Harper’s Illustrated Biochemistry, 29th Edition (2012)
SECTION IV. Structure, Function, & Replication of Informational Macromolecules
Chapter 37. Protein Synthesis & the Genetic Code
P. Anthony Weil, PhD
OBJECTIVES
After studying this chapter, you should be able to:
![]() Understand that the genetic code is a three-letter nucleotide code, which is encoded in the linear array of the exon DNA (composed of triplets of A, G, C, and T) of protein coding genes, and that this three-letter code is translated into mRNA (composed of triplets of A, G, C, and U) to specify the linear order of amino acid addition during protein synthesis via the process of translation.
Understand that the genetic code is a three-letter nucleotide code, which is encoded in the linear array of the exon DNA (composed of triplets of A, G, C, and T) of protein coding genes, and that this three-letter code is translated into mRNA (composed of triplets of A, G, C, and U) to specify the linear order of amino acid addition during protein synthesis via the process of translation.
![]() Appreciate that the universal genetic code is degenerate, unambiguous, nonoverlapping, and punctuation free.
Appreciate that the universal genetic code is degenerate, unambiguous, nonoverlapping, and punctuation free.
![]() Explain that the genetic code is composed of 64 codons, 61 of which encode amino acids while 3 induce the termination of protein synthesis.
Explain that the genetic code is composed of 64 codons, 61 of which encode amino acids while 3 induce the termination of protein synthesis.
![]() Explain how the transfer RNAs (tRNAs) serve as the ultimate informational agents that decode the genetic code of mRNAs.
Explain how the transfer RNAs (tRNAs) serve as the ultimate informational agents that decode the genetic code of mRNAs.
![]() Understand the mechanism of the energy-intensive process of protein synthesis that occurs on RNA-protein complexes termed ribosomes.
Understand the mechanism of the energy-intensive process of protein synthesis that occurs on RNA-protein complexes termed ribosomes.
![]() Appreciate that protein synthesis, like DNA replication and transcription, is precisely controlled through the action of multiple accessory factors that are responsive to multiple extra- and intracellular regulatory signaling inputs.
Appreciate that protein synthesis, like DNA replication and transcription, is precisely controlled through the action of multiple accessory factors that are responsive to multiple extra- and intracellular regulatory signaling inputs.
BIOMEDICAL IMPORTANCE
The letters A, G, T, and C correspond to the nucleotides found in DNA. Within the protein-coding genes, these nucleotides are organized into three-letter code words called codons, and the collection of these codons makes up the genetic code. It was impossible to understand protein synthesis—or to explain mutations—before the genetic code was elucidated. The code provides a foundation for explaining the way in which protein defects may cause genetic disease and for the diagnosis and perhaps the treatment of these disorders. In addition, the pathophysiology of many viral infections is related to the ability of these infectious agents to disrupt host cell protein synthesis. Many antibacterial drugs are effective because they selectively disrupt protein synthesis in the invading bacterial cell but do not affect protein synthesis in eukaryotic cells.
GENETIC INFORMATION FLOWS FROM DNA TO RNA TO PROTEIN
The genetic information within the nucleotide sequence of DNA is transcribed in the nucleus into the specific nucleotide sequence of an RNA molecule. The sequence of nucleotides in the RNA transcript is complementary to the nucleotide sequence of the template strand of its gene in accordance with the base-pairing rules. Several different classes of RNA combine to direct the synthesis of proteins.
In prokaryotes there is a linear correspondence between the gene, the messenger RNA (mRNA) transcribed from the gene, and the polypeptide product. The situation is more complicated in higher eukaryotic cells, in which the primary transcript is much larger than the mature mRNA. The large mRNA precursors contain coding regions (exons) that will form the mature mRNA and long intervening sequences (introns) that separate the exons. The mRNA is processed within the nucleus, and the introns, which make up much more of this RNA than the exons, are removed. Exons are spliced together to form mature mRNA, which is transported to the cytoplasm, where it is translated into protein.
The cell must possess the machinery necessary to translate information accurately and efficiently from the nucleotide sequence of an mRNA into the sequence of amino acids of the corresponding specific protein. Clarification of our understanding of this process, which is termed translation, awaited deciphering of the genetic code. It was realized early that mRNA molecules themselves have no affinity for amino acids and, therefore, that the translation of the information in the mRNA nucleotide sequence into the amino acid sequence of a protein requires an intermediate adapter molecule. This adapter molecule must recognize a specific nucleotide sequence on the one hand as well as a specific amino acid on the other. With such an adapter molecule, the cell can direct a specific amino acid into the proper sequential position of a protein during its synthesis as dictated by the nucleotide sequence of the specific mRNA. In fact, the functional groups of the amino acids do not themselves actually come into contact with the mRNA template.
THE NUCLEOTIDE SEQUENCE OF AN mRNA MOLECULE CONTAINS A SERIES OF CODONS THAT SPECIFY THE AMINO ACID SEQUENCE OF THE ENCODED PROTEIN
Twenty different amino acids are required for the synthesis of the cellular complement of proteins; thus, there must be at least 20 distinct codons that make up the genetic code. Since there are only four different nucleotides in mRNA, each codon must consist of more than a single purine or pyrimidine nucleotide. Codons consisting of two nucleotides each could provide for only 16 (42)-specific codons, whereas codons of three nucleotides could provide 64 (43)-specific codons.
It is now known that each codon consists of a sequence of three nucleotides; that is, it is a triplet code (see Table 37-1). The initial deciphering of the genetic code depended heavily on in vitro synthesis of nucleotide polymers, particularly triplets in repeated sequence. These synthetic triplet ribonucleotides were used as mRNAs to program protein synthesis in the test tube, and allowed investigators to deduce the genetic code.
TABLE 37–1 The Genetic Code1 (Codon Assignments in Mammalian Messenger RNAs)
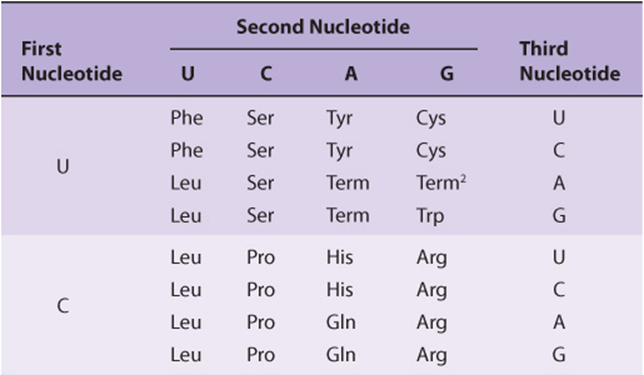
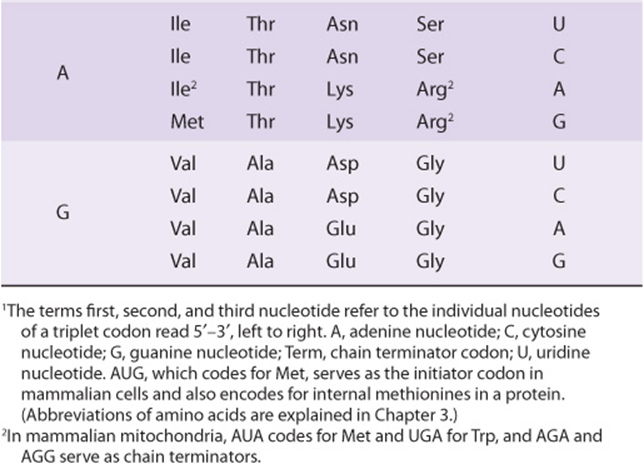
THE GENETIC CODE IS DEGENERATE, UNAMBIGUOUS, NONOVERLAPPING, WITHOUT PUNCTUATION, & UNIVERSAL
Three of the 64 possible codons do not code for specific amino acids; these have been termed nonsense codons. These nonsense codons are utilized in the cell as termination signals; they specify where the polymerization of amino acids into a protein molecule is to stop. The remaining 61 codons code for the 20 naturally occurring amino acids (Table 37-1). Thus, there is “degeneracy” in the genetic code—that is, multiple codons decode the same amino acid. Some amino acids are encoded by several codons; for example six different codons, UCU, UCC, UCA, UCG, AGU, and AGC all specify serine. Other amino acids, such as methionine and tryptophan, have a single codon. In general, the third nucleotide in a codon is less important than the first two in determining the specific amino acid to be incorporated, and this accounts for most of the degeneracy of the code. However, for any specific codon, only a single amino acid is indicated; with rare exceptions, the genetic code is unambiguous—that is, given a specific codon, only a single amino acid is indicated. The distinction between ambiguity and degeneracy is an important concept.
The unambiguous but degenerate code can be explained in molecular terms. The recognition of specific codons in the mRNA by the tRNA adapter molecules is dependent upon their anticodon region and specific base-pairing rules. Each tRNA molecule contains a specific sequence, complementary to a codon, which is termed its anticodon. For a given codon in the mRNA, only a single species of tRNA molecule possesses the proper anticodon. Since each tRNA molecule can be charged with only one specific amino acid, each codon therefore specifies only one amino acid. However, some tRNA molecules can utilize the anticodon to recognize more than one codon. With few exceptions, given a specific codon, only a specific amino acid will be incorporated—although, given a specific amino acid, more than one codon may be used.
As discussed below, the reading of the genetic code during the process of protein synthesis does not involve any overlap of codons. Thus, the genetic code is nonoverlapping. Furthermore, once the reading is commenced at a specific codon, there is no punctuation between codons, and the message is read in a continuing sequence of nucleotide triplets until a translation stop codon is reached.
Until recently, the genetic code was thought to be universal. It has now been shown that the set of tRNA molecules in mitochondria (which contain their own separate and distinct set of translation machinery) from lower and higher eukaryotes, including humans, reads four codons differently from the tRNA molecules in the cytoplasm of even the same cells. As noted in Table 37-1, the codon AUA is read as Met, and UGA codes for Trp in mammalian mitochondria. In addition, in mitochondria, the codons AGA and AGG are read as stop or chain terminator codons rather than as Arg. As a result of these organelle-specific changes in genetic code, mitochondria require only 22 tRNA molecules to read their genetic code, whereas the cytoplasmic translation system possesses a full complement of 31 tRNA species. These exceptions noted, the genetic code is universal. The frequency of use of each amino acid codon varies considerably between species and among different tissues within a species. The specific tRNA levels generally mirror these codon usage biases. Thus, a particular abundantly used codon is decoded by a similarly abundant-specific tRNA which recognizes that particular codon. Tables of codon usage are becoming more accurate as more genes and genomes are sequenced; such information can prove vital for large-scale production of proteins for therapeutic purposes (ie, insulin, erythropoietin). Such proteins are often produced in nonhuman cells using recombinant DNA technology (Chapter 39). The main features of the genetic code are listed in Table 37-2.
