force-fed products that they may not want, and whose presence is being concealed.
Our current understanding of genetics and ecology is inadequate when it comes to the widespread use of genetically modified organisms in the natural environment or agriculture. Why take the risk of distributing this material, when the likely gains for most of us – as opposed to short-term profits for biotechnology companies – are tiny or non-existent?
It was once thought that an organism’s DNA contains all of the information required to determine its form and behaviour. We now know that this is not the case. The genome is of course very influential, but several other factors can affect the developing organism. Collectively, they are known as epigenetic features. The word epigenetics means ‘above genetics’. It refers to changes in phenotype or gene expression that can be passed on to the next generation, but do not reside in DNA.
Among the first epigenetic processes to be discovered was DNA methylation. Here a region of DNA acquires a few extra atoms, a methyl group. This causes a cytosine base to change into a closely related molecule, 5-methylcytosine. This modified form of cytosine still pairs up with guanine in the DNA double helix, but it tends to ‘switch off’ that region of the genome, with the result that the proteins that are being encoded are produced in smaller quantities.
Another is RNA interference. This remarkable phenomenon is enormously important, yet it was not discovered through a major research programme: several biologists discovered the effect independently. One of them was Richard Jorgensen. In 1990 his research team was working on petunias, hoping to breed new varieties with brighter colours. They started by trying an obvious piece of genetic modification: engineering extra copies of the pigment-producing gene into the petunia genome. Obviously, more enzyme would produce more pigment.
But it didn’t. It didn’t produce less pigment, either. Instead, it made the petunia stripy.
Eventually, it transpired that some RNA sequences can switch a gene off, and that stops it making protein. The stripes appeared because the pigment genes were switched on in some cells and off in others. This ‘RNA interference’ turns out to be very common. It opens up the prospect of deliberately switching genes on or off, which would be important in genetic engineering. More fundamentally, it changes how biologists view the activity of the gene.
The orthodox picture, as I’ve said, was that each gene makes one protein, and each protein has one function in the organism. For instance, the haemoglobin gene makes haemoglobin, and haemoglobin carries oxygen in the blood and releases it where it is needed. So a specific sequence in an organism’s DNA can be translated directly into a feature of the organism. But as the geneticist John Mattick wrote in Scientific American8:
Proteins do play a role in the regulation of eukaryotic gene expression, yet a hidden, parallel regulatory system consisting of RNA that acts directly on DNA, RNAs and proteins is also at work. This overlooked RNA signalling network may be what allows humans, for example, to achieve structural complexity far beyond anything seen in the unicellular world.
Some epigenetic effects involve DNA, but in a different organism. In mammals, for instance, the early stages of an egg’s development are controlled, not by the egg’s DNA, but by that of the mother. This actually makes a lot of sense, because it lets a fully functioning organism kick-start the growth of the next generation. But it means that a key stage in the growth of, say, a cow is not controlled by that cow’s DNA. It is controlled by another cow’s DNA.
Even more broadly, some things can be conveyed from parent to child through cultural interactions rather than genetic ones. This effect is very common in humans – we acquire our language from our culture, our religious beliefs or lack of them, and many other things that make us human. But behaviour is acquired by similar cultural interactions in rats, dogs and many other animals.
When the genetic code was discovered, DNA was seen as a kind of blueprint. Once you possess an engineering blueprint of, say, an aircraft, then any competent engineer will be able to tell you how to make it. Once you possess ‘the information’ to make an animal, you can make that animal. And if you can make it, you must know everything there is to know about it.
It stands to reason.
Well, no, it doesn’t. Put baldly like that, it sounds like an obvious exaggeration, a pun in which different meanings of the word ‘information’ are confused. It doesn’t even work for engineering. You need a lot more than just ‘the blueprint’ to build an aircraft. You need to know all the engineering techniques that are implicit in the blueprint. You need to know how to make the components, how to choose and obtain suitable materials, and you need the right tools.
It works even less well for biology, where the analogous ‘techniques’ are implicit in the way the organisms themselves work. You can’t make a baby tiger from tiger DNA. You need a mother tiger too – or at the very least, you need to know how a mother tiger does the job. And even if this were implicit in her DNA (which it’s not, because of epigenetic effects), you would have to make the implicit explicit. Despite that, the vision of DNA as King led to enormous progress in biology. It, and the associated discoveries about biological molecules, are a major reason why today’s doctors can actually cure many diseases. For previous generations, this was essentially impossible.
The genetic sequences encoded in DNA are a big part of ‘the secret of life’. If you’re not aware of the role of DNA, if you don’t know what the sequence looks like, you’re missing a gigantic part of the picture. It’s like trying to figure out how modern society works when you don’t know about telephones.
But DNA is not the only secret.
Figuring that out took much longer, and was more discouraging. When you’ve made such a huge breakthrough, one that takes you so far in comparison with everything that has gone before, it’s disappointing to discover that unlocking one boxful of secrets and raising the lid does not do a Pandora and reveal all manner of biting insects and vile creatures, but just reveals ... another locked box inside.