Lippincott’s Illustrated Reviews: Biochemistr, Sixth Edition (2014)
UNIT VI: Storage and Expression of Genetic Information
Chapter 31. Protein Synthesis
I. OVERVIEW
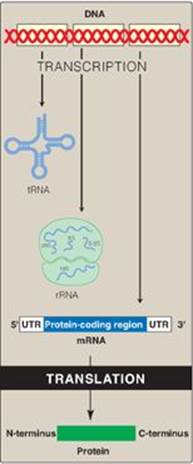
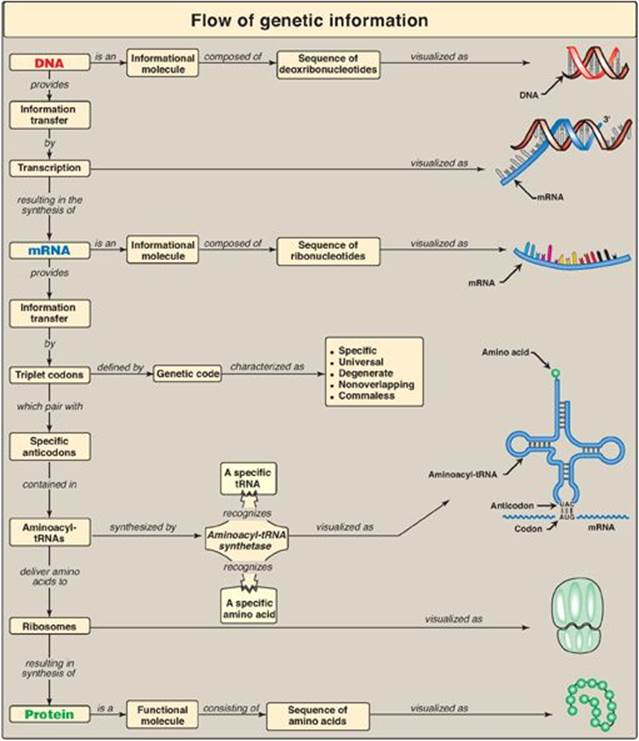
Genetic information, stored in the chromosomes and transmitted to daughter cells through DNA replication, is expressed through transcription to RNA and, in the case of messenger RNA (mRNA), subsequent translation into proteins (polypeptide chains) as shown in Figure 31.1. The process of protein synthesis is called translation because the “language” of the nucleotide sequence on the mRNA is translated into the language of an amino acid sequence. Translation requires a genetic code, through which the information contained in the nucleic acid sequence is expressed to produce a specific sequence of amino acids. Any alteration in the nucleic acid sequence may result in an incorrect amino acid being inserted into the polypeptide chain, potentially causing disease or even death of the organism. Newly made (nascent) proteins undergo a number of processes to achieve their functional form. They must fold properly, and misfolding can result in aggregation or degradation of the protein. Many proteins are covalently modified to activate them or alter their activities. Finally, proteins are targeted to their final intra- or extracellular destinations by signals present in the proteins themselves.
Figure 31.1 Protein synthesis or translation. tRNA = transfer RNA; rRNA = ribosomal RNA; mRNA = messenger RNA; UTR = untranslated region.
II. THE GENETIC CODE
The genetic code is a dictionary that identifies the correspondence between a sequence of nucleotide bases and a sequence of amino acids. Each individual “word” in the code is composed of three nucleotide bases. These genetic words are called codons.
A. Codons
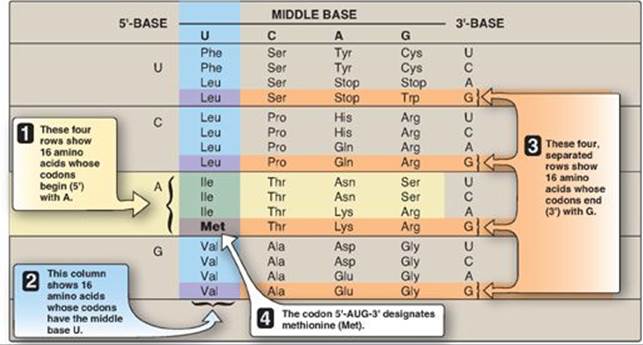
Codons are presented in the mRNA language of adenine (A), guanine (G), cytosine (C), and uracil (U). Their nucleotide sequences are always written from the 5ʹ-end to the 3ʹ-end. The four nucleotide bases are used to produce the three-base codons. There are, therefore, 64 different combinations of bases, taken three at a time (a triplet code) as shown in the table in Figure 31.2.
1. How to translate a codon: This table (or “dictionary”) can be used to translate any codon and, thus, to determine which amino acids are coded for by an mRNA sequence. For example, the codon 5ʹ-AUG-3ʹ codes for methionine ([Met] see Figure 31.2). [Note: AUG is the initiation (start) codon for translation.] Sixty-one of the 64 codons code for the 20 common amino acids.
2. Termination (“stop,” or “nonsense”) codons: Three of the codons, UAA, UAG, and UGA, do not code for amino acids but, rather, are termination codons. When one of these codons appears in an mRNA sequence, synthesis of the polypeptide coded for by that mRNA stops.
Figure 31.2 Use of the genetic code table to translate the codon AUG. A = adenine; G = guanine; C = cytosine; U = uracil. The abbreviations for many common amino acids are shown as examples.
B. Characteristics of the genetic code
Usage of the genetic code is remarkably consistent throughout all living organisms. It is assumed that once the standard genetic code evolved in primitive organisms, any mutation that altered its meaning would have caused the alteration of most, if not all, protein sequences, resulting in lethality. Characteristics of the genetic code include the following.
1. Specificity: The genetic code is specific (unambiguous), because a particular codon always codes for the same amino acid.
2. Universality: The genetic code is virtually universal insofar as its specificity has been conserved from very early stages of evolution, with only slight differences in the manner in which the code is translated. [Note: An exception occurs in mitochondria, in which a few codons have meanings different than those shown in Figure 31.2. For example, UGA codes for tryptophan (Trp).]
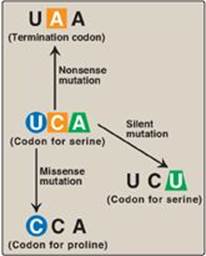
Figure 31.3 Possible effects of changing a single nucleotide base in the coding region of a messenger RNA chain. A = adenine; C = cytosine; U = uracil.
3. Degeneracy: The genetic code is degenerate (sometimes called redundant). Although each codon corresponds to a single amino acid, a given amino acid may have more than one triplet coding for it. For example, arginine (Arg) is specified by six different codons (see Figure 31.2). Only Met and Trp have just one coding triplet.