TABLE 37–2 Features of the Genetic Code

AT LEAST ONE SPECIES OF TRANSFER RNA (tRNA) EXISTS FOR EACH OF THE 20 AMINO ACIDS
tRNA molecules have extraordinarily similar functions and three-dimensional structures. The adapter function of the tRNA molecules requires the charging of each specific tRNA with its specific amino acid. Since there is no affinity of nucleic acids for specific functional groups of amino acids, this recognition must be carried out by a protein molecule capable of recognizing both a specific tRNA molecule and a specific amino acid. At least 20-specific enzymes are required for these specific recognition functions and for the proper attachment of the 20 amino acids to specific tRNA molecules. The energy requiring process of recognition and attachment (charging) proceeds in two steps and is catalyzed by one enzyme for each of the 20 amino acids. These enzymes are termed aminoacyl-tRNA synthetases. They form an activated intermediate of aminoacyl-AMP-enzyme complex (Figure 37–1). The specific aminoacyl-AMP-enzyme complex then recognizes a specific tRNA to which it attaches the aminoacyl moiety at the 3′-hydroxyl adenosyl terminal. The charging reactions have an error rate of less than 10-4 and so are quite accurate. The amino acid remains attached to its specific tRNA in an ester linkage until it is polymerized at a specific position in the fabrication of a polypeptide precursor of a protein molecule.
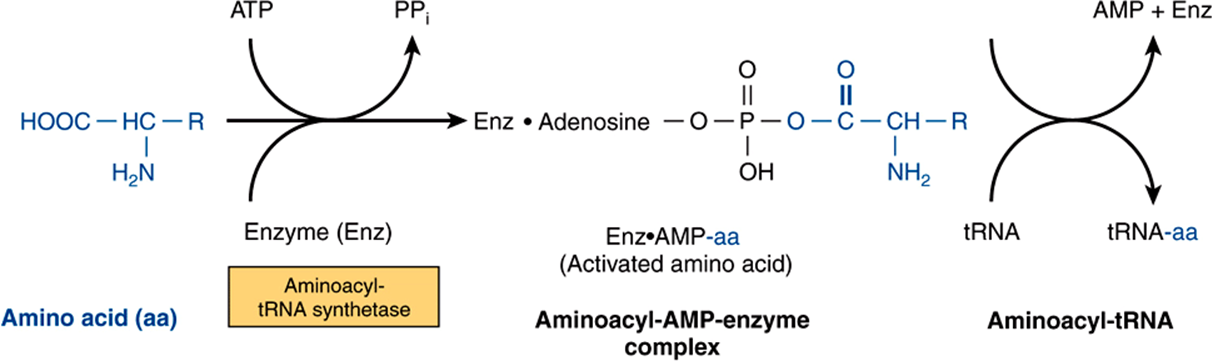
FIGURE 37–1 Formation of aminoacyl-tRNA. A two-step reaction, involving the enzyme amino-acyl-tRNA synthetase, results in the formation of aminoacyl-tRNA. The first reaction involves the formation of an AMP-amino acid-enzyme complex. This activated amino acid is next transferred to the corresponding tRNA molecule. The AMP and enzyme are released, and the latter can be reutilized. The charging reactions have an error rate (ie, esterifying the incorrect amino acid on tRNAx) of less than 10-4.
The regions of the tRNA molecule referred to in Chapter 34 (and illustrated in Figure 34–11) now become important. The ribothymidine pseudouridine cytidine (TψC) arm is involved in binding of the aminoacyl-tRNA to the ribosomal surface at the site of protein synthesis. The D arm is one of the sites important for the proper recognition of a given tRNA species by its proper aminoacyl-tRNA synthetase. The acceptor arm, located at the 3′-hydroxyl adenosyl terminal, is the site of attachment of the specific amino acid.
The anticodon region consists of seven nucleotides, and it recognizes the three-letter codon in mRNA (Figure 37–2). The sequence read from the 3′-5’ direction in that anticodon loop consists of a variable base-modified purine-XYZ-pyrimidine-pyrimidine-5’. Note that this direction of reading the anticodon is 3′-5’, whereas the genetic code in Table 37-1 is read 5′-3’, since the codon and the anticodon loop of the mRNA and tRNA molecules, respectively, are antiparallel in their complementarity just like all other intermolecular interactions between nucleic acid strands.
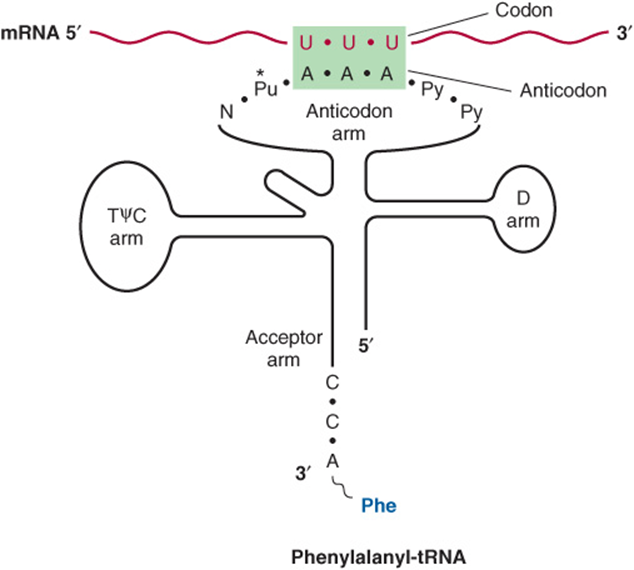
FIGURE 37–2 Recognition of the codon by the anticodon. One of the codons for phenylalanine is UUU. tRNA charged with phenylalanine (Phe) has the complementary sequence AAA; hence, it forms a base-pair complex with the codon. The anticodon region typically consists of a sequence of seven nucleotides: variable (N), modified purine (Pu*), X, Y, Z (here, A A A), and two pyrimidines (Py) in the 3′ -5’ direction.
The degeneracy of the genetic code resides mostly in the last nucleotide of the codon triplet, suggesting that the base pairing between this last nucleotide and the corresponding nucleotide of the anticodon is not strictly by the Watson-Crick rule. This is called wobble; the pairing of the codon and anti-codon can “wobble” at this specific nucleotide-to-nucleotide pairing site. For example, the two codons for arginine, AGA and AGG, can bind to the same anticodon having a uracil at its 5′ end (UCU). Similarly, three codons for glycine—GGU, GGC, and GGA—can form a base pair from one anticodon, 3′ CCI 5′ (ie, I can base pair with U, C and A). I is a purine inosine nucleotide generated by deamination of adenine (see Figure 33–2 for structure), another of the peculiar bases often appearing in tRNA molecules.
MUTATIONS RESULT WHEN CHANGES OCCUR IN THE NUCLEOTIDE SEQUENCE
Although the initial change may not occur in the template strand of the double-stranded DNA molecule for that gene, after replication, daughter DNA molecules with mutations in the template strand will segregate and appear in the population of organisms.
Some Mutations Occur by Base Substitution
Single-base changes (point mutations) may be transitions or transversions. In the former, a given pyrimidine is changed to the other pyrimidine or a given purine is changed to the other purine. Transversions are changes from a purine to either of the two pyrimidines or the change of a pyrimidine into either of the two purines, as shown in Figure 37–3.
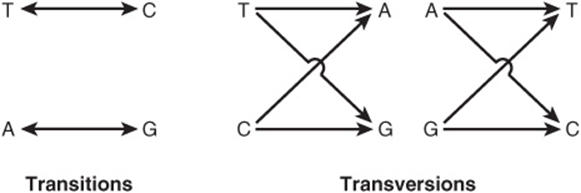
FIGURE 37–3 Diagrammatic representation of transition mutations and transversion mutations.
If the nucleotide sequence of the gene containing the mutation is transcribed into an RNA molecule, then the RNA molecule will of course possess the base change at the corresponding location.
Single-base changes in the mRNA molecules may have one of several effects when translated into protein:
1. There may be no detectable effect because of the degeneracy of the code; such mutations are often referred to as silent mutations. This would be more likely if the changed base in the mRNA molecule were to be at the third nucleotide of a codon. Because of wobble, the translation of a codon is least sensitive to a change at the third position.
2. A missense effect will occur when a different amino acid is incorporated at the corresponding site in the protein molecule. This mistaken amino acid—or missense, depending upon its location in the specific protein—might be acceptable, partially acceptable, or unacceptable to the function of that protein molecule. From a careful examination of the genetic code, one can conclude that most single-base changes would result in the replacement of one amino acid by another with rather similar functional groups. This is an effective mechanism to avoid drastic change in the physical properties of a protein molecule. If an acceptable missense effect occurs, the resulting protein molecule may not be distinguishable from the normal one. A partially acceptable missense will result in a protein molecule with partial but abnormal function. If an unacceptable missense effect occurs, then the protein molecule will not be capable of functioning normally.
3. A nonsense codon may appear that would then result in the premature termination of amino acid incorporation into a peptide chain and the production of only a fragment of the intended protein molecule. The probability is high that a prematurely terminated protein molecule or peptide fragment will not function in its assigned role. Examples of the different types of mutations, and their effects on the coding potential of mRNA are shown in Figures 37-4 and 37-5.
