CONCEPTS IN BIOLOGY
PART III. MOLECULAR BIOLOGY, CELL DIVISION, AND GENETICS
8. DNA and RNA. The Molecular Basis of Heredity
8.2. DNA Structure and Function
The way DNA accomplishes these cellular processes is related to its structure.
DNA Structure
Nucleic acids are large polymers made of many repeating units called nucleotides. Each nucleotide is composed of a sugar molecule, a phosphate group, and a molecule called a nitrogenous base. DNA nucleotides contain one specific sugar, deoxyribose, and one of four different nitrogenous bases: adenine (A), guanine (G), cytosine (C), and thymine (T) (figure 8.1).
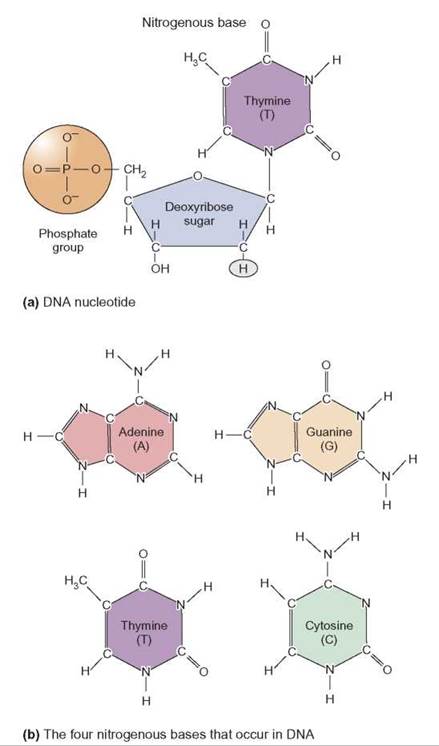
FIGURE 8.1. DNA Nucleotide Structure
The nucleotide is the basic structural unit of all nucleic acids. All DNA nucleotides consist of three parts—a sugar, a nitrogenous base, and a phosphate group. (a) A thymine DNA nucleotide. (b) In DNA, the nitrogenous bases can be adenine, guanine, cytosine, and thymine.
The DNA nucleotides can combine into a long linear DNA molecule that can pair with another linear DNA molecule. The two paired strands of DNA form a double helix, with the sugars and phosphates on the outside and the nitrogenous bases in the inside of the helix. The double helix is stabilized because nitrogenous bases are only able to match up (pair) with certain other nucleotides on the opposing strand. Pairing is determined by the molecular shape of the bases and their ability to form hydrogen bonds. Just which pairs come together is referred to as the base-pair rule. The rule states that adenine (A) pairs with thymine (T) and guanine (G) pairs with cytosine (C). Also notice in figure 8.2 that one strand ends with the number 3', the three-prime strand, while the other is called the 5', or five-prime strand. This is because the two strands run in opposite directions (i.e., one points in one direction while the other points in the opposite direction).
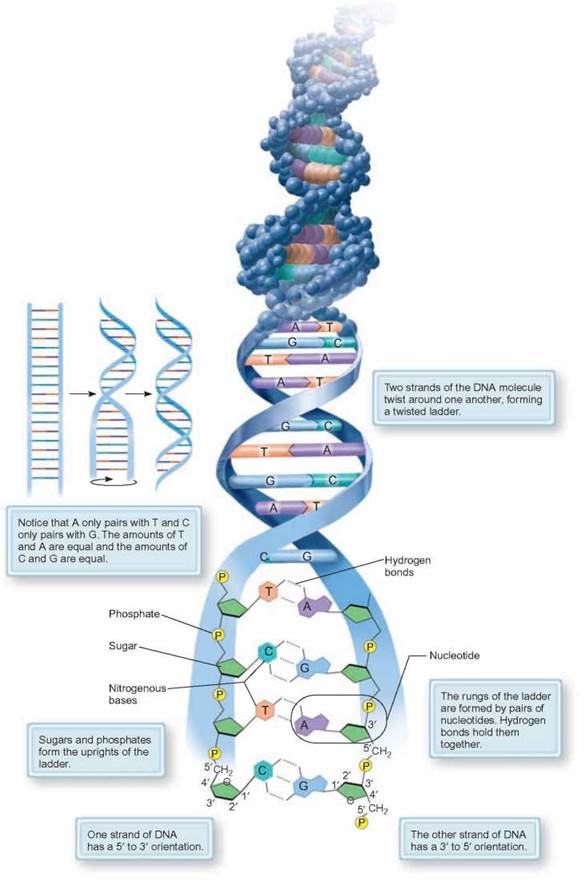
FIGURE 8.2. Double-Stranded DNA
Polymerized deoxyribonucleic acid (DNA) is a helical molecule. The nucleotides within each strand are held together by covalent bonds. The two parallel strands are linked by hydrogen bonds between the base-paired nitrogenous bases.
Base Pairing in DNA Replication
When a cell grows and divides, two new daughter cells result (refer to chapter 1). Both daughter cells need DNA to survive, so the DNA of the parent cell is copied. One copy is provided to each new cell. DNA replication is the process by which a cell makes copies of its DNA. The process of DNA replication relies on DNA base-pairing rules and many enzymes. The general process of DNA replication involves several steps.