4. Nonoverlapping and commaless: The genetic code is nonoverlapping and commaless, meaning that the code is read from a fixed starting point as a continuous sequence of bases, taken three at a time without any punctuation between codons. For example, AGCUGGAUACAU is read as AGC UGG AUA CAU.
C. Consequences of altering the nucleotide sequence
Changing a single nucleotide base on the mRNA chain (a “point mutation”) can lead to any one of three results (Figure 31.3).
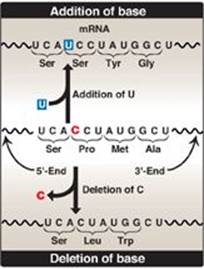
1. Silent mutation: The codon containing the changed base may code for the same amino acid. For example, if the serine (Ser) codon UCA is given a different third base, U, to become UCU, it still codes for Ser. This is termed a “silent” mutation.
2. Missense mutation: The codon containing the changed base may code for a different amino acid. For example, if the Ser codon UCA is given a different first base, C, to become CCA, it will code for a different amino acid (in this case, proline [Pro]). The substitution of an incorrect amino acid is called a “missense” mutation.
3. Nonsense mutation: The codon containing the changed base may become a termination codon. For example, if the Ser codon UCA is given a different second base, A, to become UAA, the new codon causes termination of translation at that point and the production of a shortened (truncated) protein. The creation of a termination (stop) codon at an inappropriate place is called a “nonsense” mutation.
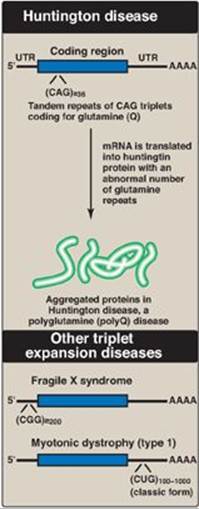
Figure 31.4 Tandem triplet repeats in messenger RNA (mRNA) causing Huntington disease and other triplet expansion diseases. [Note: In unaffected individuals, the number of repeats in the huntingtin protein is fewer than 27, in fragile X mental retardation protein it is 5-44, and in myotonic dystrophy protein kinase it is 5-34.] UTR = untranslated region; A = adenine; C = cytosine; G= guanine; U = uracil; Q = single letter abbreviation for glutamine.
4. Other mutations: These can alter the amount or structure of the protein produced by translation.
a. Trinucleotide repeat expansion: Occasionally, a sequence of three bases that is repeated in tandem will become amplified in number so that too many copies of the triplet occur. If this happens within the coding region of a gene, the protein will contain many extra copies of one amino acid. For example, amplification of the CAG codon leads to the insertion of many extra glutamine residues in the huntingtin protein, causing the neurodegenerative disorder Huntington disease (Figure 31.4). The additional glutamines result in changes in secondary structure that cause the accumulation of protein aggregates. If the trinucleotide repeat expansion occurs in an untranslated region (UTR) of a gene, the result can be a decrease in the amount of protein produced, as seen in fragile X syndrome and myotonic dystrophy. Over 20 triplet expansion diseases are known. [Note: In fragile X syndrome, the most common cause of intellectual disability, the expansion results in gene silencing through DNA hypermethylation (see p. 460).]
b. Splice-site mutations: Mutations at splice sites (see p. 427) can alter the way in which introns are removed from pre-mRNA molecules, producing aberrant proteins. [Note: In myotonic dystrophy, a muscle disorder, gene silencing is the result of splicing alterations due to triplet expansion.]
c. Frame-shift mutations: If one or two nucleotides are either deleted from or added to the coding region of a mRNA, a frame-shift mutation occurs, altering the reading frame. This can result in a product with a radically different amino acid sequence or a truncated product due to the creation of a termination codon (Figure 31.5). If three nucleotides are added, a new amino acid is added to the peptide, or, if three are deleted, an amino acid is lost. Loss of three nucleotides maintains the reading frame but can result in serious pathology. For example, cystic fibrosis (CF), a chronic, progressive, inherited disease that primarily affects the pulmonary and digestive systems, is most commonly caused by deletion of three nucleotides from the coding region of a gene, resulting in the loss of phenylalanine at the 508th position (DF508) in the protein encoded by that gene. This DF508 mutation prevents normal folding of the protein, CF transmembrane conductance regulator (CFTR), leading to its destruction by the proteasome (see p. 247). CFTR normally functions as a chloride channel in epithelial cells, and its loss results in the production of thick, sticky secretions in the lungs and pancreas, leading to lung damage and digestive deficiencies (see p. 248). The incidence of CF is highest (1 in 3300) in those of Northern European origin. In over 70% of individuals with CF, the DF508 mutation is the cause of the disease.
Figure 31.5 Frame-shift mutations as a result of addition or deletion of a base can cause an alteration in the reading frame of messenger RNA (mRNA). A = adenine; C = cytosine; G = guanine; U = uracil.
III. COMPONENTS REQUIRED FOR TRANSLATION
A large number of components are required for the synthesis of a protein. These include all the amino acids that are found in the finished product, the mRNA to be translated, transfer RNA (tRNA) for each of the amino acids, functional ribosomes, energy sources, and enzymes as well as noncatalytic protein factors needed for the initiation, elongation, and termination steps of polypeptide chain synthesis.
A. Amino acids
All the amino acids that eventually appear in the finished protein must be present at the time of protein synthesis. If one amino acid is missing, translation stops at the codon specifying that amino acid. [Note: This demonstrates the importance of having all the essential amino acids (see p. 262) in sufficient quantities in the diet to ensure continued protein synthesis.]
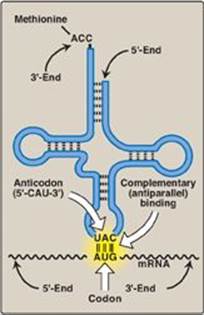
Figure 31.6 Complementary, antiparallel binding of the anticodon for methionyl-tRNA (CAU) to the messenger RNA (mRNA) codon for methionine (AUG), the initiation codon for translation.
B. Transfer RNA
At least one specific type of tRNA is required for each amino acid. In humans, there are at least 50 species of tRNA, whereas bacteria contain at least 30 species. Because there are only 20 different amino acids commonly carried by tRNA, some amino acids have more than one specific tRNA molecule. This is particularly true of those amino acids that are coded for by several codons.
1. Amino acid attachment site: Each tRNA molecule has an attachment site for a specific (cognate) amino acid at its 3ʹ-end (Figure 31.6). The carboxyl group of the amino acid is in an ester linkage with the 3-hydroxyl of the ribose portion of the adenine (A) nucleotide in the —CCA sequence at the 3ʹ-end of the tRNA. [Note: When a tRNA has a covalently attached amino acid, it is said to be charged, and when it does not, it is said to be uncharged. The amino acid attached to the tRNA molecule is said to be activated.]