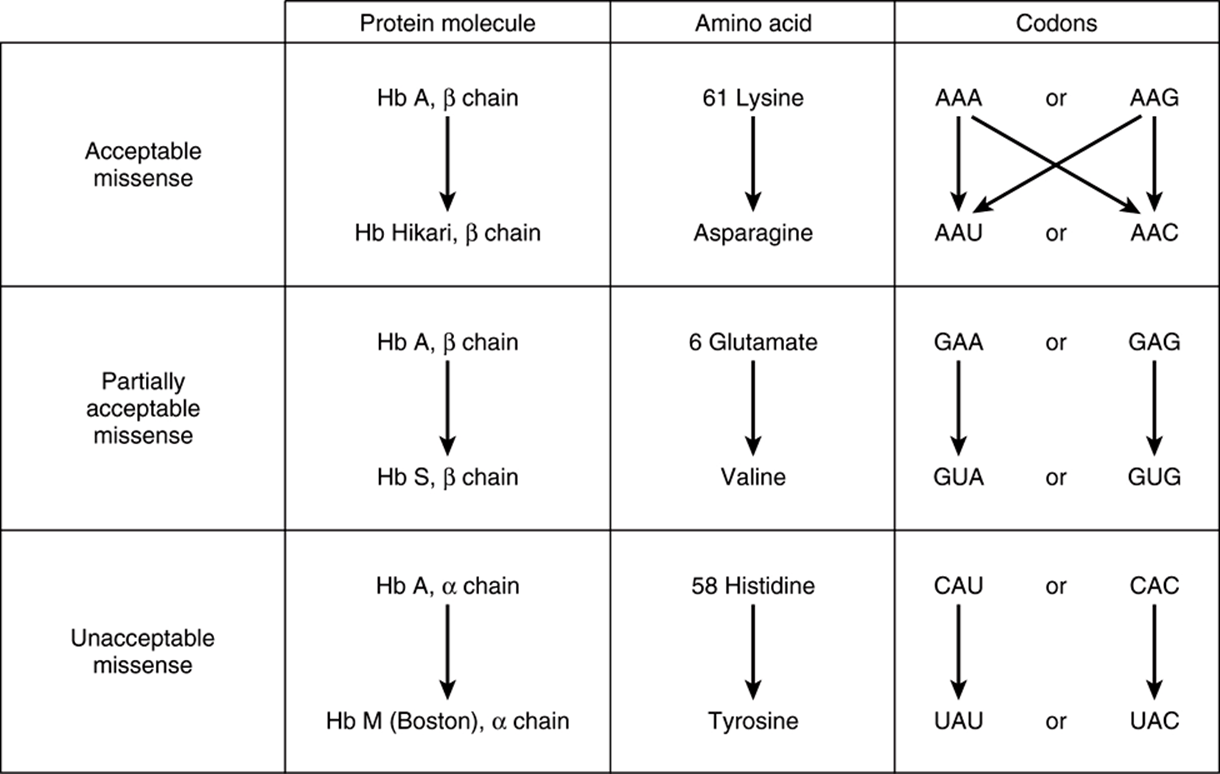
FIGURE 37–4 Examples of three types of missense mutations resulting in abnormal hemoglobin chains. The amino acid alterations and possible alterations in the respective codons are indicated. The hemoglobin Hikari β-chain mutation has apparently normal physiologic properties but is electrophoretically altered. Hemoglobin S has a β-chain mutation and partial function; hemoglobin S binds oxygen but precipitates when deoxygenated; this causes red blood cells to sickle, and represents the cellular and molecular basis of sickle cell disease (see Figure 6–12). Hemoglobin M Boston, an α-chain mutation, permits the oxidation of the heme ferrous iron to the ferric state and so will not bind oxygen at all.
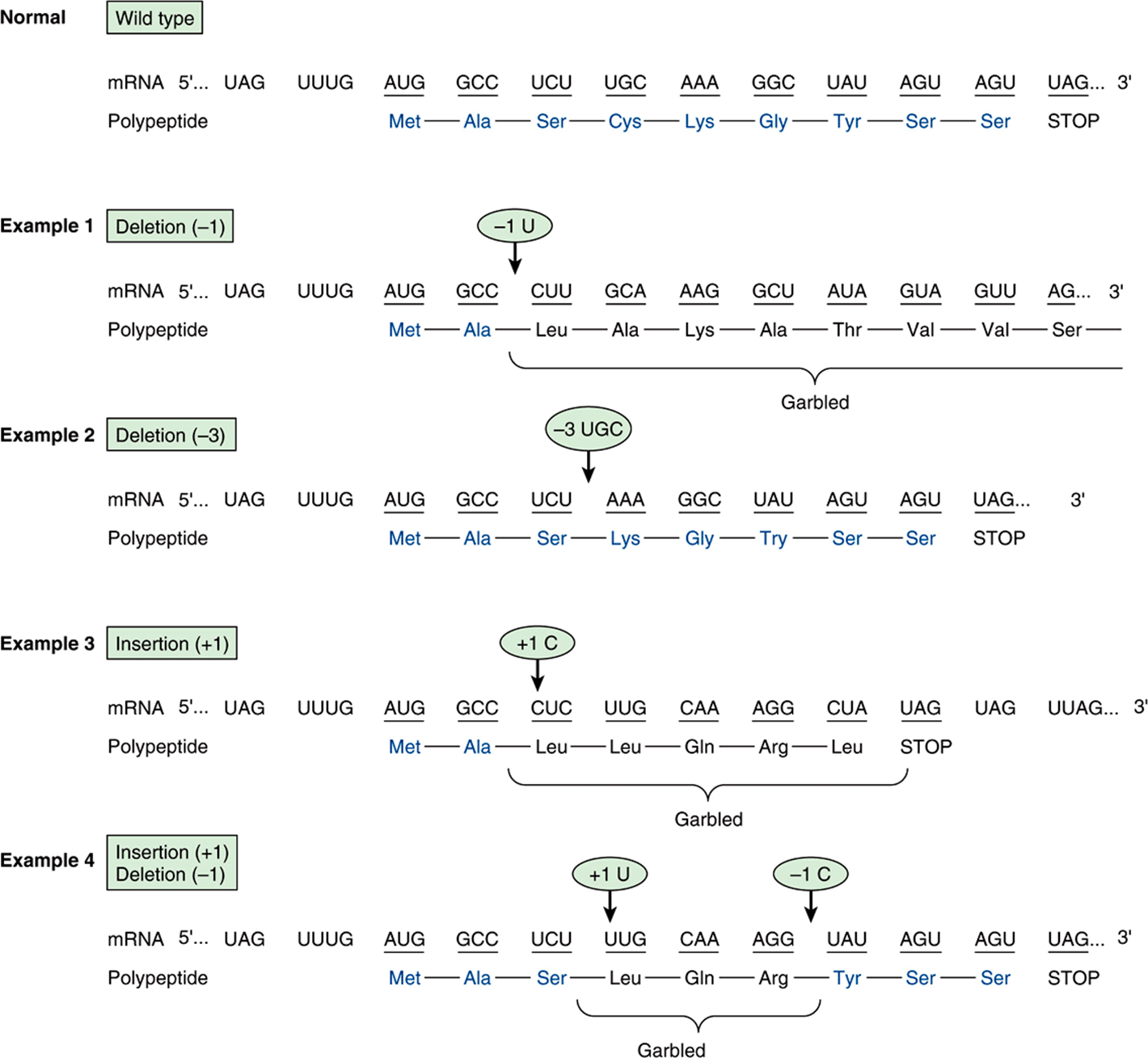
FIGURE 37–5 Examples of the effects of deletions and insertions in a gene on the sequence of the mRNA transcript and of the polypeptide chain translated therefrom. The arrows indicate the sites of deletions or insertions, and the numbers in the ovals indicate the number of nucleotide residues deleted or inserted. Colored type indicates amino acids in correct order.
Frameshift Mutations Result from Deletion or Insertion of Nucleotides in DNA That Generates Altered mRNAs
The deletion of a single nucleotide from the coding strand of a gene results in an altered reading frame in the mRNA. The machinery translating the mRNA does not recognize that a base was missing, since there is no punctuation in the reading of codons. Thus, a major alteration in the sequence of polymerized amino acids, as depicted in example 1, Figure 37–5, results. Altering the reading frame results in a garbled translation of the mRNA distal to the single nucleotide deletion. Not only is the sequence of amino acids distal to this deletion garbled, but reading of the message can also result in the appearance of a nonsense codon and thus the production of a polypeptide both garbled and prematurely terminated (example 3, Figure 37–5).
If three nucleotides or a multiple of three are deleted from a coding region, the corresponding mRNA when translated will provide a protein from which is missing the corresponding number of amino acids (example 2, Figure 37–5). Because the reading frame is a triplet, the reading phase will not be disturbed for those codons distal to the deletion. If, however, deletion of one or two nucleotides occurs just prior to or within the normal termination codon (nonsense codon), the reading of the normal termination signal is disturbed. Such a deletion might result in reading through the now “mutated” termination signal until another nonsense codon is encountered (example 1, Figure 37–5).
Insertions of one or two or nonmultiples of three nucleotides into a gene result in an mRNA in which the reading frame is distorted upon translation, and the same effects that occur with deletions are reflected in the mRNA translation. This may result in garbled amino acid sequences distal to the insertion and the generation of a nonsense codon at or distal to the insertion, or perhaps reading through the normal termination codon. Following a deletion in a gene, an insertion (or vice versa) can reestablish the proper reading frame (example 4, Figure 37–5). The corresponding mRNA, when translated, would contain a garbled amino acid sequence between the insertion and deletion. Beyond the reestablishment of the reading frame, the amino acid sequence would be correct. One can imagine that different combinations of deletions, of insertions, or of both would result in formation of a protein wherein a portion is abnormal, but this portion is surrounded by the normal amino acid sequences. Such phenomena have been demonstrated convincingly in a number of human diseases.
Suppressor Mutations Can Counteract Some of the Effects of Missense, Nonsense, & Frameshift Mutations
The above discussion of the altered protein products of gene mutations is based on the presence of normally functioning tRNA molecules. However, in prokaryotic and lower eukaryotic organisms, abnormally functioning tRNA molecules have been discovered that are themselves the results of mutations. Some of these abnormal tRNA molecules are capable of binding to and decoding altered codons, thereby suppressing the effects of mutations in distinct-mutated mRNA-encoding structural genes. These suppressor tRNA molecules, usually formed as a result of alterations in their anticodon regions, are capable of suppressing certain missense mutations, nonsense mutations, and frameshift mutations. However, since the suppressor tRNA molecules are not capable of distinguishing between a normal codon and one resulting from a gene mutation, their presence in the microbial cell usually results in decreased viability. For instance, the nonsense suppressor tRNA molecules can suppress the normal termination signals to allow a read-through when it is not desirable. Frameshift suppressor tRNA molecules may read a normal codon plus a component of a juxtaposed codon to provide a frameshift, also when it is not desirable. Suppressor tRNA molecules may exist in mammalian cells, since read-through of translation has on occasion been observed. In the laboratory context such suppressor tRNAs, coupled with mutated variants of aminoacyl tRNA synthetases, can be utilized to incorporate unnatural amino acids into defined locations within altered genes that carry engineered nonsense mutations. The resulting labeled proteins can be used for in vivo and in vitro cross-linking and biophysical studies. This new tool adds significantly to biologists interested in studying the mechanisms of a wide range of biological processes.