1. DNA replication begins as enzymes, called helicases, attach to the DNA and separate the two strands. This forms a replication bubble (figure 8.3a and b).
2. As helicases separate the two DNA strands, another enzyme, DNA polymerase helps attach new, incoming DNA nucleotides one at a time onto the surface of the exposed strands. Nucleotides enter each position according to base-pairing rules—adenine (A) pairs with thymine (T), guanine (G) pairs with cytosine (C) (figure 8.3c and d).
3. In prokaryotic cells, this process starts at only one place along the cell’s DNA molecule. This place is called the origin of replication. In eukaryotic cells, the replication process starts at the same time in several different places along the DNA molecule. As the points of DNA replication meet each other, they combine and a new strand of DNA is formed (figure 8.3e). The result is two identical, double-stranded DNA molecules.
The new strands of DNA form on each of the old DNA strands (figure 8.3e). In this way, the exposed nitrogenous bases of the original DNA serve as the pattern (template) on which the new DNA strand is formed. The completion of DNA replication yields two double helices, which have identical nucleotide sequences. It has been estimated that there is only one error made for every 2 x 109nucleotides. Because this error rate is so small, DNA replication is considered to be essentially error-free. A portion of the DNA polymerase that carries out DNA replication also edits or repairs the newly created DNA molecule for the correct base pairing. When an incorrect match is detected, DNA polymerase removes the incorrect nucleotide and replaces it. Newly made DNA molecules are eventually passed on to the daughter cells.
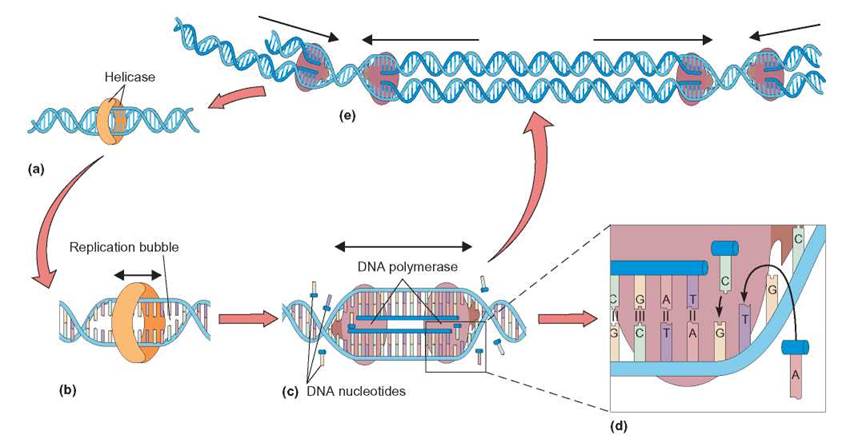
FIGURE 8.3. DNA Replication
(a) Helicase enzymes bind to the DNA molecule. (b) The enzymes separate the two strands of DNA. (c, d) As the DNA strands are separated, new DNA nucleotides are added to the new strands by DNA polymerase. The new DNA strands are synthesized according to base-pairing rules for nucleic acids. (e) By working in two directions at once along the DNA strand, the cell is able to replicate the DNA more quickly. Each new daughter cell receives one of these copies.
The Repair of Genetic Information
Although DNA replication is highly accurate, errors and damage do occasionally occur to the DNA helix. However, the pairing arrangement of the nitrogenous bases allows damage on one strand to be corrected by reading the remaining undamaged strand. For example, if damage occurred to a strand that originally read AGC (perhaps it changed to AAC), the correct information is still found in the other strand that reads TCG. By using enzymes to read the undamaged strand, the cell can rebuild the AGC strand with the pairing rule that A pairs with T and G pairs with C. Another example of genetic repair is shown in figure 8.4.
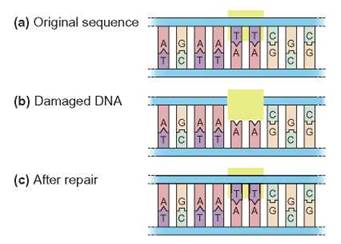
FIGURE 8.4. DNA Repair
(a) Undamaged DNA consists of two continuous strands held together at the nitrogenous bases (A, T, G, and C). (b) Damaged DNA has part of one strand missing. The thymine bases have been damaged and removed. (c) When one strand is damaged, it is possible to rebuild this strand by using the nucleotide sequence on the other side. In DNA, adenine (A) always pairs with thymine (T), and guanine (G) always pairs with cytosine (C).
The DNA Code
DNA is important because it serves as a reliable way of storing information. The order of the nitrogenous bases in DNA is the genetic information that codes for proteins. This is similar to how a sequence of letters presents information in a sentence. For the cell, the letters of its alphabet consist only of the nitrogenous bases A, G, C, and T. The information needed to code for one protein can be thousands of nucleotides long. The nitrogenous bases are read in sets of three. Each sequence of three nitrogenous bases is a code word for a single amino acid. Proteins are made of a string that ranges from a few to thousands of amino acids. The order of the amino acids corresponds to the order of the code words in DNA (i.e., ACC is the code word for the amino acid tryptophan).
8.2. CONCEPT REVIEW
3. What is the base-pairing rule?
4. Why is DNA replication necessary?
5. What factors stabilize the DNA double helix?