2. Anticodon: Each tRNA molecule also contains a three-base nucleotide sequence, the anticodon, that pairs with a specific codon on the mRNA (see Figure 31.6). This codon specifies the insertion into the growing peptide chain of the amino acid carried by that tRNA.
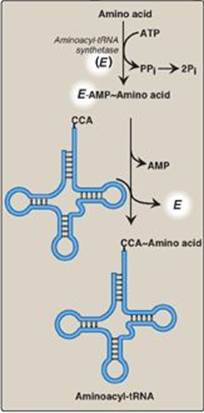
Figure 31.7 Attachment of a specific amino acid to its corresponding tRNA by aminoacyl-tRNA synthetase. PPi = pyrophosphate; Pi = inorganic phosphate; A = adenine; C = cytosine; ATP = adenosine triphosphate; AMP = adenosine monophosphate.
C. Aminoacyl-tRNA synthetases
This family of enzymes is required for attachment of amino acids to their corresponding tRNAs. Each member of this family recognizes a specific amino acid and all the tRNAs that correspond to that amino acid (isoaccepting tRNAs, up to five per amino acid). Aminoacyl-tRNA synthetases catalyze a two-step reaction that results in the covalent attachment of the carboxyl group of an amino acid to the 3ʹ-end of its corresponding tRNA. The overall reaction requires adenosine triphosphate (ATP), which is cleaved to adenosine monophosphate (AMP) and inorganic pyrophosphate (PPi) as shown in Figure 31.7. The extreme specificity of the synthetases in recognizing both the amino acid and its cognate tRNA contributes to the high fidelity of translation of the genetic message. In addition to their synthetic activity, the aminoacyl-tRNA synthetases have a “proofreading” or “editing” activity that can remove an incorrect amino acid from the enzyme or the tRNA molecule.
D. Messenger RNA
The specific mRNA required as a template for the synthesis of the desired polypeptide chain must be present. [Note: In eukaryotes, mRNA is circularized for use in translation.]
E. Functionally competent ribosomes
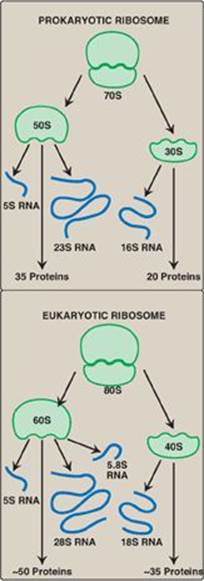
Ribosomes are large complexes of protein and ribosomal RNA ([rRNA], Figure 31.8), in which rRNA predominates. They consist of two subunits (one large and one small) whose relative sizes are given in terms of their sedimentation coefficients, or S (Svedberg) values. [Note: Because the S values are determined both by shape as well as molecular mass, their numeric values are not strictly additive. For example, the prokaryotic 50S and 30S ribosomal subunits together form a 70S ribosome. The eukaryotic 60S and 40S subunits form an 80S ribosome.] Prokaryotic and eukaryotic ribosomes are similar in structure, and serve the same function, namely, as the macromolecular complexes in which the synthesis of proteins occurs.
The small ribosomal subunit binds mRNA and is responsible for the accuracy of translation by ensuring correct base-pairing between the codon in the mRNA and the anticodon in the tRNA. The large ribosomal subunit catalyzes formation of the peptide bonds that link amino acid residues in a protein.
1. Ribosomal RNA: As discussed on p. 418, prokaryotic ribosomes contain three size species of rRNA, whereas eukaryotic ribosomes contain four (see Figure 31.8). The rRNAs are generated from a single pre-rRNA by the action of ribonucleases, and some bases and riboses are modified.
2. Ribosomal proteins: Ribosomal proteins are present in greater numbers in eukaryotic ribosomes than in prokaryotic ribosomes. These proteins play a variety of roles in the structure and function of the ribosome and its interactions with other components of the translation system.
3. A, P, and E sites on the ribosome: The ribosome has three binding sites for tRNA molecules: the A, P, and E sites, each of which extends over both subunits. Together, they cover three neighboring codons. During translation, the A site binds an incoming aminoacyl-tRNA as directed by the codon currently occupying this site. This codon specifies the next amino acid to be added to the growing peptide chain. The P-site codon is occupied by peptidyl-tRNA. This tRNA carries the chain of amino acids that has already been synthesized. The E site is occupied by the empty tRNA as it is about to exit the ribosome. (See Figure 31.13 for an illustration of the role of the A, P, and E sites in translation.)
Figure 31.8 Ribosomal composition. [Note: The number of proteins in the eukaryotic ribosomal subunits varies somewhat from species to species.] S = Svedberg unit.
4. Cellular location of ribosomes: In eukaryotic cells, the ribosomes are either “free” in the cytosol or are in close association with the endoplasmic reticulum (which is then known as the “rough” endoplasmic reticulum, or RER). The RER-associated ribosomes are responsible for synthesizing proteins that are to be exported from the cell as well as those that are destined to become incorporated into plasma, endoplasmic reticulum, or Golgi membranes or imported into lysosomes (see p. 169 for an overview of the latter process). Cytosolic ribosomes synthesize proteins required in the cytosol itself or destined for the nucleus, mitochondria or peroxisomes. [Note: Mitochondria contain their own set of ribosomes and their own unique, circular DNA. Most mitochondrial proteins, however, are encoded by nuclear DNA, synthesized in the cytosol, and posttranslationally targeted to mitochondria.]
F. Protein factors
Initiation, elongation, and termination (or release) factors are required for peptide synthesis. Some of these protein factors perform a catalytic function, whereas others appear to stabilize the synthetic machinery. [Note: A number of the factors are monomeric G proteins, and thus are active when bound to guanosine triphosphate (GTP) and inactive when bound to guanosine diphosphate (GDP) (see p. 95 for a discussion of the heterotrimeric G proteins).]
G. ATP and GTP are required as sources of energy
Cleavage of four high-energy bonds is required for the addition of one amino acid to the growing polypeptide chain: two from ATP in the aminoacyl-tRNA synthetase reaction—one in the removal of PPi, and one in the subsequent hydrolysis of the PPi to inorganic phosphate by pyrophosphatase —and two from GTP—one for binding the aminoacyl-tRNA to the A site and one for the translocation step (see Figure 31.13, p. 440). [Note: Additional ATP and GTP molecules are required for initiation in eukaryotes, whereas an additional GTP molecule is required for termination in both eukaryotes and prokaryotes.]