LIKE TRANSCRIPTION, PROTEIN SYNTHESIS CAN BE DESCRIBED IN THREE PHASES: INITIATION, ELONGATION, & TERMINATION
The general structural characteristics of ribosomes and their self-assembly process are discussed in Chapter 34. These particulate entities serve as the machinery on which the mRNA nucleotide sequence is translated into the sequence of amino acids of the specified protein. The translation of the mRNA commences near its 5′ terminal with the formation of the corresponding amino terminal of the protein molecule. The message is read from 5′-3′, concluding with the formation of the carboxyl terminal of the protein. Again, the concept of polarity is apparent. As described in Chapter 36, the transcription of a gene into the corresponding mRNA or its precursor first forms the 5′ terminal of the RNA molecule. In prokaryotes, this allows for the beginning of mRNA translation before the transcription of the gene is completed. In eukaryotic organisms, the process of transcription is a nuclear one; mRNA translation occurs in the cytoplasm. This precludes simultaneous transcription and translation in eukaryotic organisms and makes possible the processing necessary to generate mature mRNA from the primary transcript.
Initiation Involves Several Protein-RNA Complexes
Initiation of protein synthesis requires that an mRNA molecule be selected for translation by a ribosome (Figure 37–6). Once the mRNA binds to the ribosome, the latter finds the correct reading frame on the mRNA, and translation begins. This process involves tRNA, rRNA, mRNA, and at least 10 eukaryotic initiation factors (eIFs), some of which have multiple (three to eight) subunits. Also involved are GTP, ATP, and amino acids. Initiation can be divided into four steps: (1) dissociation of the ribosome into its 40S and 60S subunits; (2) binding of a ternary complex consisting of the initiator methionyl-tRNA, (met-tRNAi), GTP, and eIF-2 to the 40S ribosome to form the 43S preinitiation complex; (3) binding of mRNA to the 40S preinitiation complex to form the 48S initiation complex; and (4) combination of the 48S initiation complex with the 60S ribosomal subunit to form the 80S initiation complex.
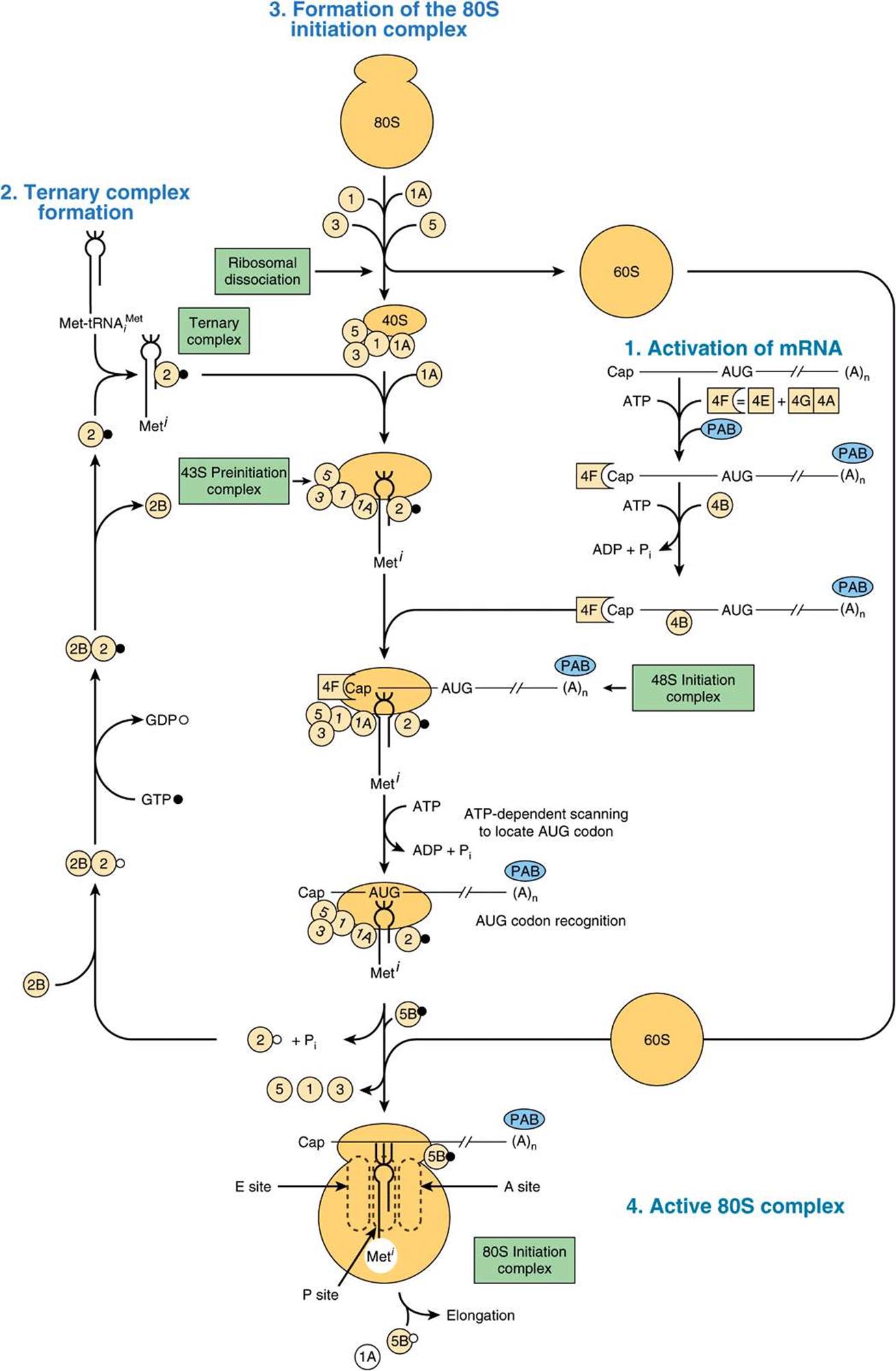
FIGURE 37–6 Diagrammatic representation of the initiation phase of protein synthesis on an eukaryotic mRNA template containing a 5′ cap (Cap) and 3′ poly(A) terminal [(A)n]. This process proceeds in several steps: (1) activation of mRNA (right); (2) formation of the ternary complex consisting of met-tRNA1, initiation factor eIF-2, and GTP (left); (3) scanning in the 43S complex to locate the AUG initiator coding, forming the 48S initiation complex (center); and (4) formation of the active 80S initiation complex (bottom, center). (See text for details.) (GTP, •; GDP,°.) The various initiation factors appear in abbreviated form as circles or squares, for example, eIF-3, ![]() , eIF-4F, (4F),
, eIF-4F, (4F), ![]() 4-F is a complex consisting of 4E and 4A bound to 4G (see Figure 37–7). The poly A binding protein, which interacts with the mRNA 3′-poly A tail, is abbreviated PAB. The constellation of protein factors and the 40S ribosomal subunit comprise the 43S preinitiation complex. When bound to mRNA, this forms the 48S preinitiation complex.
4-F is a complex consisting of 4E and 4A bound to 4G (see Figure 37–7). The poly A binding protein, which interacts with the mRNA 3′-poly A tail, is abbreviated PAB. The constellation of protein factors and the 40S ribosomal subunit comprise the 43S preinitiation complex. When bound to mRNA, this forms the 48S preinitiation complex.
Ribosomal Dissociation
Two initiation factors, eIF-3 and eIF-1A, bind to the newly dissociated 40S ribosomal subunit. This delays its reassociation with the 60S subunit and allows other translation initiation factors to associate with the 40S subunit.
Formation of the 43S Preinitiation Complex
The first step in this process involves the binding of GTP by eIF-2. This binary complex then binds to met tRNA’, a tRNA specifically involved in binding to the initiation codon AUG. (There are two tRNAs for methionine. One specifies methionine for the initiator codon, the other for internal methionines. Each has a unique nucleotide sequence; both are aminoacylated by the same methionyl-tRNA synthetase.) This ternary complex binds to the 40S ribosomal subunit to form the 43S preinitiation complex, which is stabilized by association with eIF-3 and eIF-1A.
eIF-2 is one of two control points for protein synthesis initiation in eukaryotic cells. eIF-2 consists of α, β, and γ subunits. eIF-2α is phosphorylated (on serine 51) by at least four different protein kinases (HCR, PKR, PERK, and GCN2) that are activated when a cell is under stress and when the energy expenditure required for protein synthesis would be deleterious. Such conditions include amino acid and glucose starvation, virus infection, intracellular presence of large quantities of misfolded proteins, serum deprivation, hyperosmolality, and heat shock. PKR is particularly interesting in this regard. This kinase is activated by viruses and provides a host defense mechanism that decreases protein synthesis, including viral protein synthesis, thereby inhibiting viral replication. Phosphorylated eIF-2α binds tightly to and inactivates the GTP-GDP recycling protein eIF-2B. Thus preventing formation of the 43S preinitiation complex and blocking protein synthesis.
Formation of the 48S Initiation Complex
The 5′ terminals of most mRNA molecules in eukaryotic cells are “capped,” as described in Chapter 36. This methyl-guanosyl triphosphate cap facilitates the binding of mRNA to the 43S preinitiation complex. A cap-binding protein complex, eIF-4F (4F), which consists of eIF-4E (4E) and the eIF-4G (4G) -eIF4A (4A) complex, binds to the cap through the 4E protein. Then eIF-4B (4B) binds and reduces the complex secondary structure of the 5′ end of the mRNA through ATPase and ATP-dependent helicase activities. The association of mRNA with the 43S preinitiation complex to form the 48S initiation complex requires ATP hydrolysis. eIF-3 is a key protein because it binds with high affinity to the 4G component of 4F, and it links this complex to the 40S ribosomal subunit. Following association of the 43S preinitiation complex with the mRNA cap, and reduction (“melting”) of the secondary structure near the 5′ end of the mRNA through the action of the 4B helicase and ATP, the complex translocates 5′ → 3′ and scans the mRNA for a suitable initiation codon. Generally this is the 5′-most AUG, but the precise initiation codon is determined by so-called Kozak consensus sequences that surround the AUG:
![]()
Most preferred is the presence of a purine at positions –3 and +4 relative to the AUG.
Role of the Poly(A) Tail in Initiation
Biochemical and genetic experiments in yeast have revealed that the 3′ poly(A) tail and its binding protein, PAB1, are required for efficient initiation of protein synthesis. Further studies showed that the poly(A) tail stimulates recruitment of the 40S ribosomal subunit to the mRNA through a complex set of interactions. PAB1 (Figure 37–7), bound to the poly(A) tail, interacts with eIF-4G, and 4E subunit of eIF-4F that is bound to the cap. A circular structure is formed that helps direct the 40S ribosomal subunit to the 5′ end of the mRNA and also likely stabilizes mRNAs from exonucleotytic degradation. This helps explain how the cap and poly(A) tail structures have a synergistic effect on protein synthesis. Indeed, differential protein-protein interactions between general and specific mRNA translational repressors and eIF-4E result in m7GCap-dependent translation control (Figure 37–8).
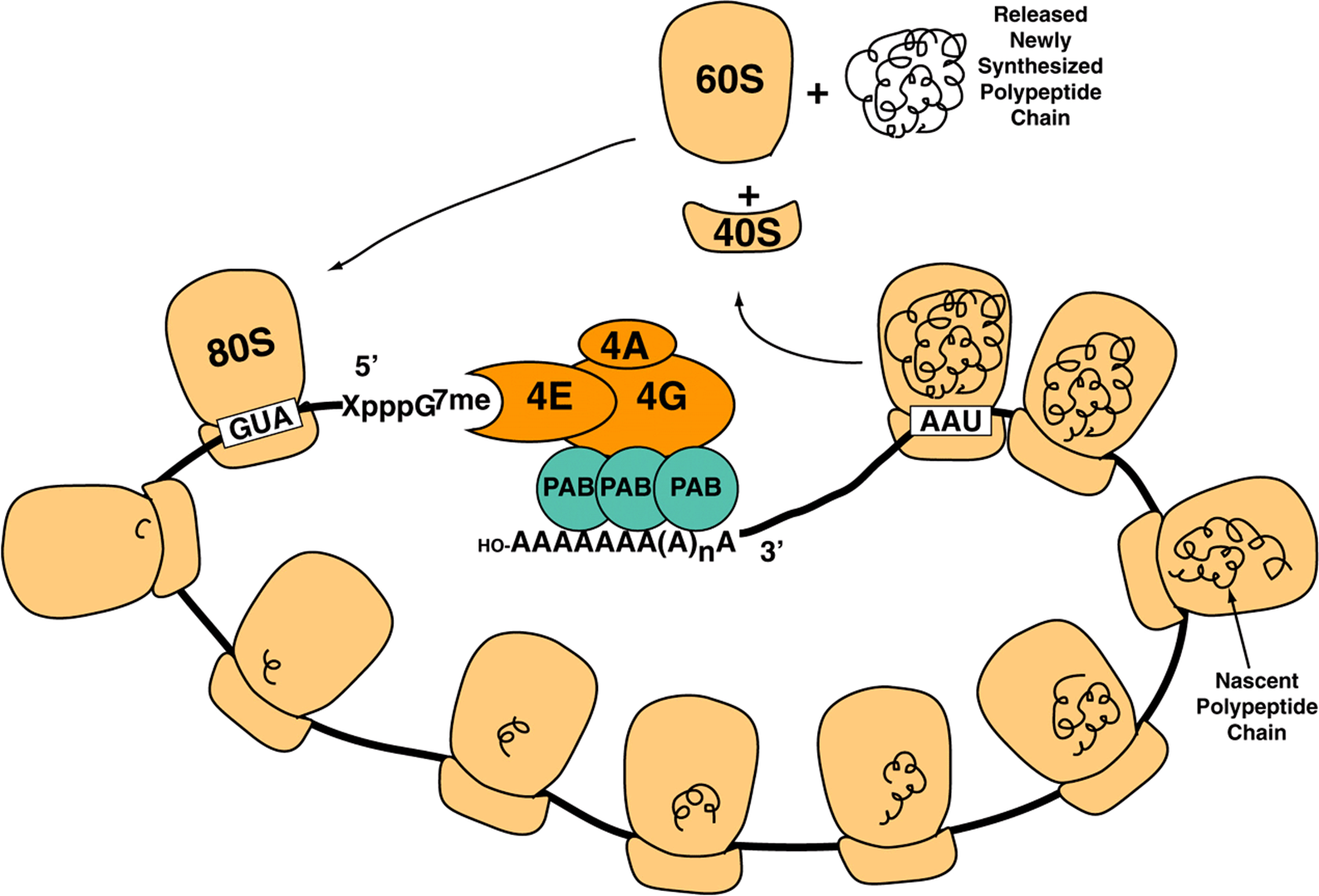
FIGURE 37–7 Schematic illustrating the circularization of mRNA through protein-protein interactions between m7G-bound elF4F and poly A tail-bound PolyA binding protein. elF4F, composed of elF4A, 4E, and 4G subunits binds the mRNA 5′-m7G “Cap” (-XpppG7me) upstream of the translation initiation codon (AUG) with high affinity. The elF4G subunit of the complex also binds poly A binding protein (PAB) with high affinity. Since PAB is bound tightly to the mRNA 3′-poly A tail (OH-AAAAAAA(A)nA), circularization results. Shown are multiple 80S ribosomes that are in the process of translating the circularized mRNA into protein (black curlicues), forming a polysome. Upon encountering a termination codon (UAA), translation termination occurs leading to release and dissociation of the 80S ribosome into 60S, 40S subunits and newly translated protein. Dissociated ribosomal subunits can recycle through another round of translation (see Figure 37–6).
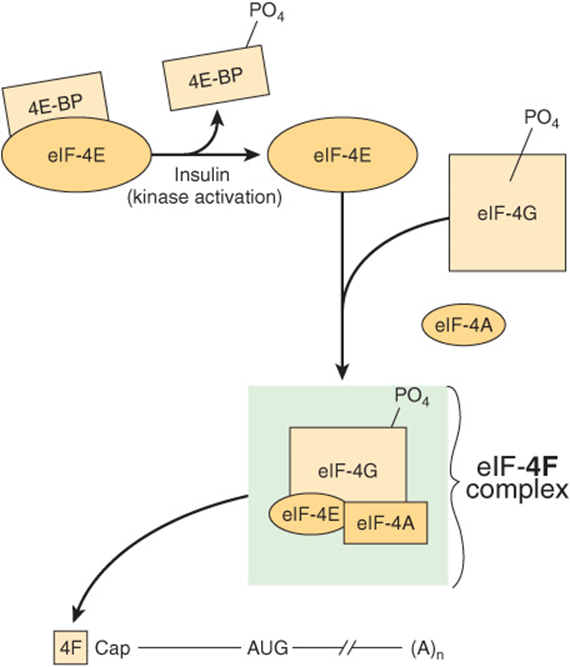
FIGURE 37–8 Activation of eIF-4E by insulin and formation of the cap binding eIF-4F complex. The 4F-cap mRNA complex is depicted as in Figures 37-6 and 37-7. The 4F complex consists of eIF-4E (4E), eIF-4A, and eIF-4G. 4E is inactive when bound by one of a family of binding proteins (4EBPs). Insulin and mitogenic factors (eg, IGF-1, PDGF, interleukin-2, and angiotensin II) activate the PI3 kinase/AKT kinase pathways, which activate the mTOR kinase, and results in the phosphorylation of 4E-BP (see Figure 42–8). Phosphorylated 4E-BP dissociates from 4E, and the latter is then able to form the 4F complex and bind to the mRNA cap. These growth polypeptides also induce phosphorylation of 4G itself by the mTOR and MAP kinase pathways. Phosphorylated 4F binds much more avidly to the cap than does nonphosphorylated 4F.
Formation of the 80S Initiation Complex
The binding of the 60S ribosomal subunit to the 48S initiation complex involves hydrolysis of the GTP bound to eIF-2 by eIF-5. This reaction results in release of the initiation factors bound to the 48S initiation complex (these factors then are recycled) and the rapid association of the 40S and 60S subunits to form the 80S ribosome. At this point, the met-tRNAi is on the P site of the ribosome, ready for the elongation cycle to commence.
The Regulation of eIF-4E Controls the Rate of Initiation
The 4F complex is particularly important in controlling the rate of protein translation. As described above, 4F is a complex consisting of 4E, which binds to the m7G cap structure at the 5′ end of the mRNA, and 4G, which serves as a scaffolding protein. In addition to binding 4E, 4G binds to eIF-3, which links the complex to the 40S ribosomal subunit. It also binds 4A and 4B, the ATPase-helicase complex that helps unwind the RNA (Figure 37–8).
4E is responsible for recognition of the mRNA cap structure, a rate-limiting step in translation. This process is further regulated by phosphorylation. Insulin and mitogenic growth factors result in the phosphorylation of 4E on ser 209 (or thr 210). Phosphorylated 4E binds to the cap much more avidly than does the nonphosphorylated form, thus enhancing the rate of initiation. Components of the MAP kinase, PI3K, mTOR, RAS, and S6 kinases pathways (see Figure 42–8) appear to be involved in these phosphorylation reactions.
The activity of 4E is regulated in a second way, and this also involves phosphorylation. A recently discovered set of proteins bind to and inactivate 4E. These proteins include 4EBP1 (BP1, also known as PHAS-1) and the closely related proteins 4E-BP2 and 4E-BP3. BP1 binds with high affinity to 4E. The [4E]•[BP1] association prevents 4E from binding to 4G (to form 4F). Since this interaction is essential for the binding of 4F to the ribosomal 40S subunit and for correctly positioning this on the capped mRNA, BP-1 effectively inhibits translation initiation.
Insulin and other growth factors result in the phosphorylation of BP-1 at seven unique sites. Phosphorylation of BP-1 results in its dissociation from 4E, and it cannot rebind until critical sites are dephosphorylated. These effects on the activation of 4E explain in part how insulin causes a marked posttranscriptional increase of protein synthesis in liver, adipose, and muscle tissue.