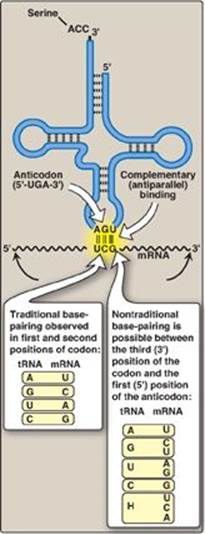
Figure 31.9 Wobble: Nontraditional base-pairing between the 5ʹ-nucleotide (first nucleotide) of the anticodon with the 3ʹ-nucleotide (last nucleotide) of the codon. Hypoxanthine (H) is the product of adenine deamination and the base in the nucleotide, inosine monophosphate (IMP). A = adenine; G = guanine; C = cytosine; U = uracil; tRNA = transfer RNA; mRNA = messenger RNA.
IV. CODON RECOGNITION BY TRANSFER RNA
Correct pairing of the codon in the mRNA with the anticodon of the tRNA is essential for accurate translation (see Figure 31.6). Some tRNAs (isoaccepting tRNAs) recognize more than one codon for a given amino acid.
A. Antiparallel binding between codon and anticodon
Binding of the tRNA anticodon to the mRNA codon follows the rules of complementary and antiparallel binding, that is, the mRNA codon is “read” 5→3 by an anticodon pairing in the “flipped” (3→5) orientation (Figure 31.9). [Note: Nucleotide sequences are always assumed to be written in the 5 to 3 direction unless otherwise noted. Two nucleotide sequences orient in an antiparallel manner.]
B. Wobble hypothesis
The mechanism by which tRNAs can recognize more than one codon for a specific amino acid is described by the “wobble” hypothesis, which states that codon–anticodon pairing follows the traditional Watson-Crick rules (C pairs with G and A pairs with U) for the first two bases of the codon but can be less stringent for the last base. The base at the 5-end of the anticodon (the “first” base of the anticodon) is not as spatially defined as the other two bases. Movement of that first base allows nontraditional base-pairing with the 3-base of the codon (the “last” base of the codon). This movement is called wobble and allows a single tRNA to recognize more than one codon. Examples of these flexible pairings are shown in Figure 31.9. The result of wobble is that there need not be 61 tRNA species to read the 61 codons that code for amino acids.
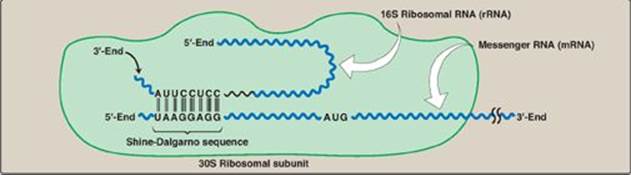
Figure 31.10 Complementary binding between prokaryotic mRNA Shine-Dalgarno sequence and 16S rRNA. S = Svedberg unit.
V. STEPS IN PROTEIN SYNTHESIS
The process of protein synthesis translates the 3-letter alphabet of nucleotide sequences on mRNA into the 20-letter alphabet of amino acids that constitute proteins. The mRNA is translated from its 5ʹ-end to its 3ʹ-end, producing a protein synthesized from its amino (N)-terminal end to its carboxyl (C)-terminal end. Prokaryotic mRNAs often have several coding regions (that is, they are polycistronic; see p. 418). Each coding region has its own initiation and termination codon and produces a separate species of polypeptide. In contrast, each eukaryotic mRNA has only one coding region (that is, it is monocistronic). The process of translation is divided into three separate steps: initiation, elongation, and termination. Eukaryotic protein synthesis resembles that of prokaryotes in most aspects. Individual differences are noted in the text.
One important difference is that translation and transcription are temporally linked in prokaryotes, with translation starting before transcription is completed as a consequence of the lack of a nuclear membrane in prokaryotes.
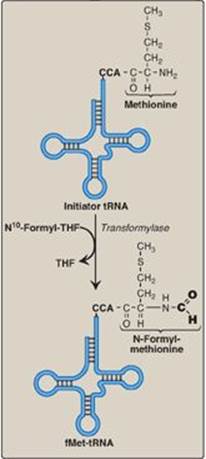
Figure 31.11 Generation of the initiator N-formylmethionyl-tRNA (fMet-tRNA). THF = tetrahydrofolate; C = cytosine; A = adenine.
A. Initiation
Initiation of protein synthesis involves the assembly of the components of the translation system before peptide bond formation occurs. These components include the two ribosomal subunits, the mRNA to be translated, the aminoacyl-tRNA specified by the first codon in the message, GTP (which provides energy for the process), and initiation factors that facilitate the assembly of this initiation complex (see Figure 31.13). [Note: In prokaryotes, three initiation factors are known (IF-1, IF-2, and IF-3), whereas in eukaryotes, there are many (designated eIF to indicate eukaryotic origin). Eukaryotes also require ATP for initiation.] The following are two mechanisms by which the ribosome recognizes the nucleotide sequence (AUG) that initiates translation.
1. Shine-Dalgarno sequence: In Escherichia coli (E. coli), a purine-rich sequence of nucleotide bases, known as the Shine-Dalgarno (SD) sequence, is located six to ten bases upstream of the initiating AUG codon on the mRNA molecule (that is, near its 5ʹ-end). The 16S rRNA component of the small (30S) ribosomal subunit has a nucleotide sequence near its 3-end that is complementary to all or part of the SD sequence. Therefore, the 5-end of the mRNA and the 3-end of the 16S rRNA can form complementary base pairs, facilitating the positioning of the small ribosomal subunit on the mRNA in close proximity to the initiating AUG codon (Figure 31.10).
2. 5ʹ Cap: Eukaryotic mRNAs do not have SD sequences. In eukaryotes, the small (40S) ribosomal subunit (aided by members of the elF-4 family of proteins) binds close to the cap structure at the 5-end of the mRNA and moves down the mRNA until it encounters the initiator AUG. This “scanning” process requires ATP. [Note: Interactions between the cap-binding eIF-4 proteins and the poly-A tail-binding proteins on eukaryotic mRNA mediate circularization of the mRNA and likely prevent the use of incompletely processed mRNA in translation.]