Elongation Is Also a Multistep, Accessory Factor-Facilitated Process
Elongation is a cyclic process on the ribosome in which one amino acid at a time is added to the nascent peptide chain (Figure 37–9). The peptide sequence is determined by the order of the codons in the mRNA. Elongation involves several steps catalyzed by proteins called elongation factors (EFs). These steps are (1) binding of aminoacyl-tRNA to the A site, (2) peptide bond formation, (3) translocation of the ribosome on the mRNA, and (4) expulsion of the deacylated tRNA from the P- and E-sites.
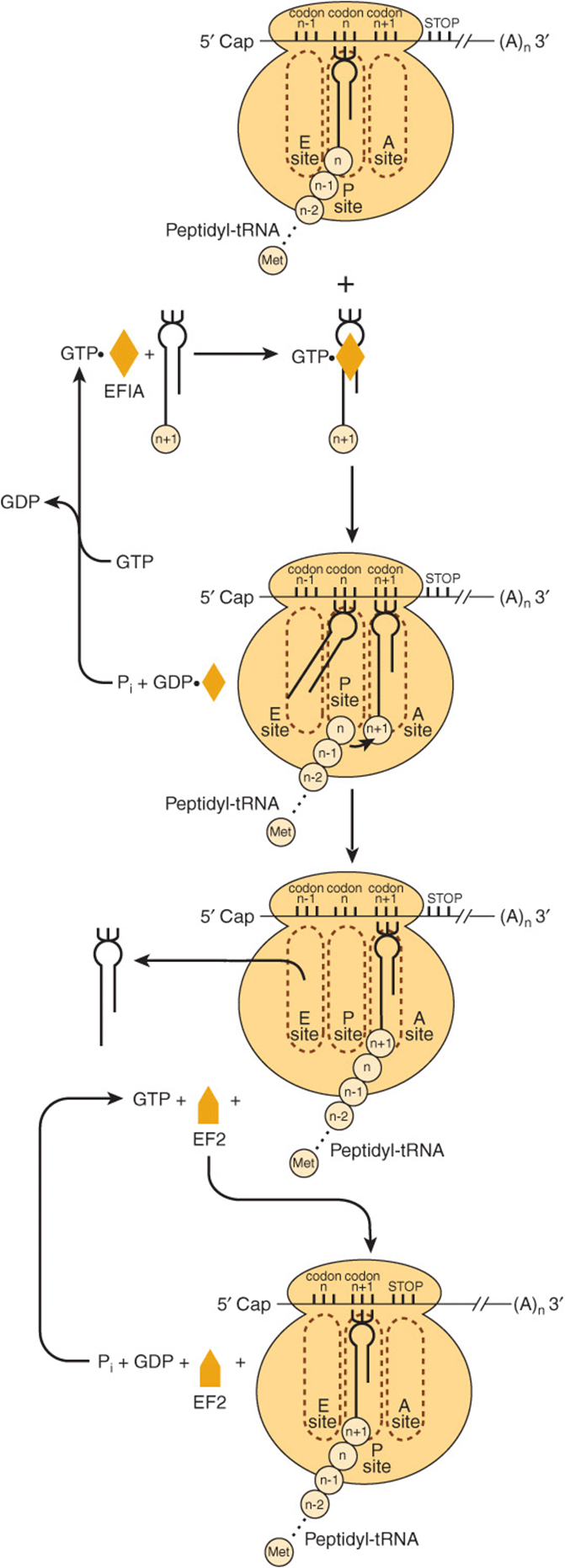
FIGURE 37–9 Diagrammatic representation of the peptide elongation process of protein synthesis. The small circles labeled n – 1, n, n + 1, etc., represent the amino acid residues of the newly formed protein molecule and corresponding codons in the mRNA. EFIA and EF2 represent elongation factors 1 and 2, respectively. The peptidyl-tRNA, aminoacyl-tRNA, and Exit sites on the ribosome are represented by P site, A site, and E site, respectively.
Binding of Aminoacyl-tRNA to the A Site
In the complete 80S ribosome formed during the process of initiation, both the A site (aminoacyl or acceptor site) and E site (deacylated tRNA exit site) are free. The binding of the appropriate aminoacyl-tRNA in the A site requires proper codon recognition. Elongation factor 1A (EF1A) forms a ternary complex with GTP and the entering aminoacyl-tRNA (Figure 37–9). This complex then allows the correct aminoacyl-tRNA to enter the A site with the release of EF1A•GDP and phosphate. GTP hydrolysis is catalyzed by an active site on the ribosome; hydrolysis induces a conformational change in the ribosome concomitantly increasing affinity for the tRNA. As shown in Figure 37–9, EF1A-GDP then recycles to EF1A-GTP with the aid of other soluble protein factors and GTP.
Peptide Bond Formation
The α-amino group of the new aminoacyl-tRNA in the A site carries out a nucleophilic attack on the esterified carboxyl group of the peptidyl-tRNA occupying the P site (peptidyl or polypeptide site). At initiation, this site is occupied by the initiator met-tRNA’. This reaction is catalyzed by a peptidyltransferase, a component of the 28S RNA of the 60S ribosomal subunit. This is another example of ribozyme activity and indicates an important—and previously unsuspected—direct role for RNA in protein synthesis (Table 37-3). Because the amino acid on the aminoacyl-tRNA is already “activated,” no further energy source is required for this reaction. The reaction results in attachment of the growing peptide chain to the tRNA in the A site.
TABLE 37–3 Evidence That rRNA Is A Peptidyltransferase

Translocation
The now deacylated tRNA is attached by its anticodon to the P site at one end and by the open CCA tail to an exit (E) site on the large ribosomal subunit (middle portion of Figure 37–9). At this point, elongation factor 2 (EF2)binds to and displaces the peptidyl tRNA from the A site to the P site. In turn, the deacylated tRNA is on the E site, from which it leaves the ribosome. The EF2-GTP complex is hydrolyzed to EF2-GDP, effectively moving the mRNA forward by one codon and leaving the A site open for occupancy by another ternary complex of amino acid tRNA-EF1AGTP and another cycle of elongation.
The charging of the tRNA molecule with the aminoacyl moiety requires the hydrolysis of an ATP to an AMP, equivalent to the hydrolysis of two ATPs to two ADPs and phosphates. The entry of the aminoacyl-tRNA into the A site results in the hydrolysis of one GTP to GDP. Translocation of the newly formed peptidyl-tRNA in the A site into the P site by EF2 similarly results in hydrolysis of GTP to GDP and phosphate. Thus, the energy requirements for the formation of one peptide bond include the equivalent of the hydrolysis of two ATP molecules to ADP and of two GTP molecules to GDP, or the hydrolysis of four high-energy phosphate bonds. A eukaryotic ribosome can incorporate as many as six amino acids per second; prokaryotic ribosomes incorporate as many as 18 per second. Thus, the energy requiring process of peptide synthesis occurs with great speed and accuracy until a termination codon is reached.
Termination Occurs When a Stop Codon Is Recognized
In comparison to initiation and elongation, termination is a relatively simple process (Figure 37–10). After multiple cycles of elongation culminating in polymerization of the specific amino acids into a protein molecule, the stop or terminating codon of mRNA (UAA, UAG, UGA) appears in the A site. Normally, there is no tRNA with an anticodon capable of recognizing such a termination signal. Releasing factor RF1 recognizes that a stop codon resides in the A site (Figure 37–10). RF1 is bound by a complex consisting of releasing factor RF3 with bound GTP. This complex, with the peptidyl transferase, promotes hydrolysis of the bond between the peptide and the tRNA occupying the P site. Thus, a water molecule rather than an amino acid is added. This hydrolysis releases the protein and the tRNA from the P site. Upon hydrolysis and release, the 80S ribosome dissociates into its 40S and 60S subunits, which are then recycled (Figure 37–7). Therefore, the releasing factors are proteins that hydrolyze the peptidyl-tRNA bond when a stop codon occupies the A site. The mRNA is then released from the ribosome, which dissociates into its component 40S and 60S subunits, and another cycle can be repeated.
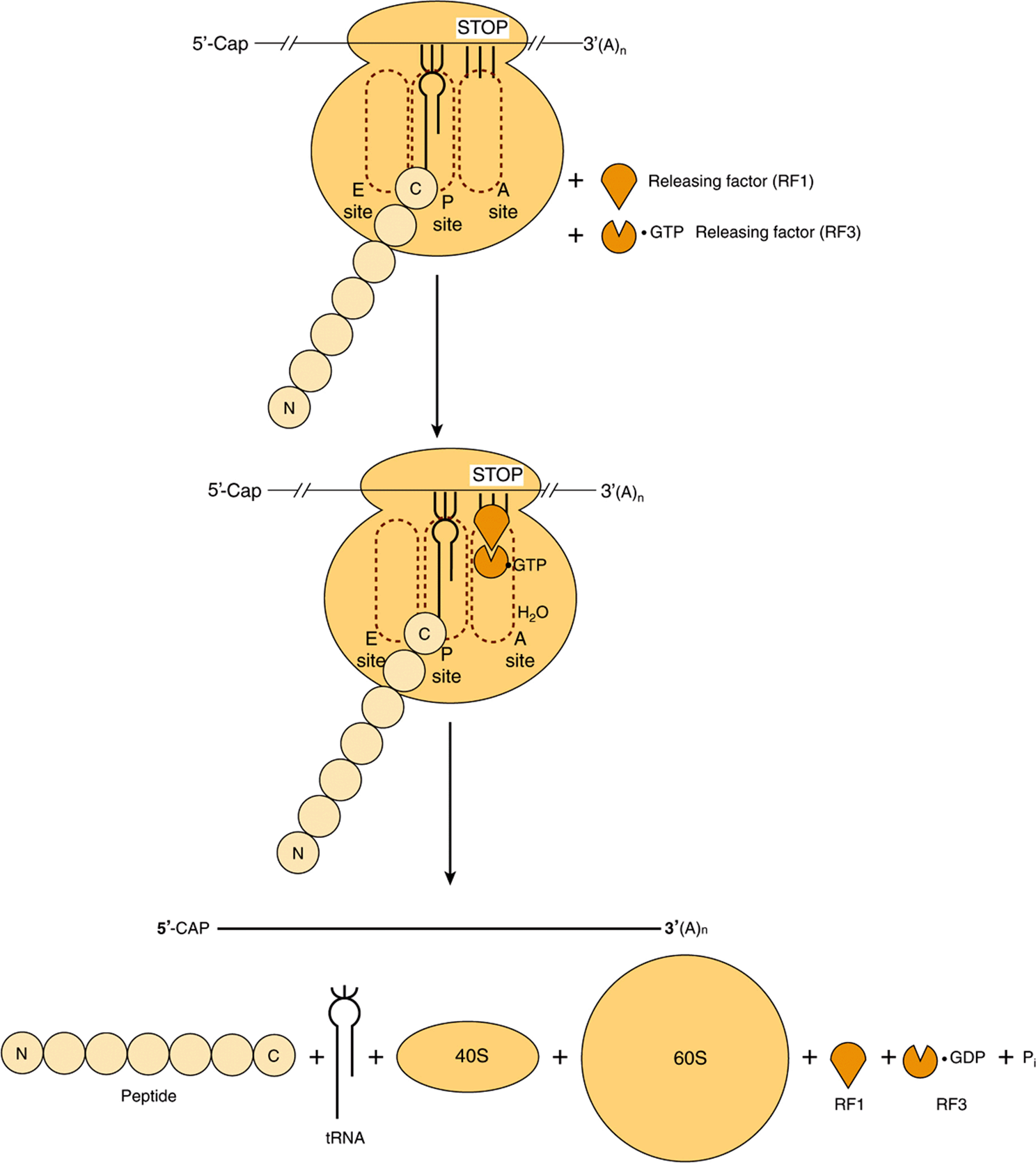
FIGURE 37–10 Diagrammatic representation of the termination process of protein synthesis. The peptidyl-tRNA, aminoacyl-tRNA and exit sites are indicated as P site, A site, and E site, respectively. The termination (stop) codon is indicated by the three vertical bars and stop. Releasing factor RF1 binds to the stop codon. Releasing factor RF3, with bound GTP, binds to RF1. Hydrolysis of the peptidyl-tRNA complex is shown by the entry of H2O. N and C indicate the amino and carboxyl terminal amino acids of the nascent polypeptide chain, respectively, and illustrate the polarity of protein synthesis.