3. Initiation codon: The initiating AUG is recognized by a special initiator tRNA. Recognition is facilitated by IF-2-GTP in prokaryotes and eIF-2-GTP (plus additional eIFs) in eukaryotes. The charged initiator tRNA enters the P site on the small subunit. The initiator tRNA is the only tRNA recognized by (e)IF-2 and the only tRNA to go directly to the P site. In bacteria and in mitochondria, the initiator tRNA carries an N-formylated methionine (fMet, Figure 31.11). After Met is attached to the initiator tRNA, the formyl group is added by the enzyme transformylase, which uses N10-formyl tetrahydrofolate (see p. 267) as the carbon donor. In eukaryotes, the initiator tRNA carries a Met that is not formylated. In both prokaryotic and eukaryotic cells, this N-terminal Met is usually removed before translation is completed. The large ribosomal subunit then joins the complex, and a functional ribosome is formed with the charged initiating tRNA in the P site. The A site is empty. [Note: Specific (e)IFs function as anti-association factors and prevent premature addition of the large subunit.] The GTP on (e)IF-2 gets hydrolyzed to GDP. A guanine nucleotide exchange factor facilitates the reactivation of (e)IF-2-GDP through replacement of GDP by GTP.
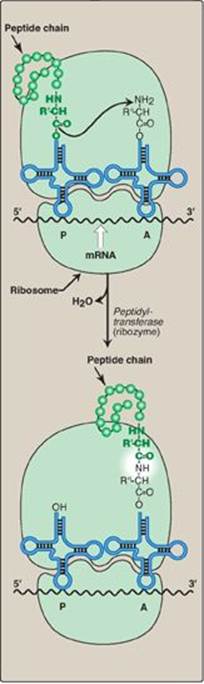
Figure 31.12 Formation of a peptide bond. Peptide bond formation involves transfer of the peptide on the transfer RNA (tRNA) in the P site to the amino acid on the tRNA in the A site (transpeptidation). mRNA = messenger RNA.
B. Elongation
Elongation of the polypeptide chain involves the addition of amino acids to the carboxyl end of the growing chain. During elongation, the ribosome moves from the 5ʹ-end to the 3ʹ-end of the mRNA that is being translated. Delivery of the aminoacyl-tRNA whose codon appears next on the mRNA template in the ribosomal A site (a process known as decoding) is facilitated in E. coli by elongation factors EF-Tu-GTP and EF-Ts and requires GTP hydrolysis. [Note: In eukaryotes, comparable elongation factors are EF-1a-GTP and EF-1bg. Both EF-Ts and EF-1bg function in guanine nucleotide exchange.] The formation of the peptide bond is catalyzed by peptidyltransferase, an activity intrinsic to the 23S rRNA found in the large (50S) ribosomal subunit (Figure 31.12). [Note: Because this rRNA catalyzes the reaction, it is referred to as a ribozyme.] After the peptide bond has been formed, what was attached to the tRNA at the P site is now linked to the amino acid on the tRNA at the A site. The ribosome then advances three nucleotides toward the 3ʹ-end of the mRNA. This process is known as translocation and, in prokaryotes, requires the participation of EF-G-GTP (eukaryotic cells use EF-2-GTP) and GTP hydrolysis. Translocation causes movement of the uncharged tRNA from the P to the E site for release and movement of the peptidyl-tRNA from the A to the P site. The process is repeated until a termination codon is encountered.
Figure 31.13 Steps in prokaryotic protein synthesis (translation), and their inhibition by antibiotics. [Note: EF-Ts is a guanine nucleotide exchange factor. It facilitates the removal of GDP, allowing its replacement by GTP. The eukaryotic equivalent is EF-1βγ.] fMet = formylated methionine; S = Svedberg unit; GTP = guanine nucleoside triphosphate; Phe = phenylalanine.
[Note: Ricin, a toxin from castor beans, removes an A from the 28 S rRNA in the large subunit of eukaryotic ribosomes, thereby inhibiting their function.] Lys = lysine; Arg = arginine.
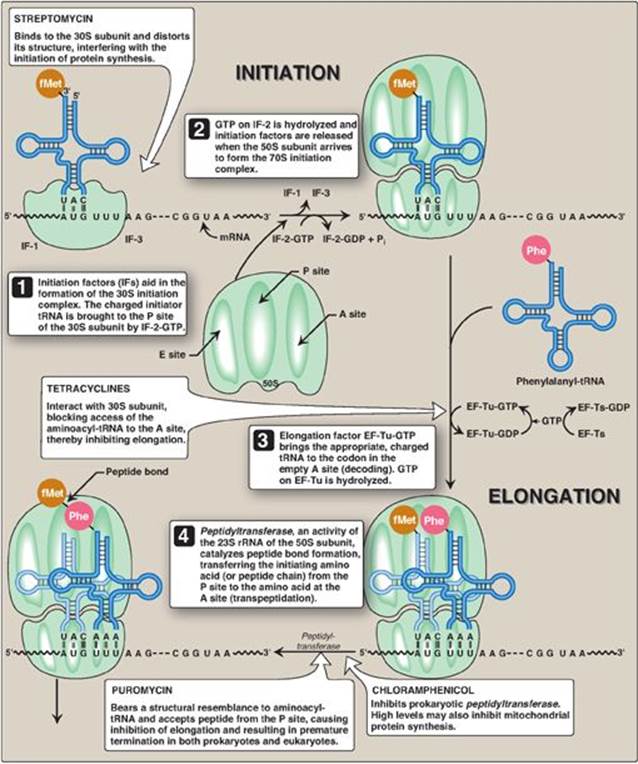
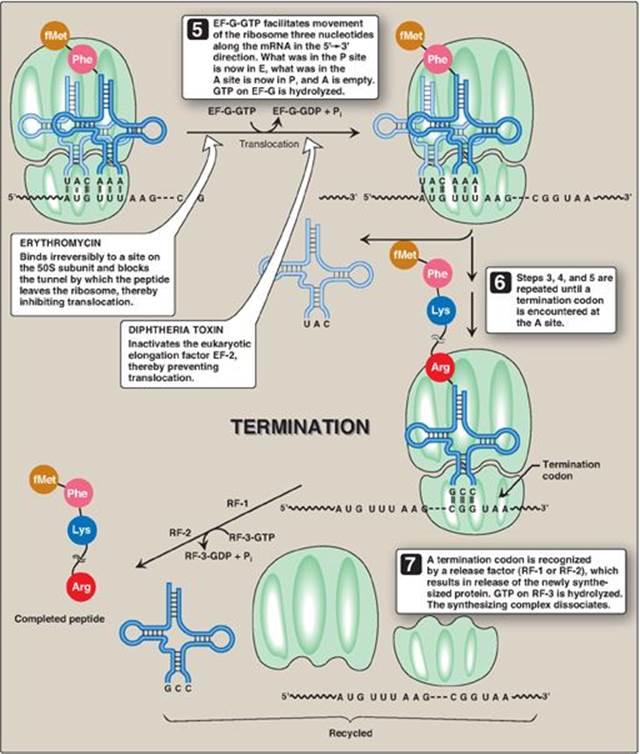
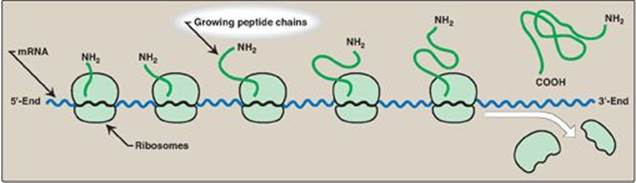
Figure 31.14 A polyribosome consists of several ribosomes simultaneously translating one messenger RNA (mRNA). [Note: Eukaryotic mRNA is circularized for translation.]