Polysomes Are Assemblies of Ribosomes
Many ribosomes can translate the same mRNA molecule simultaneously. Because of their relatively large size, the ribosome particles cannot attach to an mRNA any closer than 35 nucleotides apart. Multiple ribosomes on the same mRNA molecule form a polyribosome, or “polysome” (Figure 37–7). In an unrestricted system, the number of ribosomes attached to an mRNA (and thus the size of polyribosomes) correlates positively with the length of the mRNA molecule.
Polyribosomes actively synthesizing proteins can exist as free particles in the cellular cytoplasm or may be attached to sheets of membranous cytoplasmic material referred to as endoplasmic reticulum. Attachment of the particulate polyribosomes to the endoplasmic reticulum is responsible for its “rough” appearance as seen by electron microscopy. The proteins synthesized by the attached polyribosomes are extruded into the cisternal space between the sheets of rough endoplasmic reticulum and are exported from there. Some of the protein products of the rough endoplasmic reticulum are packaged by the Golgi apparatus for eventual export (see Chapter 46). The polyribosomal particles free in the cytosol are responsible for the synthesis of proteins required for intracellular functions.
Nontranslating mRNAs Can Form Ribonucleoprotein Particles That Accumulate in Cytoplasmic Organelles Termed P Bodies
mRNAs, bound by specific packaging proteins and exported from the nucleus as ribonucleoproteins particles (RNPs) sometimes do not immediately associate with ribosomes to be translated. Instead, specific mRNAs can associate with the protein constituents that form P bodies, small dense compartments that incorporate mRNAs as mRNPs (Figure 37–11). These cytoplasmic organelles are related to similar small mRNA-containing granules found in neurons and certain maternal cells. P bodies are sites of translation repression and mRNA decay. Over 35 distinct proteins have been suggested to reside exclusively or extensively within P bodies. These proteins range from mRNA decapping enzymes, RNA helicases and RNA exonucleases (5’-3’ and 3′-5’), to components involved in miRNA function and mRNA quality control. However, incorporation of an mRNP is not an unequivocal mRNA “death sentence.” Indeed, though the mechanisms are not yet fully understood, certain mRNAs appear to be temporarily stored in P bodies and then retrieved and utilized for protein translation. This suggests that an equilibrium exists where the cytoplasmic functions of mRNA (translation and degradation) are controlled by the dynamic interaction of mRNA with polysomes and P bodies.
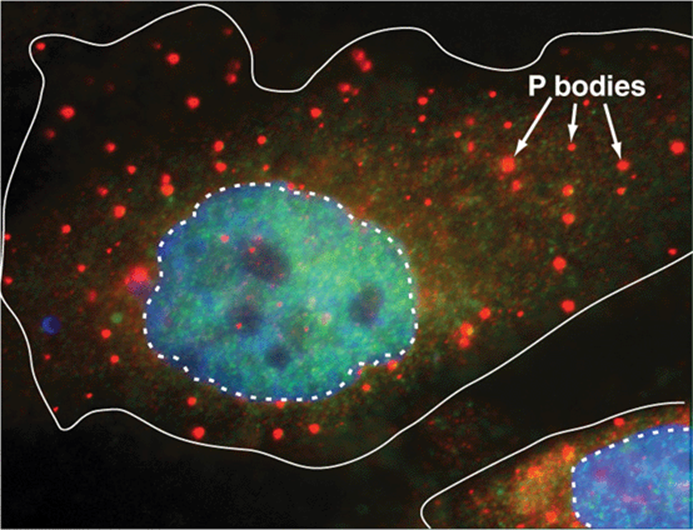
FIGURE 37–11 The P body is a cytoplasmic organelle that modulates mRNA metabolism. Shown is a photomicrograph of two mammalian cells in which a single distinct protein constituent of the P body has been visualized using the cognate specific fluorescently labeled antibody. P bodies appear as light circles of varying size throughout the cytoplasm. Cell membranes indicated by a solid white line, nuclei by a dashed line. Nuclei were counterstained using a fluorescent dye with different fluorescence excitation/emission spectra from the labeled antibody used to identify P bodies; the nuclear stain intercalates between the DNA base pairs. Modified from http://www.mcb.arizona.edu/parker/WHAT/what.htm. (Used with permission of Dr Roy Parker.)
The Machinery of Protein Synthesis Can Respond to Environmental Threats
Ferritin, an iron-binding protein, prevents ionized iron (Fe2+) from reaching toxic levels within cells. Elemental iron stimulates ferritin synthesis by causing the release of a cytoplasmic protein that binds to a specific region in the 5′ nontranslated region of ferritin mRNA. Disruption of this protein-mRNA interaction activates ferritin mRNA and results in its translation. This mechanism provides for rapid control of the synthesis of a protein that sequesters Fe2+, a potentially toxic molecule. Similarly environmental stress and starvation inhibit the positive roles of mTOR (Figure 37–8; Figure 42–8) on promoting activation of eIF4F and 48S complex formation.
Many Viruses Co-Opt the Host Cell Protein Synthesis Machinery
The protein synthesis machinery can also be modified in deleterious ways. Viruses replicate by using host cell processes, including those involved in protein synthesis. Some viral mRNAs are translated much more efficiently than those of the host cell (eg, encephalomyocarditis virus). Others, such as reovirus and vesicular stomatitis virus, replicate efficiently, and thus their very abundant mRNAs have a competitive advantage over host cell mRNAs for limited translation factors. Other viruses inhibit host cell protein synthesis by preventing the association of mRNA with the 40S ribosome.
Poliovirus and other picornaviruses gain a selective advantage by disrupting the function of the 4F complex. The mRNAs of these viruses do not have a cap structure to direct the binding of the 40S ribosomal subunit (see above). Instead, the 40S ribosomal subunit contacts an internal ribosomal entry site (IRES) in a reaction that requires 4G but not 4E. The virus gains a selective advantage by having a protease that attacks 4G and removes the amino terminal 4E binding site. Now the 4E-4G complex (4F) cannot form, so the 40S ribosomal subunit cannot be directed to capped mRNAs. Host cell translation is thus abolished. The 4G fragment can direct binding of the 40S ribosomal subunit to IRES-containing mRNAs, so viral mRNA translation is very efficient (Figure 37–12). These viruses also promote the dephosphorylation of BP1 (PHAS-1), thereby decreasing cap (4E)-dependent translation (Figure 37–8).
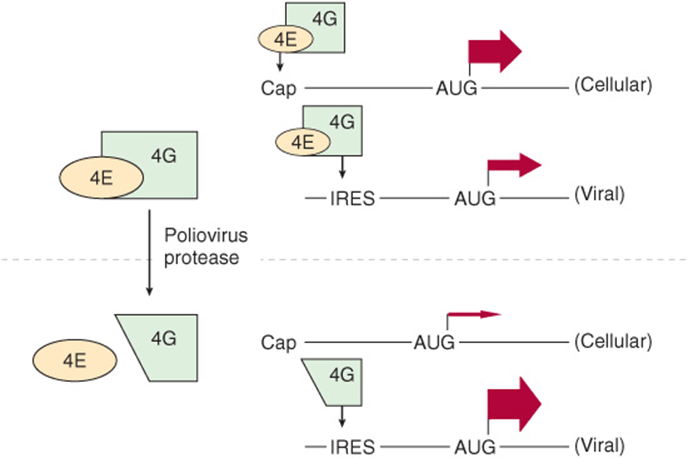
FIGURE 37–12 Picornaviruses disrupt the 4F complex. The 4E-4G complex (4F) directs the 40S ribosomal subunit to the typical capped mRNA (see text). 4G alone is sufficient for targeting the 40S subunit to the internal ribosomal entry site (IRES) of viral mRNAs. To gain selective advantage, certain viruses (eg, poliovirus) express a protease that cleaves the 4E binding site from the amino terminal end of 4G. This truncated 4G can direct the 40S ribosomal subunit to mRNAs that have an IRES but not to those that have a cap. The widths of the arrows indicate the rate of translation initiation from the AUG codon in each example. Other viruses utilize distinct processes to effect selective initiation of translation on their cognate viral mRNAs via IRES elements.
POSTTRANSLATIONAL PROCESSING AFFECTS THE ACTIVITY OF MANY PROTEINS
Some animal viruses, notably HIV, poliovirus, and hepatitis A virus, synthesize long polycistronic proteins from one long mRNA molecule. The protein molecules translated from these long mRNAs are subsequently cleaved at specific sites to provide the several specific proteins required for viral function. In animal cells, many cellular proteins are synthesized from the mRNA template as a precursor molecule, which then must be modified to achieve the active protein. The prototype is insulin, which is a small protein having two polypeptide chains with interchain and intrachain disulfide bridges. The molecule is synthesized as a single chain precursor, or prohormone, which folds to allow the disulfide bridges to form. A specific protease then clips out the segment that connects the two chains which form the functional insulin molecule (see Figure 41–12).
Many other peptides are synthesized as proproteins that require modifications before attaining biologic activity. Many of the posttranslational modifications involve the removal of amino terminal amino acid residues by specific aminopeptidases. Collagen, an abundant protein in the extracellular spaces of higher eukaryotes, is synthesized as procollagen. Three procollagen polypeptide molecules, frequently not identical in sequence, align themselves in a particular way that is dependent upon the existence of specific amino terminal peptides (Figure 5–11). Specific enzymes then carry out hydroxylations and oxidations of specific amino acid residues within the procollagen molecules to provide cross-links for greater stability. Amino terminal peptides are cleaved off the molecule to form the final product—a strong, insoluble collagen molecule. Many other posttranslational modifications of proteins occur. Covalent modification by acetylation, phosphorylation, methylation, ubiquitylation, and glycosylation is common, for example (ie, Chapter 5; Table 35-1).
MANY ANTIBIOTICS WORK BY SELECTIVELY INHIBITING PROTEIN SYNTHESIS IN BACTERIA
Ribosomes in bacteria and in the mitochondria of higher eukaryotic cells differ from the mammalian ribosome described in Chapter 34. The bacterial ribosome is smaller (70S rather than 80S) and has a different, somewhat simpler complement of RNA and protein molecules. This difference can be exploited for clinical purposes because many effective antibiotics interact specifically with the proteins and RNAs of prokaryotic ribosomes and thus only inhibit bacterial protein synthesis. This results in growth arrest or death of the bacterium. The most useful members of this class of antibiotics (eg, tetracyclines, lincomycin, erythromycin, and chloramphenicol) do not interact with components of eukaryotic ribosomes and thus are not toxic to eukaryotes. Tetracycline prevents the binding of aminoacyl-tRNAs to the bacterial ribosome A site. Chloramphenicol and the macrolide class of antibiotics work by binding to 23S rRNA, which is interesting in view of the newly appreciated role of rRNA in peptide bond formation through its peptidyltransferase activity. It should be mentioned that the close similarity between prokaryotic and mitochondrial ribosomes can lead to complications in the use of some antibiotics.
Other antibiotics inhibit protein synthesis on all ribosomes (puromycin) or only on those of eukaryotic cells (cycloheximide). Puromycin (Figure 37–13) is a structural analog of tyrosinyl-tRNA. Puromycin is incorporated via the A site on the ribosome into the carboxyl terminal position of a peptide but causes the premature release of the polypeptide. Puromycin, as a tyrosinyl-tRNA analog, effectively inhibits protein synthesis in both prokaryotes and eukaryotes. Cycloheximide inhibits peptidyltransferase in the 60S ribosomal subunit in eukaryotes, presumably by binding to an rRNA component.
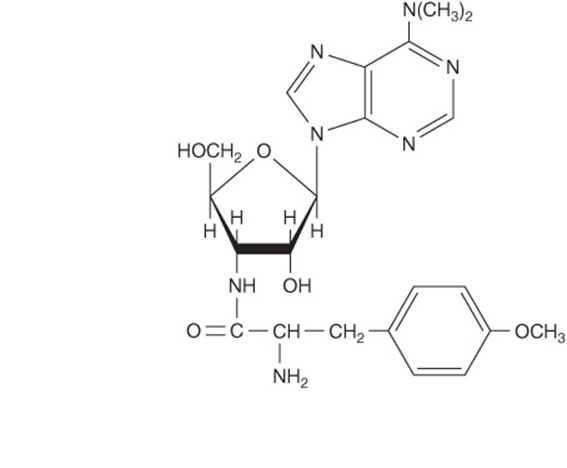
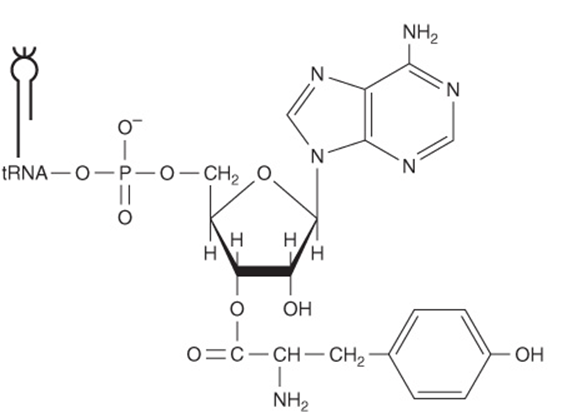
FIGURE 37–13 The comparative structures of the antibiotic puromycin (top) and the 3′ terminal portion of tyrosinyl-tRNA (bottom).
Diphtheria toxin, an exotoxin of Corynebacterium diphtheriae infected with a specific lysogenic phage, catalyzes the ADP-ribosylation of EF-2 on the unique amino acid diphthamide in mammalian cells. This modification inactivates EF-2 and thereby specifically inhibits mammalian protein synthesis. Many animals (eg, mice) are resistant to diphtheria toxin. This resistance is due to inability of diphtheria toxin to cross the cell membrane rather than to insensitivity of mouse EF-2 to diphtheria toxin-catalyzed ADP-ribosylation by NAD.
Ricin, an extremely toxic molecule isolated from the castor bean, inactivates eukaryotic 28S ribosomal RNA by providing the N-glycolytic cleavage or removal of a single adenine.
Many of these compounds—puromycin and cycloheximide in particular—are not clinically useful but have been important in elucidating the role of protein synthesis in the regulation of metabolic processes, particularly enzyme induction by hormones.
SUMMARY
![]() The flow of genetic information follows the sequence DNA → RNA → protein.
The flow of genetic information follows the sequence DNA → RNA → protein.
![]() The genetic information in the structural region of a gene is transcribed into an RNA molecule such that the sequence of the latter is complementary to that in one strand of the DNA.
The genetic information in the structural region of a gene is transcribed into an RNA molecule such that the sequence of the latter is complementary to that in one strand of the DNA.
![]() Ribosomal RNA (rRNA), transfer RNA (tRNA), and messenger RNA (mRNA), are directly involved in protein synthesis.
Ribosomal RNA (rRNA), transfer RNA (tRNA), and messenger RNA (mRNA), are directly involved in protein synthesis.
![]() miRNAs regulate mRNA function at the level of translation and/or stability.
miRNAs regulate mRNA function at the level of translation and/or stability.
![]() The information in mRNA is in a tandem array of codons, each of which is three nucleotides long.
The information in mRNA is in a tandem array of codons, each of which is three nucleotides long.
![]() The mRNA is read continuously from a start codon (AUG) to a termination codon (UAA, UAG, UGA).
The mRNA is read continuously from a start codon (AUG) to a termination codon (UAA, UAG, UGA).
![]() The open reading frame, or ORF, of the mRNA is the series of codons, each specifying a certain amino acid, that determines the precise amino acid sequence of the protein.
The open reading frame, or ORF, of the mRNA is the series of codons, each specifying a certain amino acid, that determines the precise amino acid sequence of the protein.
![]() Protein synthesis, like DNA and RNA synthesis, follows the 5′-3’ polarity of mRNA and can be divided into three processes: initiation, elongation, and termination.
Protein synthesis, like DNA and RNA synthesis, follows the 5′-3’ polarity of mRNA and can be divided into three processes: initiation, elongation, and termination.
![]() Mutant proteins arise when single-base substitutions result in codons that specify a different amino acid at a given position, when a stop codon results in a truncated protein, or when base additions or deletions alter the reading frame, so different codons are read.
Mutant proteins arise when single-base substitutions result in codons that specify a different amino acid at a given position, when a stop codon results in a truncated protein, or when base additions or deletions alter the reading frame, so different codons are read.
![]() A variety of compounds, including several antibiotics, inhibit protein synthesis by affecting one or more of the steps involved in protein synthesis.
A variety of compounds, including several antibiotics, inhibit protein synthesis by affecting one or more of the steps involved in protein synthesis.
REFERENCES
Altmann M, Linder P: Power of yeast for analysis of eukaryotic translation initiation. J Biol Chem 2010;285:31907-13192.
Beckham CJ, Parker R: P bodies, stress granules, and viral life cycles. Cell Host Microbe 2008;3:206.
Buchan JR, Parker R: Eukaryotic stress granules: the ins and outs of translation. Mol Cell 2009;36:932-941.
Crick FH, Barnett L, Brenner S, et al: The genetic code. Nature 1961;192:1227.
Hinnebusch AG: Molecular Mechanism of Scanning and Start Codon Selection in Eukaryotes. Microbiology & Molecular Biology Reviews 2011;75:434-467.
Kimball SR, Jefferson, LS: Control of translation initiation through integration of signals generated by hormones, nutrients, and exercise. J Biol Chem 2009;285:29027-29032.
Kozak M: Structural features in eukaryotic mRNAs that modulate the initiation of translation. J Biol Chem 1991;266:1986.
Liu CC, Schultz PG: Adding new chemistries to the genetic code. Annu Rev Biochem 2010;79:413-444.
Maquat LE, Tarn WY, Isken O: The pioneer round of translation: features and functions. Cell 2010;142:368-374.
Silvera D, Formenti SC, Schneider RJ: Translational control in cancer. Nat Rev Cancer 2010;10:254-266.
Sonenberg N, Hinnebusch AG: Regulation of translation initiation in eukaryotes: mechanisms and biological targets. Cell 2010;136:731-745.
Spriggs KA, Bushell M, Willis AE: Translational regulation of gene expression during conditions of cell stress. Mol Cell 2010;40:228-237.
Steitz TA, Moore PB: RNA, the first macromolecular catalyst: the ribosome is a ribozyme. Trends Biochem Sci 2003;28:411.
Wang Q, Parrish AR, Wang L: Expanding the genetic code for biological studies. Chem Biol 2009;16:323-336.
Weatherall DJ: Phenotype-genotype relationships in mogenic disease: Lessons from the thalassaemias. Nature Reviews Genetics 2001;2:245.