C. Termination
Termination occurs when one of the three termination codons moves into the A site. These codons are recognized in E. coli by release factors: RF-1, which recognizes the termination codons UAA and UAG, and RF-2, which recognizes UGA and UAA. The binding of these release factors results in hydrolysis of the bond linking the peptide to the tRNA at the P site, causing the nascent protein to be released from the ribosome. A third release factor, RF-3-GTP then causes the release of RF-1 or RF-2 as GTP is hydrolyzed (see Figure 31.13). [Note: Eukaryotes have a single release factor, eRF, which recognizes all three termination codons. A second factor, eRF-3, functions like the prokaryotic RF-3. See Figure 31.15 for a summary of the factors used in translation.] The steps in prokaryotic protein synthesis are summarized in Figure 31.13. The newly synthesized polypeptide may undergo further modification as described below, and the ribosomal subunits, mRNA, tRNA, and protein factors can be recycled and used to synthesize another polypeptide. [Note: In prokaryotes, ribosome recycling factors mediate separation of the subunits.] Some antibiotic inhibitors of protein synthesis are illustrated in Figure 31.13, as is diphtheria toxin.
Figure 31.15 Protein factors in the three stages of translation. ![]() = prokaryotes;
= prokaryotes; ![]() = eukaryotes; tRNA = transfer RNA; IF = initiation factor; EF = elongation factor; RF = release factor.
= eukaryotes; tRNA = transfer RNA; IF = initiation factor; EF = elongation factor; RF = release factor.

D. Polysomes
Translation begins at the 5ʹ-end of the mRNA, with the ribosome proceeding along the RNA molecule. Because of the length of most mRNAs, more than one ribosome at a time can translate a message (Figure 31.14). Such a complex of one mRNA and a number of ribosomes is called a polysome or polyribosome.
E. Regulation of translation
Gene expression is most commonly regulated at the transcriptional level, but translation may also be regulated. An important mechanism by which this is achieved in eukaryotes is by covalent modification of eIF-2: phosphorylated eIF-2 is inactive. In both eukaryotes and prokaryotes, regulation can also be achieved through proteins that bind mRNA and inhibit its use by blocking translation or extend its use by protecting it from degradation. For a more detailed discussion of the regulation of translation, see p. 454.
F. Protein targeting
Although most protein synthesis in eukaryotes is initiated in the cytoplasm, many proteins perform their functions within subcellular organelles or outside of the cell. Such proteins usually contain amino acid sequences that direct the proteins to their final locations. For example, proteins destined for secretion from the cell are targeted during their synthesis (cotranslational targeting) to the RER (see p. 436) by the presence of an N-terminal hydrophobic signal sequence. [Note: The sequence is recognized and bound by the signal recognition particle, which facilitates transport to the RER.] Proteins targeted after synthesis (posttranslational) include nuclear proteins that contain an internal, short, basic “nuclear localization signal” and mitochondrial matrix proteins that contain an N-terminal, amphipathic, α-helical “mitochondrial entry sequence.”
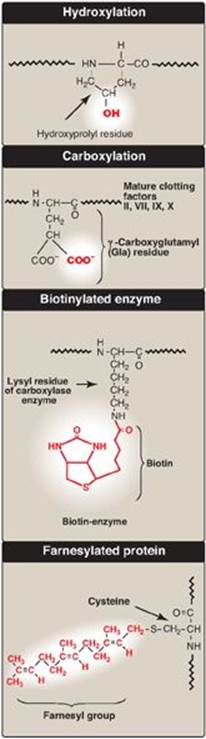
Figure 31.16 Covalent modifications of some amino acid residues.
VI. CO- AND POSTTRANSLATIONAL MODIFICATION OF POLYPEPTIDE CHAINS
Many polypeptide chains are covalently modified, either while they are still attached to the ribosome (cotranslational) or after their synthesis has been completed (posttranslational). These modifications may include removal of part of the translated sequence or the covalent addition of one or more chemical groups required for protein activity. Examples of such modifications are listed below.
A. Trimming
Many proteins destined for secretion from the cell are initially made as large, precursor molecules that are not functionally active. Portions of the protein chain must be removed by specialized endoproteases, resulting in the release of an active molecule. The cellular site of the cleavage reaction depends on the protein to be modified. Some precursor proteins are cleaved in the endoplasmic reticulum or the Golgi apparatus; others are cleaved in developing secretory vesicles (for example, insulin; see Figure 23.4, p. 309); and still others, such as collagen (see p. 47), are cleaved after secretion.
B. Covalent attachments
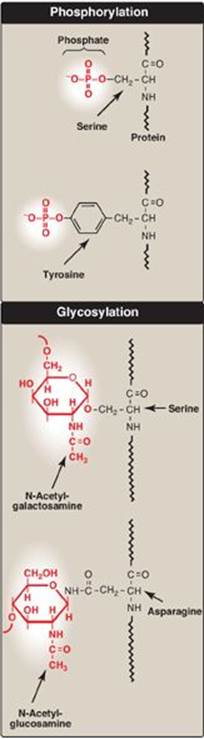
Proteins may be activated or inactivated by the covalent attachment of a variety of chemical groups (Figure 31.16). Examples include the following.
1. Phosphorylation: Phosphorylation occurs on the hydroxyl groups of serine; threonine; or, less frequently, tyrosine residues in a protein. This phosphorylation is catalyzed by one of a family of protein kinases and may be reversed by the action of cellular protein phosphatases. The phosphorylation may increase or decrease the functional activity of the protein. Several examples of phosphorylation reactions have been previously discussed (for example, see Chapter 11, p. 131, for the regulation of glycogen synthesis and degradation).
2. Glycosylation: Many of the proteins that are destined to become part of a plasma membrane or to be secreted from a cell have carbohydrate chains added en bloc to the amide nitrogen of asparagine (N-linked) or built sequentially on the hydroxyl groups of serine, threonine, or hydroxylysine (O-linked). N-glycosylation occurs in the endoplasmic reticulum and O-glycosyation in the Golgi. (The process of producing such glycoproteins was discussed on p. 165.) Glycosylation is also used to target proteins to the matrix of lysosomes. Lysosomal acid hydrolases are modified by the phosphorylation of mannose residues at carbon 6 (see p. 169).
3. Hydroxylation: Proline and lysine residues of the a chains of collagen are extensively hydroxylated by vitamin C–dependent hydroxylases in the endoplasmic reticulum (see p. 47).
4. Other covalent modifications: These may be required for the functional activity of a protein. For example, additional carboxyl groups can be added to glutamate residues by vitamin K–dependent carboxylation (see p. 389). The resulting g-carboxyglutamate (Gla) residues are essential for the activity of several of the blood-clotting proteins. (See online Chapter 34.) Biotin is covalently bound to the e-amino groups of lysine residues of biotin-dependent enzymes that catalyze carboxylation reactions such as pyruvate carboxylase (see p. 119). Attachment of lipids, such as farnesyl groups, can help anchor proteins to membranes. Many eukaryotic proteins are cotranslationally acetylated at the N-end. [Note: Reversible acetylation of histone proteins influences gene expression (see p. 409).]
C. Protein folding
Proteins must fold to assume their functional, native state. Folding can be spontaneous (as a result of the primary structure) or facilitated by proteins known as chaperones (see p. 20).
D. Protein degradation
Proteins that are defective (for example, misfolded) or destined for rapid turnover are often marked for destruction by ubiquitination, the attachment of chains of a small, highly conserved protein, called ubiquitin (see Figure 19.3on p. 247). Proteins marked in this way are rapidly degraded by a cellular component known as the proteasome, which is a macromolecular, ATP-dependent, proteolytic system located in the cytosol. [Note: The DF508 mutation seen in CF causes misfolding of the CFTR protein, resulting in its proteasomal degradation.]
VII. CHAPTER SUMMARY
Codons are composed of three nucleotide bases presented in the messenger (mRNA) language of adenine (A), guanine (G), cytosine (C), and uracil (U). They are always written 5ʹ→3ʹ. Of the 64 possible three-base combinations, 61 code for the 20 common amino acids and 3 signal termination of protein synthesis (translation). Altering the nucleotide sequence in a codon can cause silent mutations (the altered codon codes for the original amino acid), missense mutations (the altered codon codes for a different amino acid), or nonsense mutations (the altered codon is a termination codon). Characteristics of the genetic code include specificity, universality, and degeneracy, and it is nonoverlapping and commaless (Figure 31.17). Requirements for protein synthesis include all the amino acids that eventually appear in the finished protein, at least one specific type of transfer RNA (tRNA) for each amino acid, one aminoacyl-tRNA synthetase for each amino acid, the mRNA coding for the protein to be synthesized, fully competent ribosomes, protein factors needed for initiation, elongation, and termination of protein synthesis, and ATP and GTP as energy sources. tRNA has an attachment site for a specific amino acid at its 3ʹ-end, and an anticodon region that can recognize the codon specifying the amino acid the tRNA is carrying. Ribosomes are large complexes of protein and ribosomal (rRNA). They consist of two subunits. Each ribosome has three binding sites for tRNA molecules: the A, P, and E sites that cover three neighboring codons. The A-site codon binds an incoming aminoacyl-tRNA, the P-site codon is occupied by peptidyl-tRNA, and the E site is occupied by the empty tRNA as it is about to exit the ribosome. Recognition of an mRNA codon is accomplished by the tRNA anticodon. The anticodon binds to the codon following the rules of complementarity and antiparallel binding. (Nucleotide sequences are always assumed to be written in the 5ʹ to 3ʹ direction unless otherwise noted.) The “wobble” hypothesis states that the first (5ʹ) base of the anticodon is not as spatially defined as the other two bases. Movement of that first base allows nontraditional base-pairing with the last (3ʹ) base of the codon, thus allowing a single tRNA to recognize more than one codon for a specific amino acid. For initiation of protein synthesis, the components of the translation system are assembled, and mRNA associates with the small ribosomal subunit. The process requires initiation factors. In prokaryotes, a purine-rich region of the mRNA (the Shine-Dalgarno sequence) base-pairs with a complementary sequence on 16S rRNA, resulting in the positioning of the small subunit on the mRNA so that translation can begin. The 5ʹ-cap (bound by proteins of the eIF-4 family) on eukaryotic mRNA is used to position the small subunit on the mRNA. The initiation codon is AUG, and N-formylmethionine is the initiating amino acid in prokaryotes, whereas methionine is used in eukaryotes. The polypeptide chain is elongated by the addition of amino acids to the carboxyl end of its growing chain. The process requires elongation factors that facilitate the binding of the aminoacyl-tRNA to the A site as well as the movement of the ribosome along the mRNA. The formation of the peptide bond is catalyzed by peptidyltransferase, which is an activity intrinsic to the rRNA of the large subunit and, therefore, is a ribozyme. Following peptide bond formation, the ribosome advances along the mRNA in the 5ʹ→3ʹ direction to the next codon (translocation). Because of the length of most mRNAs, more than one ribosome at a time can translate a message, forming a polysome. Termination begins when one of the three termination codons moves into the A site. These codons are recognized by release factors. The newly synthesized protein is released from the ribosomal complex, and the ribosome is dissociated from the mRNA. Initiation, elongation, and termination are driven by the hydrolysis of GTP. Initiation in eukaryotes also requires ATP for scanning. Numerous antibiotics interfere with the process of protein synthesis. Many polypeptide chains are covalently modified during or after translation. Such modifications include removal of amino acids; phosphorylation, which may activate or inactivate the protein; glycosylation, which plays a role in protein targeting; and hydroxylation such as that seen in collagen. Proteins must fold to achieve their functional form. Folding can be spontaneous or facilitated by chaperones. Proteins that are defective (for example misfolded) or destined for rapid turnover are marked for destruction by the attachment of chains of a small, highly conserved protein called ubiquitin. Ubiquitinated proteins are rapidly degraded by a cytosolic complex known as the proteasome.
Figure 31.17 Key concept map for protein synthesis. mRNA = messenger RNA; tRNA = transfer RNA; A = adenine; G = guanine; C = cytosine; U = uracil.
Study Questions
Choose the ONE best answer.
31.1 A 20-year-old man with a microcytic anemia is found to have an abnormal form of β-globin (Hemoglobin Constant Spring) that is 172 amino acids long, rather than the 141 found in the normal protein. Which of the following point mutations is consistent with this abnormality?
A. CGA → UGA
B. GAU → GAC
C. GCA → GAA
D. UAA → CAA
E. UAA → UAG
Correct answer = D. Mutating the normal termination (stop) codon for β-globin from UAA to CAA causes the ribosome to insert a glutamine at that point. It will continue extending the protein chain until it comes upon the next stop codon further down the message, resulting in an abnormally long protein. The replacement of CGA (arginine) with UGA (stop) would cause the protein to be too short. GAU and GAC both encode aspartate and would cause no change in the protein. Changing GCA (alanine) to GAA (glutamate) would not change the size of the protein product. A change from UAA to UAG would simply change one termination codon for another, and would have no effect on the protein
31.2 A pharmaceutical company is studying a new antibiotic that inhibits bacterial protein synthesis. When this antibiotic is added to an in vitro protein synthesis system that is translating the messenger RNA sequence AUGUUUUUUUAG, the only product formed is the dipeptide fMet-Phe. What step in protein synthesis is most likely inhibited by the antibiotic?
A. Initiation
B. Binding of charged transfer RNA to the ribosomal A site
C. Peptidyltransferase activity
D. Ribosomal translocation
E. Termination
Correct answer = D. Because fMet-Phe is made, the ribosomes must be able to complete initiation, bind Phe-tRNA to the A site, and use peptidyltransferase activity to form the first peptide bond. Because the ribosome is not able to proceed any further, ribosomal movement (translocation) is most likely the inhibited step. The ribosome is, therefore, frozen before it reaches the termination codon of this message.
31.3 A transfer RNA (tRNA) molecule that is supposed to carry cysteine (tRNAcys) is mischarged, so that it actually carries alanine (ala-tRNAcys). Assuming no correction occurs, what will be the fate of this alanine residue during protein synthesis?
A. It will be incorporated into a protein in response to a codon for alanine.
B. It will be incorporated into a protein in response to a codon for cysteine.
C. It will be incorporated randomly at any codon.
D. It will remain attached to the tRNA because it cannot be used for protein synthesis.
E. It will be chemically converted to cysteine by cellular enzymes.
Correct answer = B. Once an amino acid is attached to a transfer (tRNA) molecule, only the anticodon of that tRNA determines the specificity of incorporation. The mischarged alanine will, therefore, be incorporated into the protein at a position determined by a cysteine codon.
31.4 In a patient with cystic fibrosis caused by the ∆F508 mutation, the mutant cystic fibrosis transmembrane conductance regulator (CFTR) protein folds incorrectly. The patientʼs cells modify this abnormal protein by attaching ubiquitin molecules to it. What is the fate of this modified CFTR protein?
A. It performs its normal function because the ubiquitin largely corrects for the effect of the mutation.
B. It is secreted from the cell.
C. It is placed into storage vesicles.
D. It is degraded by the proteasome.
E. It is repaired by cellular enzymes.
Correct answer = D. Ubiquitination usually marks old, damaged, or misfolded proteins for destruction by the cytosolic proteasome. There is no known cellular mechanism for repair of damaged proteins.
31.5 Many antimicrobials inhibit protein translation. Which of the following antimicrobials is correctly paired with its mechanism of action?
A. Erythromycin binds to the 60S ribosomal subunit.
B. Puromycin inactivates EF-2.
C. Streptomycin binds to the 30S ribosomal subunit.
D. Tetracyclines inhibit peptidyltransferase.
Correct answer = C. Streptomycin binds the 30S subunit and inhibits translation initiation. Erythromycin binds the 50S ribosomal subunit (60S denotes a eukaryote) and blocks the tunnel through which the peptide leaves the ribosome. Puromycin has structural similarity to aminoacyl-tRNA. It is incorporated into the growing chain, inhibits elongation, and results in premature termination in both prokaryotes and eukaryotes. Tetracyclines bind the 30S ribosomal subunit and block access to the A site, inhibiting elongation.
31.6 Translation of a synthetic polyribonucleotide containing the repeating sequence CAA in a cell-free protein-synthesizing system produces three homopolypeptides: polyglutamine, polyasparagine, and polythreonine. If the codons for glutamine and asparagine are CAA and AAC, respectively, which of the following triplets is the codon for threonine?
A. AAC
B. ACA
C. CAA
D. CAC
E. CCA
Correct answer = B. The synthetic polynucleotide sequence of CAACAACAACAA.. could be read by the in vitro protein synthesizing system starting at the first C, the first A, or the second A. In the first case, the first triplet codon would be CAA, which codes glutamine; in the second case, the first triplet codon would be AAC, which codes for asparagine; in the last case, the first triplet codon would be ACA, which codes for threonine.
31.7 Which of the following is required for both prokaryotic and eukaryotic protein synthesis?
A. Binding of the small ribosomal subunit to the Shine-Dalgarno sequence
B. fMet-tRNA
C. Movement of the messenger RNA out of the nucleus and into the cytoplasm
D. Recognition of the 5ʹ-cap by initiation factors.
E. Translocation of the peptidyl-tRNA from the A site to the P site
Correct answer = E. In both prokaryotes and eukaryotes, continued translation (elongation) requires movement of the peptidyl-tRNA from the A to the P site to allow the next aminoacyl-tRNA to enter the A site. Only prokaryotes have a Shine-Dalgarno sequence and use fMet, and only eukaryotes have a nucleus and co- and posttranscriptionally process their mRNA.
31.8 α1-Antitrypsin (AAT) deficiency can result in emphysema, a lung pathology, because the action of elastase, a serine protease, is unopposed. Deficiency of AAT in the lungs is the consequence of impaired secretion from the liver, the site of its synthesis. Proteins such as AAT that are destined to be secreted are best characterized by which of the following statements?
A. Their synthesis is initiated on the smooth endoplasmic reticulum.
B. They contain a mannose 6-phosphate targeting signal.
C. They always contain methionine as the N-terminal amino acid.
D. They are produced from translation products that have an N-terminal hydrophobic signal sequence.
E. They contain no sugars with O-glycosidic linkages because their synthesis does not involve the Golgi apparatus.
Correct answer = D. Synthesis of secreted proteins is begun on free (cytosolic) ribosomes. As the N-terminal signal sequence of the peptide emerges from the ribosome, it is bound by the signal recognition particle, taken to the rough endoplasmic reticulum (RER), threaded into the lumen, and removed as translation continues. The proteins move through the RER and the Golgi, and undergo processing such as N-glycosylation (RER) and O-glycosylation (Golgi). In the Golgi, they are packaged in secretory vesicles and released from the cell. The smooth endoplasmic reticulum is associated with synthesis of lipids, not proteins, and has no ribosomes attached. Phosphorylation at carbon 6 of terminal mannose residues in glycoproteins targets these proteins (acid hydrolases) to lysosomes. The N-terminal methionine is removed from most proteins during processing.
31.9 Why is the genetic code described both as degenerate and unambiguous?
A given amino acid can be coded for by more than one codon (degenerate code), but a given codon codes for just one particular amino acid (unambiguous code).